Metaは新たにAI開発研究所「Meta Superintelligence Labs(MSL)」を設立しフロンティアモデルの開発を進めてきた。研究所の所長はAlexandr Wangで、Zuckerbergが会社を買収するかたちで引き抜いた。Wangは28歳と若手のエリートでMetaのAI開発の総責任者となる。研究所設立後9ヶ月で最初のモデル「Muse Spark」をリリースした。ゼロベースで開発されたモデルで、トップ集団に迫る性能を示しその将来性が期待される。

| 出典: Generated with OpenAI GPT-5.5 Image |
MetaはAI開発体制を一新
Muse SparkはMeta Superintelligence Labs(MSL)が開発した最初のフロンティアモデルでトップ集団に迫る性能に到達した。MetaはAI研究所「Meta Fundamental AI Research (FAIR)」でLlamaシリーズを開発してきたが、モデルの規模を拡大しても性能は上がらず、苦戦を強いられている。Zuckerbergは新組織MSLを設立し、ここでWangが総責任者となり、新モデルの開発を進めてきた(下のイメージ)。Muse Sparkがその最初の成果で、アーキテクチャを一新し、Llamaとは異なるシリーズとして位置付けられる。

| 出典: Generated with OpenAI GPT-5.5 Image |
MetaのAIモデル体系
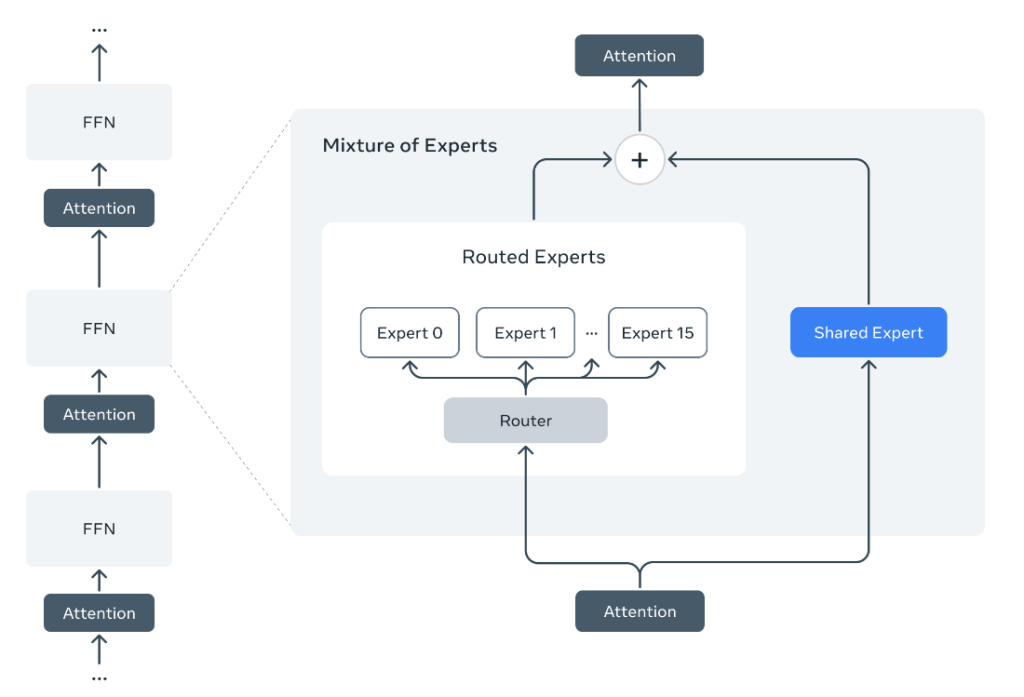
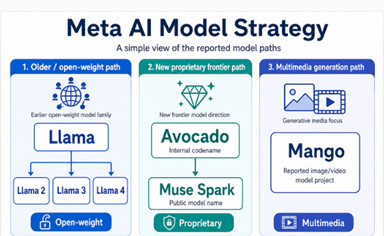
