Generative Adversarial Networks (GAN) とはGoogle Brain (AI研究部門) のIan Goodfellowが開発したニューラルネットワークで、その潜在能力に期待が高まり研究開発が進んでいる。GANは様々なバリエーションがあり多彩な機能を持っている。GANはDeep Learningが抱える問題を解決する糸口になると見られている。同時に、GANは大きな危険性を内在し注意を要する技法でもある。

| 出典: Karras et al. (2017) |
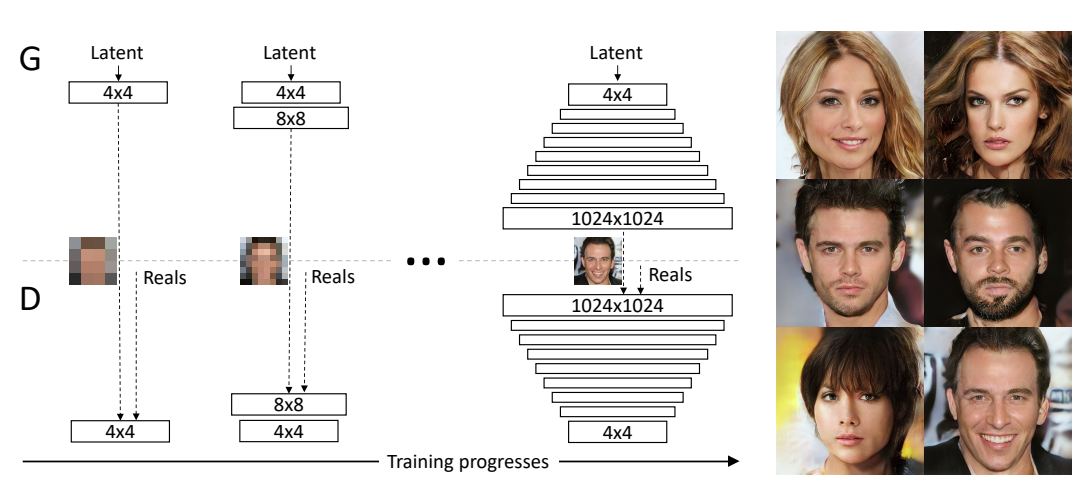
DCGAN:現実そっくりのイメージをリアルに生成
GANはニューラルネットワークの技法で二つの対峙する (Adversarial) ネットワークがコンテンツ (イメージや音声など) を生成する。GANは技法の総称で多くのバリエーションがある。その代表がDCGAN (Deep Convolutional Generative Adversarial Networks) で、ネットワークが写真そっくりの偽のイメージを生成する。Nvidiaはニューラルネットワークでセレブ画像を生成する技術を公開した。画像は実在の人物ではなくアルゴリズムがセレブというコンセプトを理解して想像でリアルに描く。このネットワークがDCGANにあたる。
DCGANはセレブ以外に様々なオブジェクトを描くことができる。上の写真はDCGANが寝室を描いたものである。これらのイメージは写真ではなく、教育されたデータをもとにDCGANが寝室のあるべき姿を出力したものである。寝室にはベッドがあり、窓があり、テーブルがあり、ランプがあることを把握している。リアルな寝室であるがこれはDCGANが想像したもので、このような寝室は実在しない。DCGANは写真撮影したように架空のセレブやオブジェクトをリアルに描き出す。
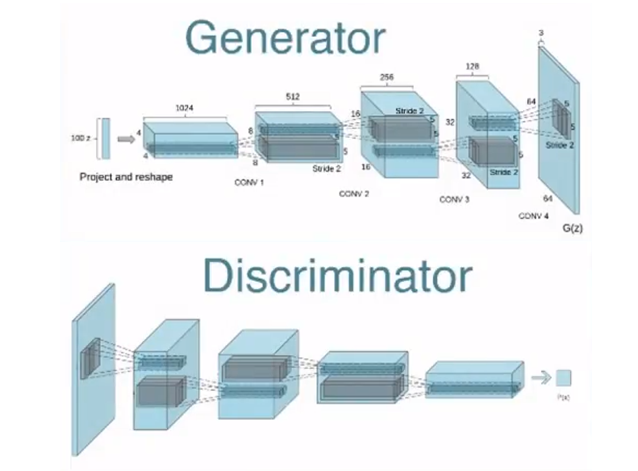
DCGANのネットワーク構造
DCGANはGenerator (制作者) とDiscriminator (判定者) から構成される (下の写真)。GeneratorはDe-convolution Network (上段、パラメータから元のイメージを探す処理) で構成され、入力されたノイズ (ランダムなシグナル) からイメージ (例えば寝室) を生成する。
DiscriminatorはConvolution Network (下段、イメージをパラメータに凝縮する処理) で構成され、ここに偽造イメージ (Fake) 又は本物イメージ (Real) を入力する。Discriminatorは入力されたイメージを処理し、それがFakeかRealかを判定 (Logistic Regression) する。このプロセスでDiscriminatorが誤差逆伝播法 (Backpropagation) で教育され勾配 (Gradient、本物と偽物の差異) を得る。
この勾配をGeneratorに入力し本物そっくりの偽物を生成する技術を上げる。両者が揃って成長する仕組みで、このプロセスを何回も繰り返しDiscriminatorが見分けがつかないリアルなフェイクイメージ (先頭の写真) を生成する。
| 出典: Amazon |
DCGANでイメージを演算する
Generatorはフェイクイメージを生成するだけでなく、生成したイメージを演算操作する機能を持っている。例えば、「眼鏡をかけた男性」ー「眼鏡をかけていない男性」+「眼鏡をかけていない女性」=「眼鏡をかけた女性」となる (下の写真)。演算の結果「眼鏡をかけた女性」が九つ生成される (右端) がその中央が求める解となる。その周囲八つのイメージから外挿 (Extrapolation) して中央のイメージが生成された。この技法を使うとイメージを操作して金髪の女性を黒髪の女性に変えることができる。

