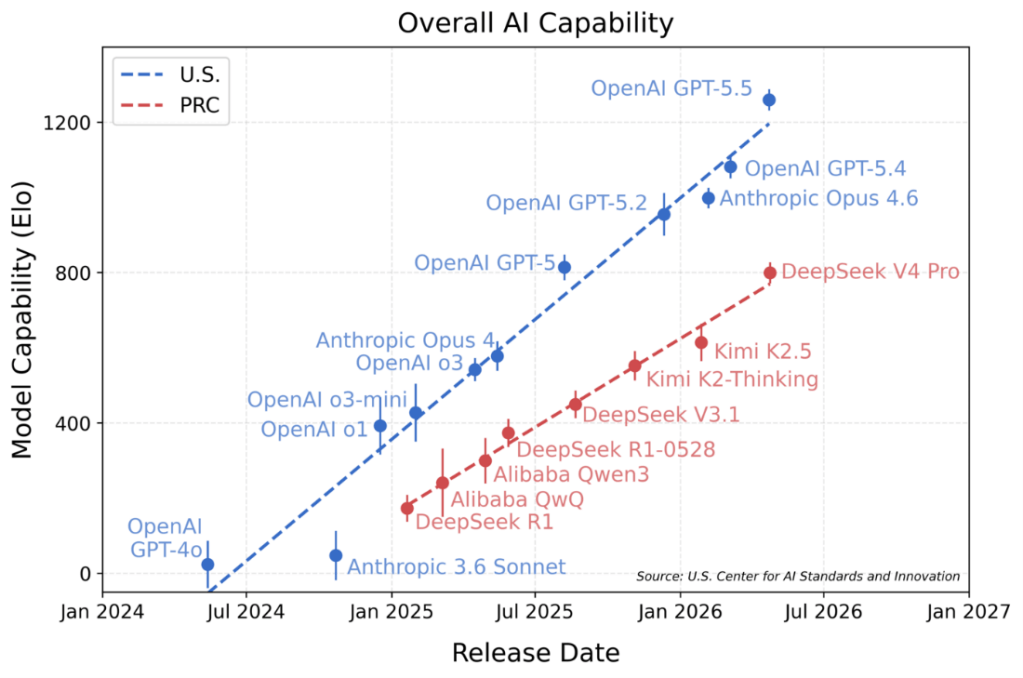
国立標準技術研究所(NIST)はDeepSeek-V4について多角的な分析を行いその結果を発表した。DeepSeek-V4はOpenAI GPT-5に匹敵する性能で、両者の技術ギャップは8か月と判定した。(DeepSeekは技術ギャップは2か月と発表)。また、DeepSeek-V4の運用コストはGPT-5.5 Miniの半分程度で、コストパフォーマンスが優れている事実を確認した。(DeepSeekはコストは米国モデルの1/10と発表)。 NISTはDeepSeekのベンチマーク手法に不備があり、モデルの性能が過大評価されていると判定した。NISTのミッションは中国モデルのモニターにあり、DeepSeek以外にも主要モデルを検証し技術進展状況をトラックしている。

| 出典: OpenAI GPT-5.5 Image |
NISTとCAISIの役割
国立標準技術研究所(National Institute of Standards and Technology, NIST)は商務省配下の組織で米国の計量技術標準化の研究を推進する。NISTがAI技術の標準化や開発推進を担い、連邦政府のAI技術ハブとなる。トランプ政権はNIST配下にAI推進室「Center for AI Standards and Innovation (CAISI)」を開設した(上の写真、イメージ)。CAISIはAIモデルを評価しその安全性を査定する任務を担う。更に、CAISIは敵対国のAI開発状況を監視する役割があり、DeepSeekなど中国の主要モデルを評価し開発状況をトラックしている。
DeepSeek-V4の評価結果
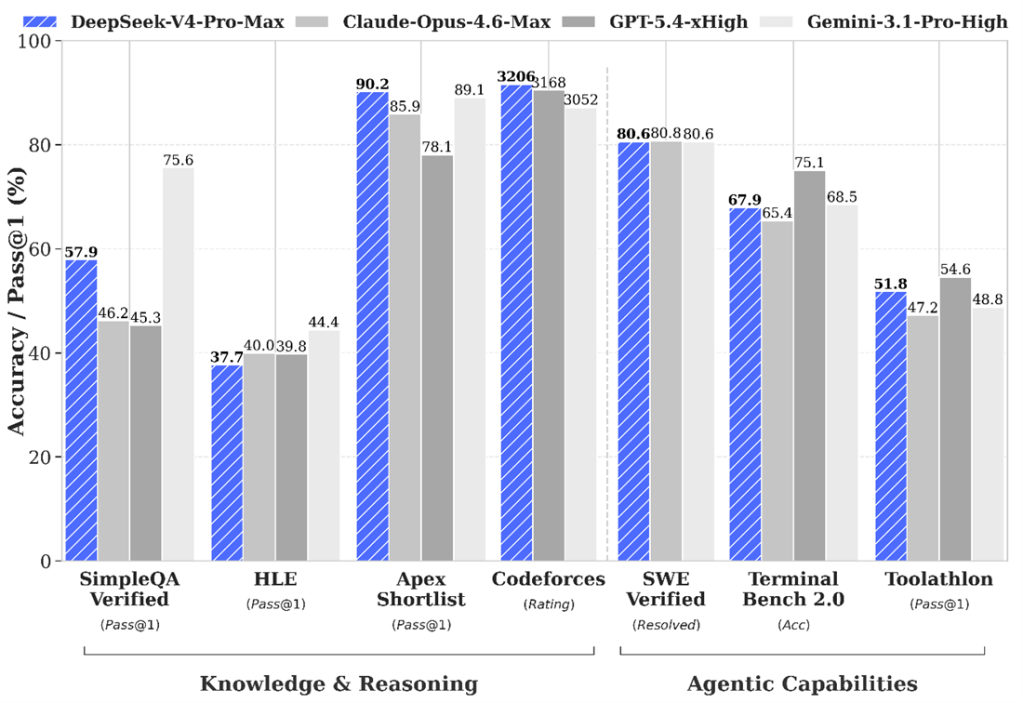
CAISIは最新モデル「DeepSeek-V4」を検証しその結果を公表した(下のグラフ)。それによると、DeepSeek-V4は中国モデルの中で最も高い性能をマークした。一方、DeepSeekはモデルの性能を実際より高く評価していると結論付けた。DeepSeekは、DeepSeek-V4はOpenAI GPT-5.4に匹敵すると評価し、両者のギャップは2か月と発表した。CAISIは、DeepSeek-V4はOpenAI GPT-5に相当し、両者のギャップは8か月と判定した。