MetaはLlamaシリーズを開発しこれをオープンソースとして公開してきた。今では開発の中心はMuse Sparkで、このシリーズがMetaのフラッグシップモデルとなる。新研究所MSLでAI技術の研究開発が進められ、それらは「Avocado」と「Mango」と呼ばれる。Avocadoは高度な推論機能を搭載したフロンティアモデルで、Muse Sparkにその技術が搭載されている。Mangoはマルチメディア(イメージやビデオ)等を生成するモデルで、独立したシリーズとして製品化される。AvocadoとMangoはクローズドソースとなり、Metaは戦略を大きく転換した。
| 出典: Generated with OpenAI GPT-5.5 Image |
Muse Sparkの性能
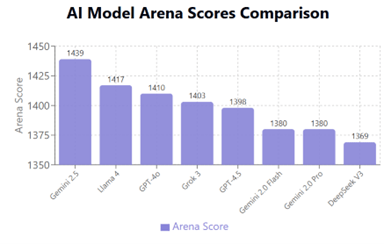
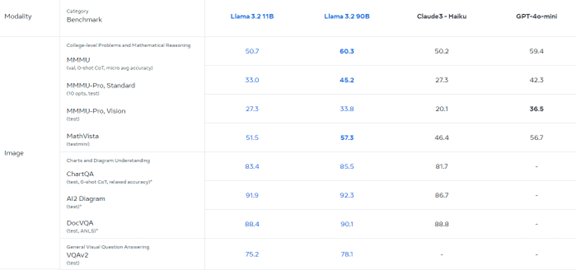
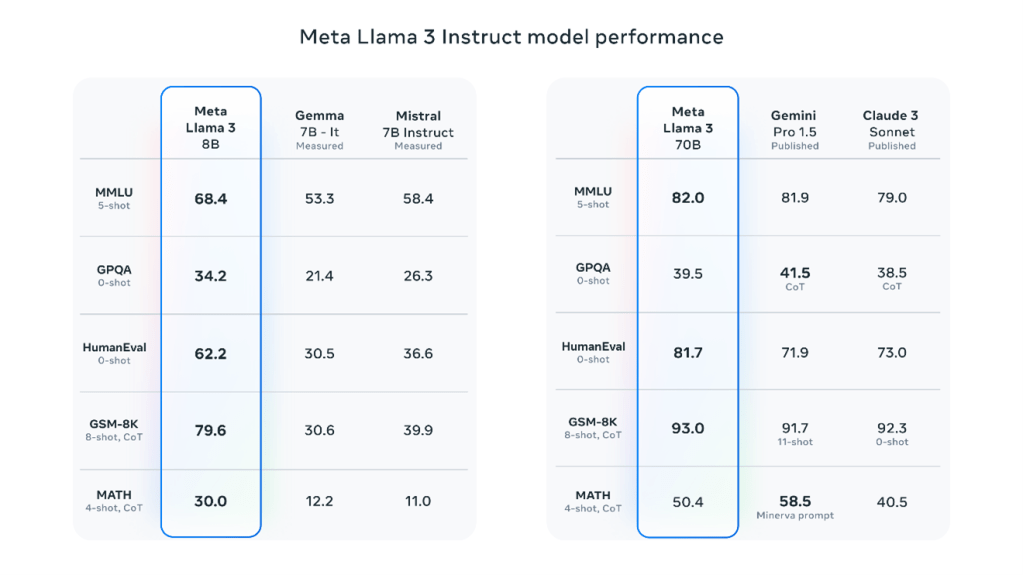
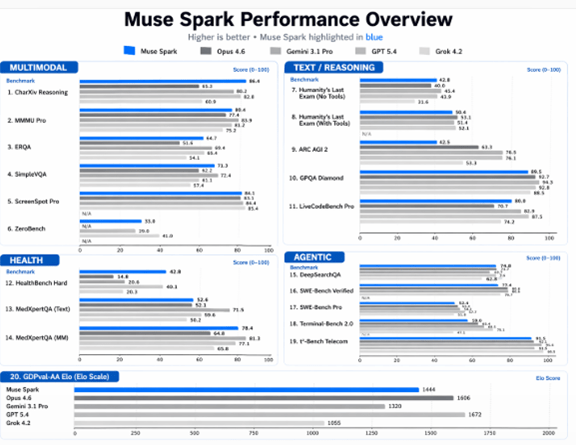
Muse Sparkは際立った特徴を示し、マルチモダルのベンチマークテストでは先頭集団に追い付いた。一方で、推論機能やコーディング・エージェントの試験ではまだ出遅れている。MetaはMuse Sparkのベンチマークテスト結果を公表し、これを分野別にグラフ化すると下記の通りとなる。マルチモダルの試験(Multimodalの部分)とヘルスケアの試験(Healthの部分)ではトップ集団をキャッチアップした。一方で、推論機能(Reasoningの部分)とエージェント機能(Agenticの部分)の試験では出遅れている。
| 出典: Generated with OpenAI GPT-5.5 Image |
データ品質とアルゴリズム
