OpenAIは世界最大規模のAI「GPT-3」を公開した。GPT-3は言葉を生成するAIであるが、数少ない事例で言語能力を習得することができる。また、GPT-3は文章を生成するだけでなく、翻訳や質疑応答や文法の間違いの修正など、多彩な機能を習得する。AIの規模を大きくすることで、人間のように少ない事例で学習し、多彩な言語能力を身につけた。

| 出典: OpenAI |
GPT-3の概要
OpenAIはGPT-3について論文「Language Models are Few-Shot Learners」で、その機能と性能を明らかにした。GPT-3は世界最大規模のAIで1750億個のパラメータから構成される。GPT-3は言語モデル(autoregressive language model)で、入力された言葉に続く言葉を推測する機能を持つ。多くの言語モデルが開発されているが、GPT-3の特徴は少ない事例で学習できる能力で、これは「Few-Shot Learning」と呼ばれる。
Few-Shot Learningとは
Few-Shot LearningとはAIが数少ない事例で学習するモデルを指す。例えば、英語をフランス語に翻訳する事例を三つ示すと、AIは英仏翻訳ができるようになる(下の写真左側)。これを進めると、一つの事例で機能を習得し、これは「One-Shot Learning」と呼ばれる。究極のモデルは、事例を示すことなく言葉で指示するだけでAIが英仏翻訳を実行する。これは「Zero-Shot Learning」と呼ばれる。GPT-3はこれらの技法を獲得することが研究テーマとなる。

| 出典: Tom B. Brown et al. |
GPT-3はアルゴリズム最適化が不要なモデル
これは、GPT-3は最適化教育(Fine-Tuning)を必要とせず、基礎教育(Pre-Training)だけで学習できることを意味する。通常、言語モデルは基礎教育を実施し、次に、適用する問題に応じてAIを最適化する。例えば、英語を仏語に翻訳するAIを開発するには、まず基礎教育を実施し、次に、英語と仏語のデータを使いモデルを最適化する(上の写真右側)。GPT-3はこのプロセスは不要で、基礎教育だけで英語を仏語に翻訳できる。
GPT-3の異なるモデル
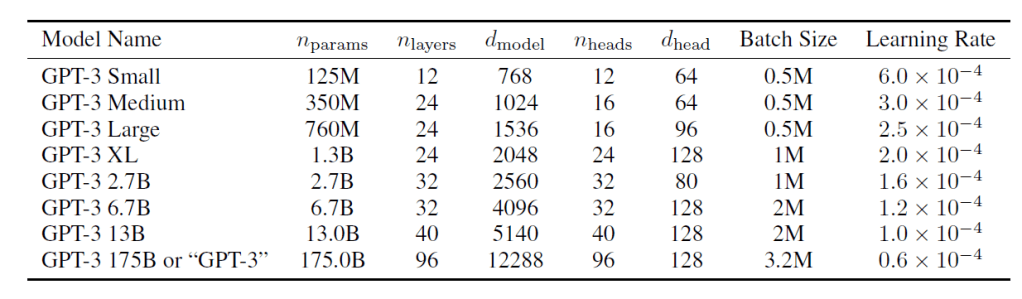
GPT-3は「Transformer」というニューラルネットワークから構成される言語モデルである。Transformerとは2017年にGoogleが発表したアーキテクチャで、従来モデル(recurrent neural networks)を簡素化し、性能が大幅に向上した。GPT-3はニューラルネットワークのサイズと性能の関係を検証するために8つのモデルが生成された(下のテーブル)。最大構成のシステムが「GPT-3」と呼ばれ、1750憶個のパラメータで構成される。
| 出典: Tom B. Brown et al. |
教育データ
GPT-3の基礎教育では大量のテキストデータが使われた。その多くがウェブサイトのデータをスクレイピングしたもので、Common Crawlと呼ばれるデータベースに格納されている情報が利用された。この他にデジタル化された書籍やウィキペディアも使われた。つまり、GPT-3はインターネット上の情報で教育されたAIとなる。
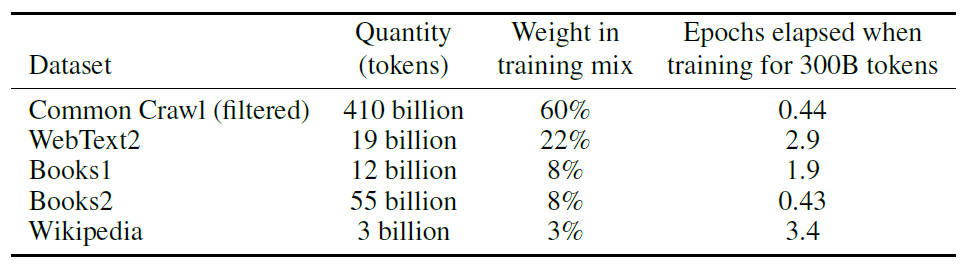
| 出典: Tom B. Brown et al. |
GPT-3は多彩な機能を習得
開発されたGPT-3は多彩な言語能力を習得した。GPT-3は自然言語解析に強く、文章の生成だけでなく、言語翻訳、質疑応答、文章の穴埋め(cloze tasks)を実行できる。また、因果関係を把握する(Reasoning)機能、文字の並べ替え(unscrambling words)、3桁の計算を実行する能力がある。 (下の写真、GPT-3が文法の間違いを修正する機能。文法の間違い(灰色の部分)を修正し正しい文章(黒色の部分)を生成する。)

