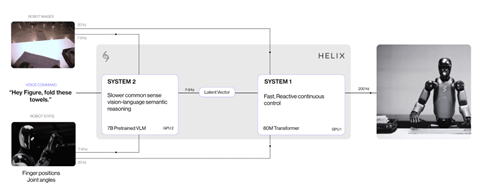
シリコンバレーに拠点を置く企業Cerebras Systemsは独自の手法でAIプロセッサを開発している。Cerebrasは5月14日、ナスダック市場に新規上場し、調達額は55億5000万ドルと、今年最大の新規上場となった。CerebrasはAI処理に特化した半導体を開発しており、ウェーファ全体を単一のプロセッサとする過激なアプローチを取る(下の写真)。これを実現することは不可能と言われたが、多くのイノベーションでブレークスルーを達成した。ウェーファサイズのプロセッサはGene Amdahlにより提唱されたが、40年後、Cerebrasがこのビジョンを実現した。

| 出典: Cerebras Systems |
Cerebrasとは
Cerebrasはカリフォルニア州サニーベールに拠点を置く企業で先進的な手法で半導体を開発してきた。このプロセッサは「Wafer Scale Engine (WSE)」と呼ばれ、単一のウェーファに多数の演算ユニット「コア(Core)」を搭載する構造となる。WSEはスパコンのエンジンとして使われ、CerebrasはG42と共同でAIスパコン「Condor Galaxy 3」を開発した(下の写真)。また、CerebrasはWSEを機械学習のエンジンとして市場拡大を狙ったが、アプリケーションはニッチで低迷を続けてきた。