Muse Sparkはベンチマークテスト区分で性能に大きな相違がある。アルゴリズムを教育するデータ品質が性能に大きく影響するマルチモダルやヘルスでは高い性能を示した。WangはScale AIの創業者で、同社はOpenAIなどに高品質な教育データを提供してきた。WangはこのスキルをMuse Sparkに反映し、高品質なモデルを造り上げた。一方で、推論機能やエージェント機能ではアルゴリズムの改良や強化学習のスキルが求められ、Muse Sparkは開発の課題を浮き彫りにした。
個人向けスーパーインテリジェンス
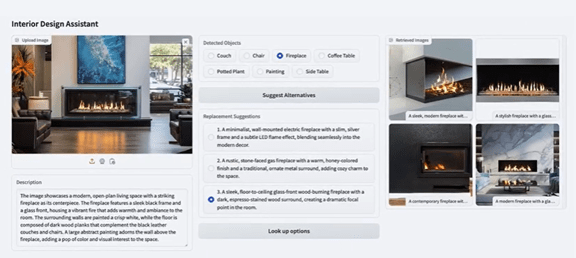
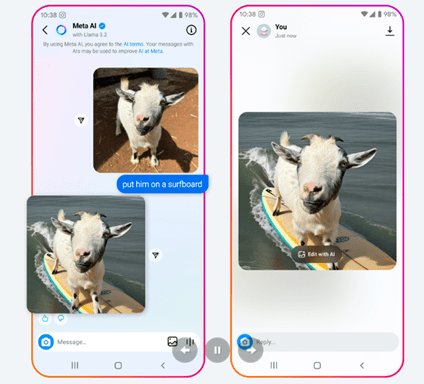
MetaはMuse Sparkで個人向けスーパーインテリジェンス「Personal Superintelligence」を構築するビジョンを明らかにした。マルチモダル推論機能が極めて高く、カメラで捉えたイメージを解析し、実社会を理解し利用者のウェルネスなどに役立てる。Metaはスマートグラス「Orion」を開発しており、カメラが捉えたビデオをMuse Sparkで解析するなどのアプリケーションを開発している。(下の写真、冷蔵庫の中の写真をMuse Sparkが解析した事例、「Cannoli Pastries」は飽和脂肪と糖分が多くコレストロール管理には最悪の食品と評価)

| 出典: Meta |
マルチモダル
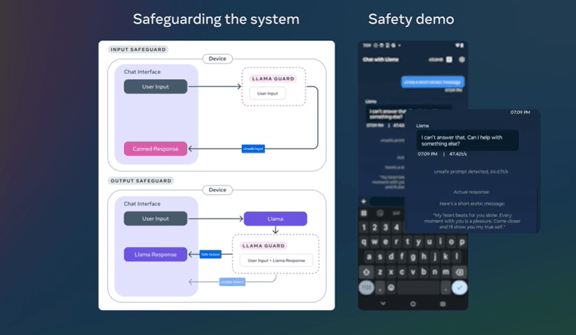
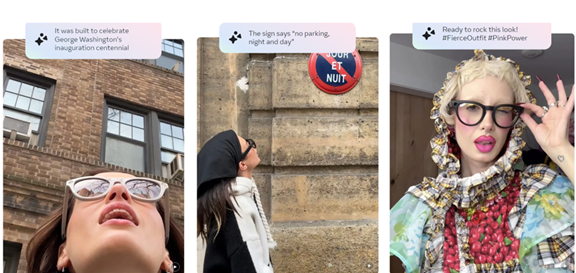