| 出典: Tom B. Brown et al. |
GPT-3の機能の限界
GPT-3が生成する文章の品質は極めて高く、恐ろしいほど人間の文章に近く、社会に衝撃を与えた。同時に、この研究で、GPT-3は多くの課題があることも明らかになった。また、AI研究者からもGPT-3の問題点が指摘された。
文法は正しいが違和感を感じる
GPT-3は高品質な記事を生成するが、しばしば稚拙な文章を生成する。例えば、GPT-3は同じ意味の記述を繰り返し、趣旨一貫しない記事も多い。また、結論が矛盾していることも少なくない。特に、推論においてはGPT-3は人間のような常識を持っておらず、社会通念に反した文章を生成する。

| 出典: Tom B. Brown et al. |
(上の写真:灰色の部分が人間の入力で、GPT-3はそれに続く文章を生成(黒字の部分)。人間が「映画スターJoaquin Phoenixは授賞式で同じタキシードを着ると約束した」という内容で記事を書くよう指示すると、GPT-3は「Phoenixはハリウッドの慣習を破った」という内容の記事を生成した。しかし、言葉の繰り返しが目立ち、意味は通じるが、稚拙な文章でしっくりしない。)
物理現象の常識
GPT-3は物理現象の常識(common sense physics)が欠けている。このため、「冷蔵庫にチーズを入れると溶けるか?」という質問にGPT-3は正しく回答できない。また、「2021年のワールドシリーズは誰が勝った?」という質問にはGPT-3は「ニューヨーク・ヤンキース」と答える(下の写真)。GPT-3は日常社会の基本的な概念を持たず、人間とは本質的に異なる。

| 出典: Kevin Lacker |
社会のしきたり
GPT-3は人間社会の慣習や常識についての知識を持っていない。人間が「弁護士がスーツのズボンが汚れているのに気付いた。しかし弁護士はお洒落な水着を持っている。」と入力すると(下の写真)、GPT-3は「弁護士は水着を着て裁判所に行った」という文章を生成(太字の部分)。GPT-3は社会の常識が無く、弁護士が水着で裁判所に行くことはない、という社会通念を理解していない。