| 出典: Cerebras Systems |
インファレンス・コンピューティング
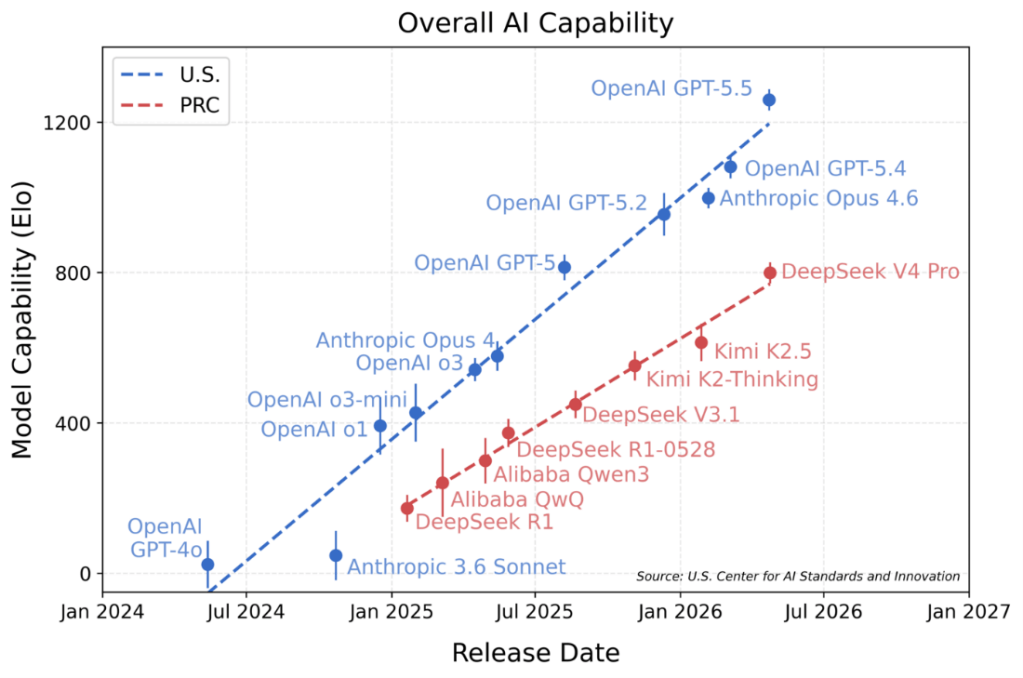
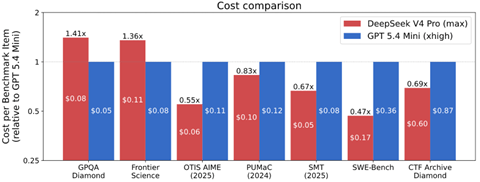
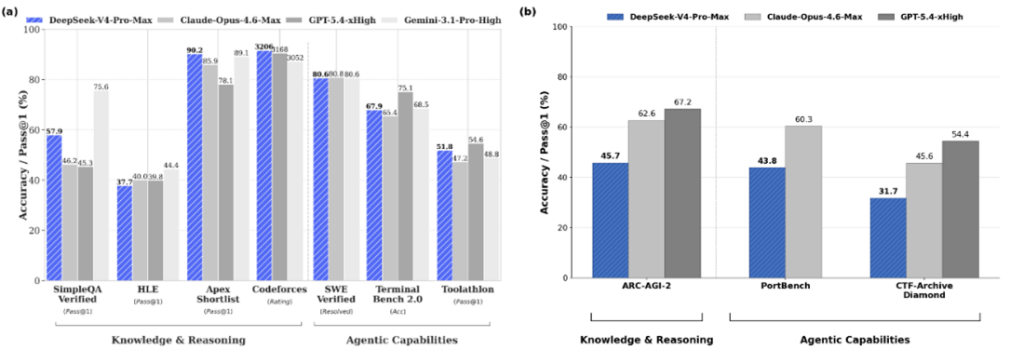
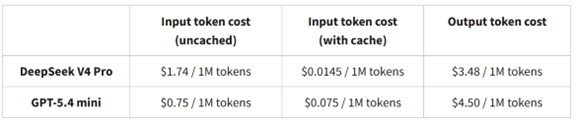
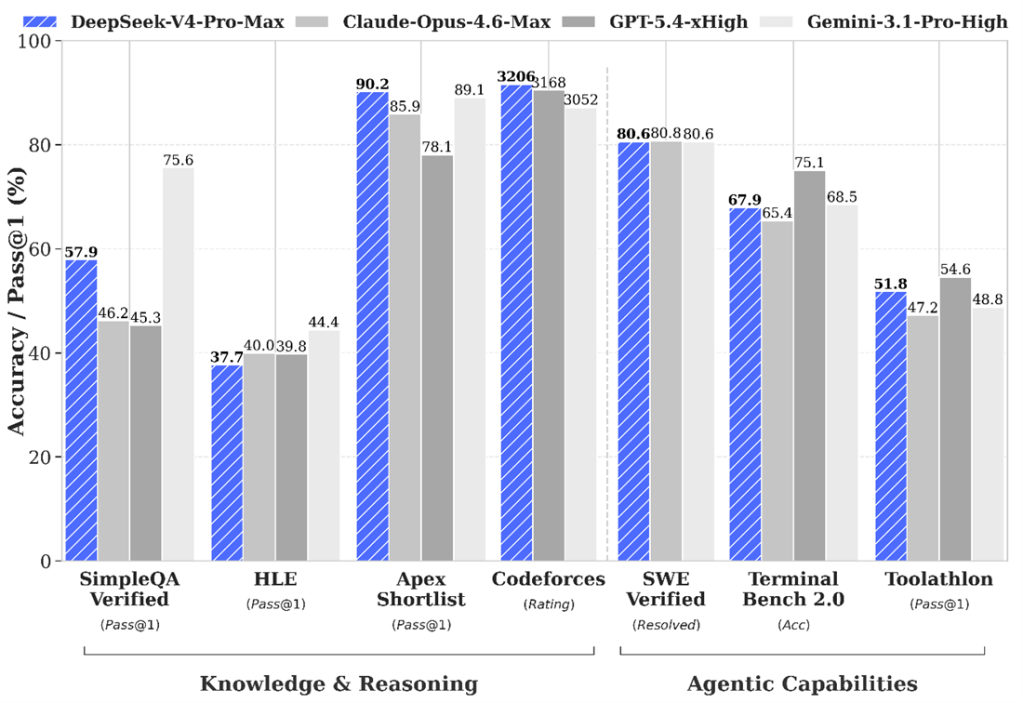
大規模言語モデルや推論モデルの急速な普及がCerebrasの大きな転機となった。WSEはこれらモデルの実行(インファレンス)で高い性能を達成し、Cerebrasはフロンティアモデルの実行エンジンに対象市場を絞り込んだ。WSEはフロンティアモデルの処理をGPUに比較して15倍から20倍の速度で実行する。Artificial Analysisのベンチマークによると、最新プロセッサ「WSE-3」でKimi 2.6を実行すると、その性能はオープンソースの中でトップの性能をマークした(下のグラフ)。また、Googleなどのトップ集団に迫る性能を達成した。