| 出典: Radford et al. (2016) |
SRGAN:イメージ解像度をアップ
SRGAN (Super-Resolution Generative Adversarial Networks) とは低解像度のイメージを高解像度のイメージに変換する技法 (下の写真) である。右端がオリジナルイメージで、この解像度を様々な手法で上げる (このケースでは解像度を4倍にする)。多くの技法が使われており、bicubic (左端、二次元のExtrapolation) やSRResNet (左から二番目、Mean Squared Errorで最適化したDeep Residual Network) などがある。左から三番目がSRGANが生成したイメージ。物理的にはノイズ比 (peak signal-to-noise ratio) が高いが (ノイズが乗っているが) 見た目 (Structural SIMilarity) にはオリジナルに一番近い。この技法はImage Super-Resolution (SR) と呼ばれ、低解像度イメージを高解像度ディスプレイ (8Kモニターなど) に表示する技術として注目されている。

| 出典: Ledig et al. (2016) |
StackGAN:テキストをイメージに変換
StackGAN (Stacked Generative Adversarial Networks) とは入力された言葉からイメージを生成する技法 (下の写真) を指す。例えば、「この鳥は青色に白色が混ざり短いくちばしを持つ」というテキストを入力すると、StackGANはこのイメージを生成する (下の写真、左側)。StackGANは二段階構成のネットワークで、Stage-Iは低解像度のイメージ (上段) を、Stage-IIで高解像度のイメージ (下段) を生成する。DCGANと同様に生成されたイメージは実在の鳥ではなくStackGANが想像で生成したもの。リアルそっくりのフェイクの鳥でこのような鳥は世の中に存在しない。言葉で意のままにフェイクイメージを生成できる技術で、応用範囲は広いものの不気味さを感じる技術でもある。

| 出典: Zhang et al. (2016) |
3D-GAN:写真から三次元モデルを生成
MITのAI研究チームは三次元モデルを生成するネットワーク3D-GAN (3D Generative Adversarial Networks) を公開した。例えば、家具の写真で教育すると3D-GANは家具を三次元で描くことができるようになる。ここではIkeaの家具の写真が使われ、それを3D-GANに入力するとその家具を3Dで描写する (下の写真、上段)。入力された写真は不完全なもので家具の全体像が見えていないが、3D-GANはこれを想像で補って3Dイメージを生成する。
3D-GANは3Dモデルイメージを演算操作できる (下の写真、下段)。例えば、「棚付きの低いテーブル」ー「棚無しの高いテーブル」+「高いテーブル」=「棚付きの高いテーブル」となる (一番下の事例)。これは3D-GANが学習した成果を可視化するために出力されたもの。GANは学習した成果をパラメータとしてネットワークに格納するが、これを直接見ることはできない。この研究の目的は隠れた領域 (Latent Spaceと呼ばれる) のパラメータを出力し3D-GANが学習するメカニズムを検証することにある。

| 出典: Wu et al. (2017) |
CycleGAN:イメージのスタイルを変換
入力イメージのスタイルを別のスタイルに変換する手法は一般にStyle Transferと呼ばれる。イメージ間のスタイルをマッピングすることが目的でDeep Neural Networkが使われる。ネットワークが画家のスタイルを習得し、そのタッチで絵を描く技術が発表されている。例えば、写真入力するとネットワークはそれをモネ・スタイルの油絵に変換する。しかし、画家の作品とその風景写真を対にしたデータは殆どなく、ネットワーク教育 (Paired Trainingと呼ばれる) が大きな課題となっている。

