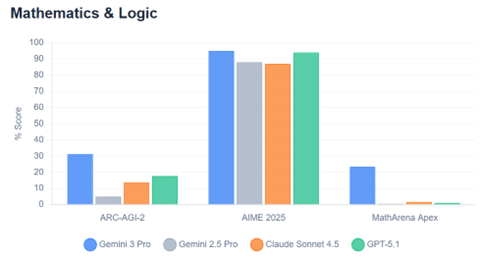
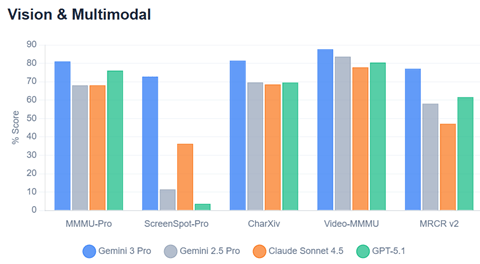
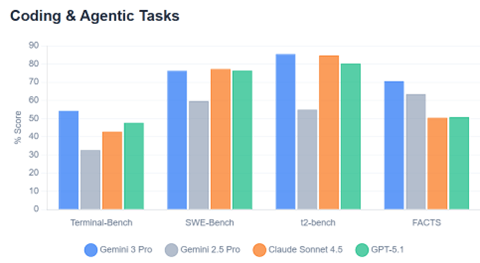
今年の世界経済フォーラム「ダボス会議」は議論のテーマがAIに集中し、パネルディスカッションや基調講演で業界の著名人が独自の見解を示した。イベントはストリーミング配信され多くのセッションを聴くことができた。特に、人間の知能を超えるAGIが注目を集め、登場時期の予測や、AGIがリリースされた後の社会像について意見が交わされた。AGIは今年中にリリースされるとの予測が示され、社会はこれを受け入れる体制の整備が間に合わず、大きな混乱が予想されるとの見解が示された。世界は今までに経験したことのない技術進化の嵐のなかを賭け走ることになる。

| 出典: World Economic Forum |
AGIのパネルディスカッション
AIに関する議論のハイライトは、GoogleとAnthropicのAGIに関するパネルディスカッションであった。「The Day After AGI」との題目で、Demis Hassabis(Google DeepMindのCEO)とDario Amodei(AnthropicのCEO)が、AGIがリリースされた後の社会像について意見を交わした(下の写真)。HassabisはAGIは2030年ころに完成すると予想するが、Amodeiは2026年から2027年にリリースされると考える。更に、AGIは大きな将来性を持つが、同時に重大な課題を内包しており、社会に大きな混乱をもたらす。制度や法令を整備することでAGIがもたらす動乱期を乗り越えることが次のミッションになるとの見解が示された。

| 出典: World Economic Forum |
HassabisのAGIに関する解釈
AGIについて共通の理解が確立されていない中、Hassabis(下の写真)はAGIである要件はAIサイエンティストと定義し、これを満たすモデルが登場するのは2030年ころと予測する。Hassabisは、アインシュタインが相対性理論を生み出したように、AIサイエンティストが新たな理論を構築する機能をAGIの要件とする。更に、AGIは世界感を持ち、実社会においてはヒューマノイド・ロボットとして実現され、人間のスキルを凌駕する。AGIに到達するには、トランスフォーマに基づく現行のAIフロンティアモデルを拡大するだけでは不十分で、大きなブレークスルーが必要であるとの見解を示した。

| 出典: World Economic Forum |
AmodeiのAGIに関する理解
Amodei(下の写真)はAGIという用語はSF映画を連想させるとして、これを「Powerful AI(パワフルなAI」と表現する。(このレポートでは用語を統一するためAGIと表記する。) AGIは、多様な分野(バイオや物理など)でノーベル賞受賞者に匹敵するブレインを搭載したモデル、と定義する。AGIは分野のエキスパートが超並列でタスクを実行するシステムとなる。AmodeiはAGIが登場する時期を2026年から2027年ころと予測する。AGIは早ければ今年にリリースされることになり、その理由を「Loop(ループ)」と説明する。ループとは「輪」であり、ここでは繰り返しの処理を意味する。AnthropicはAI開発にAIコーディング・エージェントを使っており、AIがAIをプログラムする構成となる。つまり、AIがAIを開発するループが形成され、開発速度が指数関数的に高速化される。Amodeiはあと6ヶ月から12か月で、AIコーディング・エージェントが人間レベルに到達し、プログラミングの100%をAIが実行すると予測する。AI開発のペースが爆発的に速まり、AmodeiはAGIは予想外に早く開発されると考える。

| 出典: World Economic Forum |
社会へのインパクト
HassabisはAGIの登場により社会が豊かになるとのポジティブな面を強調した。これを「Post-Scarcity(脱希少性経済)」と呼び、AIやロボットの労働力によって多くの財が潤沢に生産される社会が到来するとのビジョンを示した。AGIによりエネルギーや生活に必要な資源が潤沢になる社会が到来すると考える。一方で、Hassabisは、AGI開発を国家が単独で進めるのではなく、この恩恵を幅広く普及させるために国際協調が不可欠であると主張する。原子力に関して「CERN(欧州原子核研究機構)」が運営されているように、AGIに関する共同研究機関「AGI版CERN」を設立し、研究開発と社会移行について国家間でコラボレーションすることを提唱した。
社会が激動期に突入
AmodeiはAGIがもたらす雇用喪失が社会における最大の問題であると考える。エントリーレベルのホワイトカラーの職は、今後1年から5年以内に消滅すると予測する。初級レベルのプログラマがこれに相当し、大学卒業者の就職問題が目の前の課題となる。インターネットで事業形態が一変したように、技術は常に社会に波風をもたらす。AGIはそのインパクトが格段に大きく、その速度が速く、今までに経験したことのない激動期に入る。Amodeiはこれを「技術思春期(Technological Adolescence)」と表現し、AGIは人間と同じように子供から大人へ成長するプロセスに入り、非常に不安定な時期を迎える。AGIの巨大な恩恵を享受するために、激動期を生き延びる仕組みを考案することが人類の次のミッションとなると提案した。(下の写真、スイス・ダボスの街並み)

| 出典: World Economic Forum |
シリコンバレーのコンセンサス
AIがAIを開発する「ループ」が形成され技術開発が爆発的な速度で進むことになる。シリコンバレーの識者はこれを「シンギュラリティ(Singularity)」と呼び、米国社会はここに足を踏み入れたとの見解を示している。ハイテク企業は大規模なレイオフを実行し、雇用喪失が現実の問題となっている。実際に、AmazonはAIとロボットの導入により16,000人をレイオフすると発表した。今年はAGIが投入され社会は大失業時代を迎えることになる。