| 出典: Gary Marcus |
課題1:言語モデルの教育方法
GPT-3はネット上のテキストだけで教育され知識を取得した。一方、人間はテキストを読んで学習することに加え、テレビやビデオで情報を得る。それ以前に、人間は日常生活で人と交わり、交流を通じて社会の常識を得る。言語モデルはテキストだけで教育すると限界に達し、これ以外のメディア(ビデオや実社会との交流など)による教育が次のステップとなる。
課題2:学習効率
GPT-3の特徴はFew-Shot Learningで、人間のように少ない事例でタスクを実行できる。しかし、GPT-3は基礎教育の課程で人間が学習するより多くのデータで教育された。GPT-3は数十億ページのドキュメントで学習したが、人間はこれほど大量の書物を読まなくても言葉を習得できる。つまり、言語モデルの教育では人間のように効率的に学習することが課題となる。このためには、教育データの範囲を広げること (実社会のデータなど)や、アルゴリズムの改良が次の研究テーマとなる。
否定的な見解
この研究ではGPT-3のサイズを大きくすると、言語能力が向上することが示された。では、GPT-3のニューラルネットワークを更に巨大にすると、人間のようなインテリジェンスを獲得できるかが議論となっている。ニューヨーク大学(New York University)名誉教授Gary Marcusはこれに対し否定的で、サイズを大きくしても機能は改良されないと表明している。GPT-3は学習した言葉を繋ぎ合わせているだけで、文法は完璧だが、その意味を理解しているわけでないと説明する。
人間に近づけるか
OpenAIは論文の中で、GPT-3が言葉の意味を理解することが課題で、次のステップとして、アルゴリズムを人間のように教育する構想を示している。AIが社会に出て、人と交わり、経験を積むことで、言葉とその意味の関係(Grounding)を学習する。この手法でAIがどこまで人間に近づけるのか、これからの研究に期待が寄せられている。
【GPT-3の多彩な機能とベンチマーク結果】
穴埋め問題
GPT-3は文章を読んで最後の単語を予測する機能を持つ(下の写真)。これは「LAMBADA」といわれるタスクで、言語モデルの長期依存機能(言葉を覚えている機能)をベンチマークする。物語が展開され(下の事例では暗闇の中で岩に階段が刻まれている)、それを読み進め、GPT-3が最後の単語を推定する(正解は階段)。GPT-3の正解率は86.4%で業界トップの成績をマークした。