| 出典: CAISI |
ベンチマーク方式
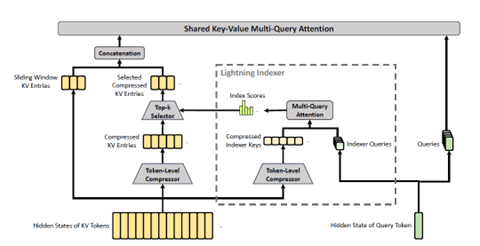
CAISIの評価手法は5つのドメインで9のベンチマークテストを実施し、それを標準化する手法でモデルを評価した。5つのドメインは、サイバー、ソフトウェア・エンジニアリング、科学、推論機能、数学でこれらを統合してモデルを総合的に評価した。この手法は「Item Response Theory (IRT)」と呼ばれ、隠れた能力(人間の知能や特性など)を評価する手法で、これをAIモデルのベンチマークテストに適用した。
インファレンスコストの試験
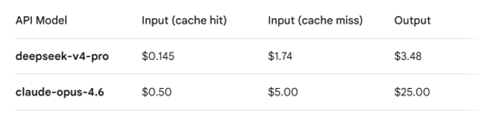
CAISIはDeepSeek-V4をクラウドベースのGPUプロセッサ「H200」と「B200」 で実行しそのコストを比較した。この際に、DeepSeek-V4はOpenAI GPT-5.4 Miniと同等の性能であることから、両者のインファレンスコストを比較した(下のテーブル)。その結果、中国モデルが格段に低コストではなく、測定項目により大きな差異がある。GPQA DiamondではDeepSeek-V4のコストが高く、GPT-5.4 Miniの1.4倍となった。その他のケースではDeepSeek-V4のコストが安く、GPT-5.4 Miniの0.47倍から0.83倍となった。
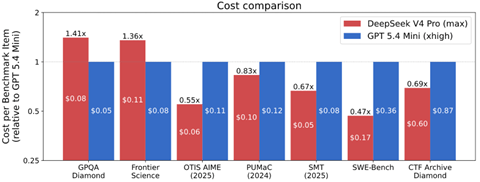
| 出典: CAISI |
ベンチマーク・コンタミネーション
CAISIはDeepSeekのベンチマーク手法は公正ではないと結論付けた。この根拠が「Benchmark Contamination(ベンチマーク・コンタミネーション)」で、モデルを教育するデータセットに試験データが混入していると判定した。モデルがベンチマークテストのデータで教育され、これらの試験項目で実力以上に高度な性能を発揮する問題となる(下のグラフ左側、モデルは事前に試験問題を知りテストで高性能を発揮)。