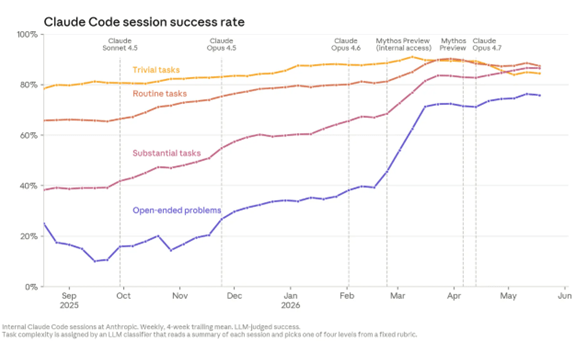
OpenAIは最新フロンティアモデル「GPT-5.6」シリーズを公開したが、トランプ政権の要請を受け、特定団体に限定的にリリースすることを発表した。GPT-5.6のハイエンドモデル「GPT-5.6 Sol」はAnthropicの「Claude Mythos 5」の性能を上回り、OpenAIが業界トップの座を奪還した。トランプ政権はAI開発を推進する政策を展開してきたが、AIモデルのサイバー攻撃能力が急進し、AIモデルの出荷を厳しく管理する方向に大転換した。

| 出典: OpenAI |
GPT-5.6シリーズ
OpenAIは6月26日、フロンティアモデル「GPT-5.6」を発表した。GPT-5.6は最先端モデルで、特に、コーディング、バイオロジー、サイバーセキュリティ、エージェント機能が強化された。GPT-5.6シリーズは三つのモデルから構成される(下の写真、イメージ)。
- GPT-5.6 Sol:フラッグシップモデルで最も高度な機能を持つ
- GPT-5.6 Terra:バランスの取れたモデルで日々の業務で使われる、GPT-5.5レベルの性能を低価格で提供する
- GPT-5.6 Luna:高速で稼働するモデルを低価格で提供
因みに、「Sol」、「Terra」、「Luna」はラテン語で「太陽」、「地球」、「月」を表す(上の写真)。GPT-5.6シリーズは惑星をモチーフとしたネーミングとなった。

| 出典: Generated with OpenAI GPT-5.5 |
GPT-5.6 Solが業界トップの性能をマーク
OpenAIはGPT-5.6シリーズのベンチマークテスト結果を公開し、Anthropicのモデルを追い抜き、業界でトップの性能をマークしたとアピールした(下のグラフ)。コーディングのワークフローの性能を測定するベンチマークテスト「Terminal‑Bench 2.1」で、GPT-5.6 SolはAnthropicのフラッグシップモデル「Claude Mythos 5」の性能を追い越した。また、GPT-5.6 Solを強化したモデル「GPT-5.6 Sol Ultra」はMythos 5の性能を圧倒的に上回った。GPT-5.6 Sol Ultraは複数のエージェントが共同でタスクを実行するモデルとなる。
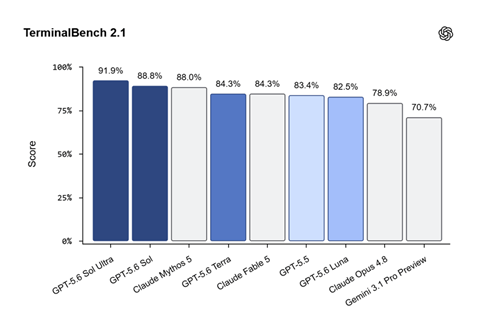
| 出典: OpenAI |
GPT-5.6シリーズは限定公開
OpenAIは当面はGPT‑5.6 Sol, Terra, Lunaを特定団体に限定的に公開する指針を取る。その後、数週間以内に、これらモデルを一般にリリースすることを明らかにした。OpenAIは発表に先立ち、トランプ政権とGPT-5.6シリーズのリリース計画や機能について協議を重ねてきた。その結果、トランプ政権の要請で、GPT-5.6シリーズを信頼できる団体に限定してリリースすることとした。これら信頼できる団体については政権が許可したものとなる。限定リリースの期間内に、OpenAIはこれら特定団体とGPT-5.6シリーズの機能を検証し安全性を評価する作業を実行する。
連邦政府とOpenAIのコラボレーション
OpenAIはこの限定リリースの仕組みは暫定的な措置で、これから長期間にわたり続くものではないと公表した。限定リリースにより、企業や開発者やグローバルパートナーはフロンティアモデルを使うことができず、ビジネスや研究開発への影響は甚大である。このため、OpenAIはトランプ政権と共同でサイバー大統領令「Cyber Executive Order」の枠組みの開発を進めている。サイバー大統領令とは、サイバーセキュリティ機能が格段に強化されたフロンティアモデルを管理するフレームワークで、安全試験のプロセスやモデルリリースのルールが規定される。(下の写真、連邦政府とOpenAIのコラボレーションのイメージ)
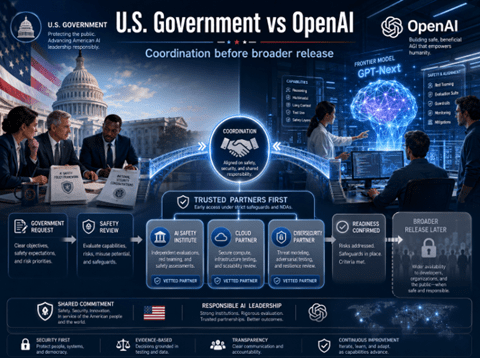
| 出典: Generated with OpenAI GPT-5.5 |
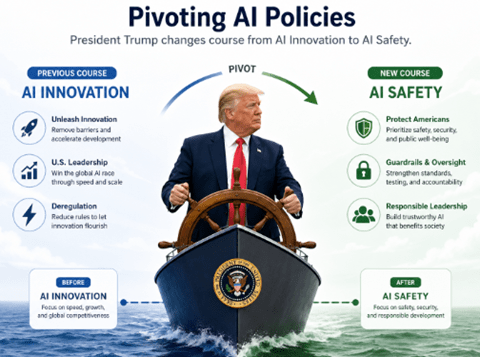
米国政府のAI規制政策の転換
OpenAIはGPT-5.6シリーズを発表したが、全てのモデルが限定リリースとなり、特定団体と共同で安全性をレビューするという異例の事態となった。政権はAI開発を推進するポジションでライトタッチの規制を導入してきた。今はこれが一転して、政権がAI開発企業と個別に交渉し、出荷許可を下すという厳しいAI規制にピボットした。OpenAIは政権との協議を受けてGPT-5.6シリーズの一般公開を延伸した。OpenAIは政権のAI政策をサポートしてきたが、GPT-5.6シリーズのリリースを巡って政権とのテンションが高まった。
サイバー大統領令
OpenAIは政権とサイバー大統領令のフレームワークを準備していると述べている。高度なサイバー攻撃機能を持つフロンティアモデルに対し、新たなAI規制が導入される方向に動き出した。キーパーソンがDavid Sacksで、政権下でAIと暗号通貨の総責任者を務めた。その後、政権を去ったが、David Sacksがサイバー大統領令を執筆していると言われている。AnthropicのMythos 5 / Fable 5とOpenAIのGPT-5.6シリーズで安全評価基準とリリースに関するルールで混乱しているが、サイバー大統領令で事態が収束に向かう機運が高まってきた。