| 出典: Zhang et al. (2016) |
これに対しCycleGAN (Cycle-Consistent Adversarial Networks) という方式では対になった教育データ (モネの油絵とその元になった風景写真など) は不要で、それぞれのデータを単独 (モネの油絵と任意の風景写真など) で使いネットワークを教育 (Unpaired Trainingと呼ばれる) できる。教育されたCycleGANは、例えば、モネの作品を入力するとそれを写真に変換する (上の写真、左側上段)。反対に、写真を入力するとモネの油絵に変換する (上の写真、左側下段)。また、シマウマの写真を馬の写真に、馬の写真をシマウマの写真に変換する (上の写真右側、object transfigurationと呼ばれる)。更に、富士山の夏の写真を入力すると、雪の積もった冬の富士山の写真に変換できる (season transferと呼ばれる)。CycleGANはネットワークが自律的に学習するアーキテクチャで教師無し学習 (Unsupervised Learning) につながる技法として期待されている。
DiscoGAN:イメージグループの属性を把握
人間は一つのグループ (例えばバッグ) と別のグループ (例えばシューズ) の関係を把握できる。ニューラルネットワークがこの関係を把握するためにはタグ付きのイメージを大量に入力してアルゴリズムを教育する必要がある。DiscoGANという技法はアルゴリズムが両者の関係を自律的に理解する。最初、DiscoGANに二つのグループのイメージ (例えばバッグとシューズ) をそれぞれ入力しそれぞれの属性を教える。イメージにはタグ (バッグとかシューズなどの名前) はついてないがアルゴリズムが両者の関係を把握する。

| 出典: Kim et al. (2017) |
教育したDiscoGANに、例えば、バッグのイメージを入力するとシューズのイメージを生成する (上の写真)。青色のバッグからは青色のシューズを生成する (左端の事例)。これ以外に、男性の写真を入力すると女性のイメージを生成することもできる。DiscoGANも両者の関係 (バッグとシューズの関係など) を自律的に学習する。両者の関係を定義したデータ (Paired Data) は不要で、それぞれの属性のイメージ (バッグやシューズの写真集など) だけで教育できる。DiscoGANもネットワークが自律的に学習する構造で教師無し学習への道が開ける技法として注目されている。
GANがファッションデザイナー
GANは基礎研究だけでなくビジネスへの応用も始まっている。AmazonはGANを利用したファッション事業の構想を明らかにした。Amazonは自社の研究所Lab126でGANの開発を進めている。GANは流行りのファッションからそのスタイルを学習し、独自のファッションを生成する。GANがファッションデザイナーとなり、人間に代わって新しいデザインをを創り出す。
ファッショントレンドはFacebookやInstagramなどに投稿されている写真から学習する。これらの写真をGANに入力すると、GANがトレンドを学び独自の洋服などをデザインする。また、AmazonはEcho Look (下の写真、カメラ付き小型版Echo) で利用者を撮影しファッションのアドバイスをするサービスを展開している。Echo Lookを通して利用者のファッションの好みを理解し、GANはその個人に特化したデザインを生成することが計画されている。GANが生成したデザインはオンデマンドで洋服に縫製され (On-Demand Clothing) 利用者に配送される仕組みとなる。

| 出典: Amazon |
GANに注目が集まっている理由
このようにGANのバリエーションは数多く研究が幅広く進んでいる。GANに注目が集まっている理由はGANが現行Deep Learningが抱えている問題の多くを解決する切り札になる可能性があると期待されているからだ。特に、教師無し学習 (Unsupervised Learning) とタグ無しデータ (Unlabeled Data) 教育の分野で研究が大きく進む手掛かりになると見られている。上述のCycleGANやDiscoGANがこれらのヒントを示している。また、Nvidiaの研究チームはDCGANという技法で、写真撮影したように鮮明な架空のセレブイメージを生成したが、教育にはタグの付いていないセレブの写真が使われた。アルゴリズムが自律的に学ぶ技術が進化している。
GANの危険性も考慮する必要あり
FacebookのAI研究所所長のYan LeCunは「GANとその派生技術はここ10年におけるMachine Learning研究で最も優れた成果」であると高く評価している。一方、GANに寄せる期待が高まる中でその危険性も指摘されている。今までもフェイク写真が問題となってきたがGANの登場でその危険性が加速される。ニュースに掲載されている写真やビデオを信用できるかという問いが投げかけられている。(GANでフェイクビデオを生成できるのは数年先と見られている。) ソーシャルメディアに掲載されたイメージが証拠写真として使われることが多いが、これからは何が真実か分からない時代となる。AIがそうであるようにGANも諸刃の剣で、先進技術は生活を豊かにするとともに、使い方を間違えるとその危険性も甚大である。