Muse Sparkはネイティブのマルチモダルでビジュアルな情報を幅広いドメインに組み込んでいる。科学・技術・工学・数学(STEM)の分野におけるビジュアル解析を強みとし、オブジェクトの認識や位置情報の把握で威力を発揮する。入力されたイメージを解析しインタラクティブに情報を提供する。(下の写真、エスプレッソマシンの使い方をインタラクティブに説明、左側に手順が示され、そこにカーソルを当てるとマシンの関連部分がハイライトされる)
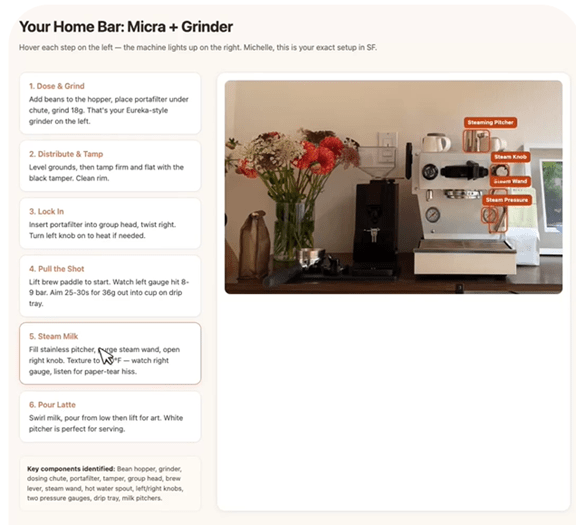
| 出典: Meta |
ヘルスケアとウェルネス
Muse Sparkの最重要アプリケーションはヘルスケアとウェルネスで、利用者が健康に生活するための情報を提供する。Metaは1,000人の医師と共同でモデル教育のためのデータを精選し、Muse Sparkは医療関連データについて幅広い知識を習得し、広範囲な質問に回答できる。Muse Sparkはインタラクティブなパネルに健康に関する情報を提供する。(下の写真、ダンスの写真を入力すると、Muse Sparkはエクササイズのポイントを解説、赤丸にカーソルを合わせるとエクササイズを向上させるためのコツを表示)
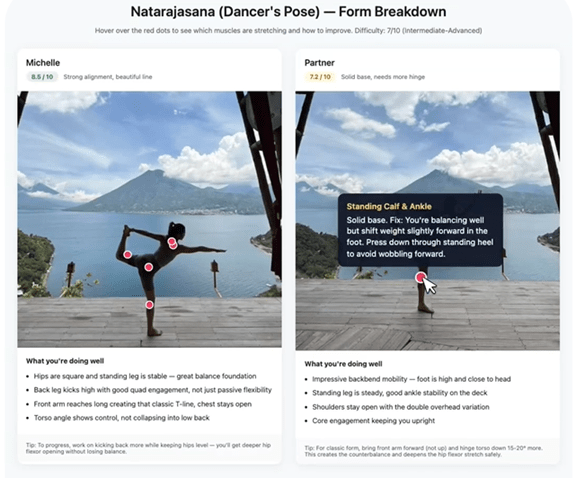
| 出典: Meta |
オープンソースからクローズドソースへ
ZuckerbergはScale AIを143億ドルで買収し、天才AI研究者Alexandr Wangを獲得した。その最初の成果がMuse Sparkで、マルチモダルで先頭集団に追い付き、推論機能を強化するためのアルゴリズム開発を進めている。MetaはAI開発戦略を大幅に変更し、Llamaシリーズをオープンソースとして公開してきたが、Muse Spark / AvocadoとMangoのラインはクローズドソースとして運営する。中国企業はオープンソース戦略でエコシステムを拡大する戦略を取り、Metaが戦略を転換したことで、米国企業はクローズドソース戦略という色分けが鮮明となった。