| 出典: Artificial Analysis |
WSE-3のアーキテクチャ
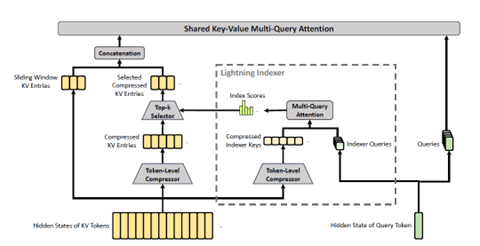
WSE-3はウェーファに複数のチップ「ダイ(Die)」を搭載し、ウェーファ全体が単一のプロセッサとなる。通常、半導体製造ではウェーファに複数のチップを生成し、これを分離して利用する。これに対し、Cerebrasはチップを切り分けないで、これらをワイヤーで連結しウェーファスケールの巨大なAIプロセッサを生み出した。WSE-3は84のチップで構成され、ここに演算装置「コア(Core)」を13,860ユニット搭載する。ウェーファ全体では900,000を超える演算装置が実装される。WSE-3の特徴は各演算装置に大容量メモリ(44GBのSRAM)を実装しており、フロンティアモデルのインファレンス処理を高速で実行できることにある。(下の写真、WSEとDieとCoreの関係、WSE-2のケース)
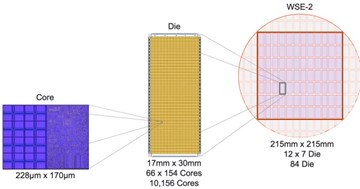
| 出典: Cerebras Systems |
イノベーション
WSEの開発では半導体製造における歩留まりが最大の課題となる。WSE-3はTSMCの5nmノードで製造されるが、コアで規格を満たさない不良品が発生する。通常の半導体であれば、これらを除外して規格を満たした良品だけを製品として出荷する。Cerebrasはウェーファで不良品コアが発生することを予測して、バックアップのコアを搭載する冗長性のアーキテクチャを取る。不良品のコアが発生すると、バックアップのコアが組み込まれ、これを置き換える仕組みとなる(下の写真)。冗長性の構造で歩留まりを上げる構造となる。
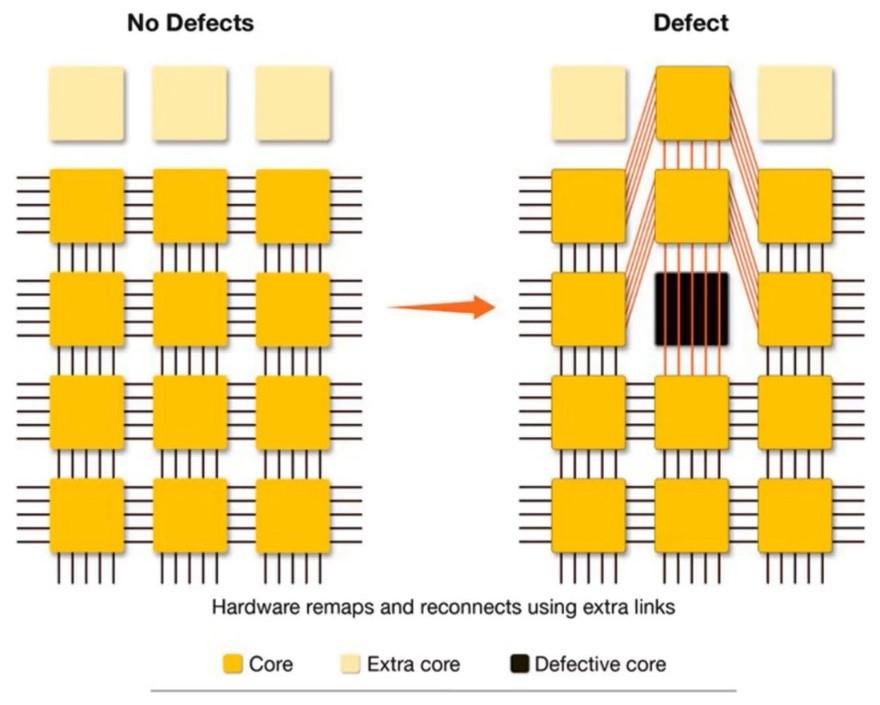
| 出典: Cerebras Systems |
主要ユーザ
WSE-3は業界の主要企業が導入を始めている。OpenAIはCerebrasと提携しWSEを導入することを発表した。OpenAIはWSEをインファレンス処理で使い、短い遅延時間が求められるAIモデルを実行する。合計で750MWの容量を購入し、2028年までに段階的に導入する。この他に、AWSもWSEをアマゾン・クラウドで利用することを明らかにした。クラウドのAIワークロードはトレーニングからインファレンスに移っており、WSE-3の性能が注目されている。

| 出典: OpenAI |
Gene Amdahlのビジョン
ウェーファサイズのプロセッサはGene Amdahl(ジーン・アムダール)により発案された。Gene Amdahlはコンピュータ・アーキテクトで、IBMで汎用機「IBM System/360」を生み出し世界的に有名となった。Amdahlはその後IBMを去り、Amdahl Corp(アムダール社)を設立し、プラグコンパチブルの汎用機を開発することに成功した。その後、1985年、Trilogy Systemsを立ち上げ、ここでウェーファサイズのプロセッサの開発を始めた(下の写真、「Wafer Scale Integration」と呼ばれた、ウェーファの直径は10センチメートル)。汎用機の全てのプロセッサをシングルウェーファに実装するという壮大なビジョンで業界や投資家が注目した。しかし、その当時は半導体製造技術が低く、ウェーファ内で多くの不良個所が発生し、その構想は実現しなかった。40年後、Gene AmdahlのビジョンがCerebrasで実現された。

| 出典: Wikipedia |