CAISIはDeepSeek-V4を非公開のベンチマークテストで検証した。この結果、モデルの性能は大きく下がることを確認した。(下のテーブル右側、非公開のベンチマーク「ARC-AGI-2 Semi-Private」、「PortBench」、「CTF-Archive-Diamond」でDeepSeek-V4は事前に試験問題を知ることができず、性能は極端に低下した。) これらのデータからCAISIはDeepSeek-V4の評価手法は公正ではないと結論付けた。
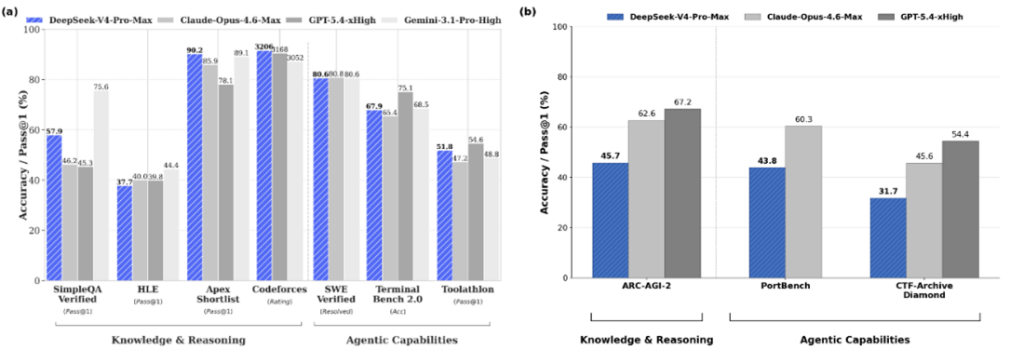
| 出典: CAISI |
競争はコストパフォーマンス
CAISIはDeepSeek-V4のインファレンス・コストを比較し、対抗モデルGPT-5.4 Miniより格安で実行できることを確認した(下のテーブル)。トップレベルの性能ではDeepSeek-V4は米国モデルに及ばないが、そこそこの性能を極めて低価格で提供し、コストパフォーマンスの競争ではDeepSeek-V4が大きく先行している事実を明らかにした。米国ではコストパフォーマンスを考慮して、GPTやClaudeを使う代わりにDeepSeekやQwenを利用する流れが広がっているが、CAISIの報告書はこれを追認した形となった。
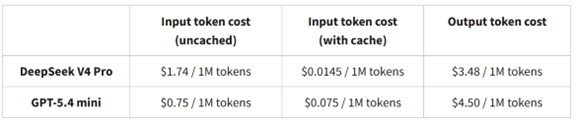
| 出典: CAISI |
中国製AIプロセッサ
DeepSeek-V4の衝撃はモデルの性能ではなく、中国製のAIプロセッサで開発されたことにある。DeepSeek-V4はHuaweiのAIプロセッサ「Huawei Ascend 950」で開発された。DeepSeek-V4の実行ではインファレンス・プロセッサ「Ascend 950PR」が使われ、教育プロセスの一部でトレーニング・プロセッサ「Ascend 950DT」が使われた。中国企業はNvidia GPUへの依存の度合いを下げ、国産プロセッサでAIモデルを開発する流れを加速している。

| 出典: OpenAI GPT-5.5 Image |