| 出典: Tom B. Brown et al. |
知識を検証する
GPT-3は幅広い知識を持っており、言語モデルの知識を検証する試験(Closed Book Question Answering)で好成績をマークした。これは「TriviaQA」と呼ばれ、言語モデルがテキストを読み質問に回答する(下の写真)。ここでは一般知識に関する幅広い質問が出され、言語モデルの知識の量を検証する。(下の事例、「Nude Descending a Staircase(階段を下りるヌード)」という絵画の制作者を問う問題。正解はMarcel Duchampであるが表記法は下記の通り複数ある。)
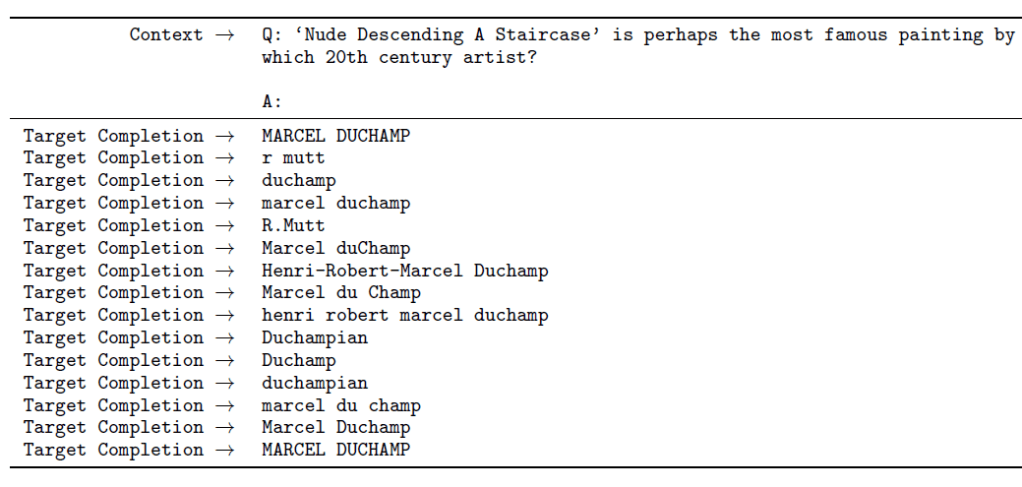
| 出典: Tom B. Brown et al. |
このケースではGPT-3の正解率は71.2%(Few-Shot Learning)をマークした。このベンチマークでは、GPT-3のサイズが大きくなるにつれ、正解率が向上していることが示された(下のグラフ)。つまり、ニューラルネットワークの規模が大きくなるにつれ、知識を吸収する技量が向上することが証明された。
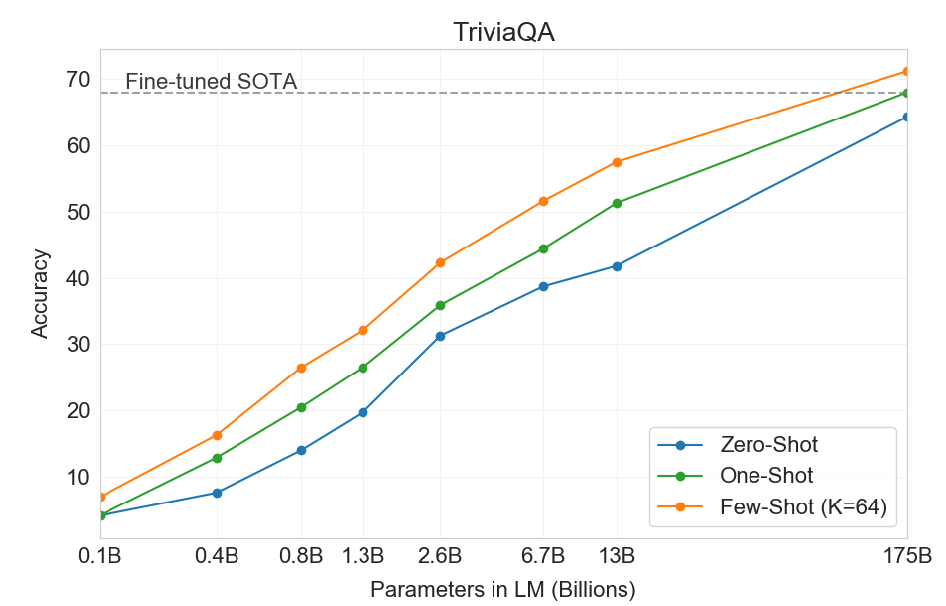
| 出典: Tom B. Brown et al. |
文章生成
GPT-3は人間のように文章を生成するが、その性能を検証するベンチマーク(News Article Generation)が実施された(下の写真)。GPT-3が生成した記事を人間が読んで、マシンが生成したものであることを見分ける試験。その結果、最大モデルの検知率は52%で、GPT-3が生成する文章の半数は人間が真偽を判定できないことを示している。このケースでもGPT-3のサイズが大きくなるにつれ、フェイクニュースの技量が向上していることが分かる。
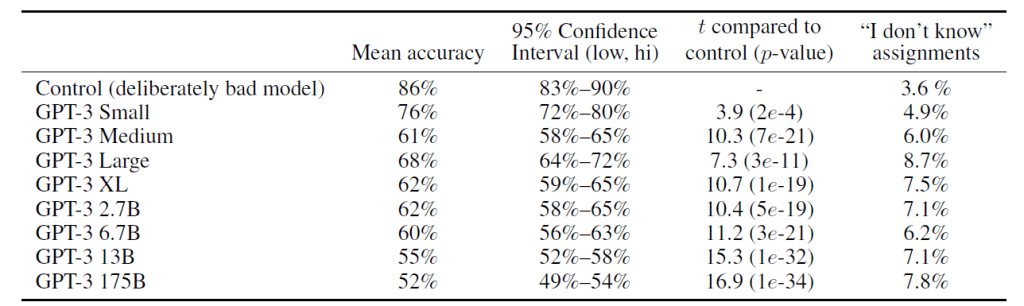
| 出典: Tom B. Brown et al. |