Metaは今週、生成AI「Llama 2」をオープンソースとして公開した。Metaはこのモデルをビジネスで利用することを許諾しており、企業の選択肢が拡大する。Llama 2は性能が大きく進化し、OpenAIのChatGPTと対等となった。OpenAIが市場をリードしてきたが、Llama 2の登場で、首位争いが激化する。

| 出典: Meta |
Llama 2の概要
Llama 2はMetaが開発した大規模言語モデルで、「Llama 1」の後継モデルとなる。Llama 2はオープンソースとして公開され、企業はこれをダウンロードして、ビジネスで利用できる。Llama 1は研究開発に限定されたが、Llama 2は大学の他に、企業や政治団体などがこれを利用でき、急速に普及が広がると予想されている。また、MetaはLlama 2に関する情報を公開しており、モデルに関する理解が進み、生成AIでイノベーションが生まれると期待している。
オープンソース
Llama 2はオープンソースとして公開され、企業はこれらをダウンロードして自由に利用できる。モデルの他にプレ教育のパラメータ(Weights)を公開しており、Llama 2をそのまま運用できる。また、企業は、これをベースに、独自のデータでモデルを最適化し、専用の生成AIを構築できる。業務に特化した高速モデルを開発でき、利用方法が一気に広がる。一方、オープンソースであるが、Metaは利用条件の中で、特定の使い方について制限している:
- 利用者数の制限:利用者数は70万人以下であること
- 利用対象の制限:Llama 2を使って別の言語を開発することを禁止
オープンソースであるが一部の利用条件が制限されているので注意を要す。(この制限はGoogleなど競合企業がLlama 2を利用して技術開発することを抑止することを意図している。)
Microsoftとの提携
MetaはMicrosoftと提携して生成AIを共同で開発していくことを表明した。この最初のステップとして、Llama 2をMicrosoftクラウド「Azure」で提供する。MicrosoftはAI開発の各種ツールを提供しており、これらを利用してLlama 2を組み込んだシステムを開発できる。例えば、フィルタリング機能を使い、安全なLlama 2を開発できる。また、Llama 2は、Amazon Web ServicesやHugging Face経由でも提供され、これらのサイトからダウンロードできる。
モデルの構成
Metaが提供するLlama 2は、三つのモデル(カッコ内はパラメータの数)から構成される:
- Llama-2-7B: (70億)
- Llama-2-13B: (130億)
- Llama-2-70B: (700億)
これに加え、会話モデル「Llama 2-Chat」が公開された。これはLlama 2を会話データで再教育したもので、チャットボットとして機能する。同様に三つのモデルから構成される:
- Llama-2-7B-Chat: (70億)
- Llama-2-13B:-Chat (130億)
- Llama-2-70B-Chat: (700億)
(OpenAIとの対比では、Llama-2-70B-ChatがChatGPTに相当する。)
Llama 2-Chatの性能
Llama-2-70B-Chatの性能は、ChatGPTに匹敵する (下のグラフ最上段)。実際には、両者の性能を比較すると、Llama-2-70B-Chatの勝率は35.9%、負けは32.5%、引き分けは31.5%で、ほぼ互角の性能となる。これは、生成AIがどれだけ役に立つかという有益性(Helpfulness)で評価したもので、人間の検証者がこれを判定した。一方、Metaは、言語モデルを評価するもう一つの指標として、安全性(Safety)を導入しており、こちらはLlama-2-70B-ChatがChatGPTを上回った。

| 出典: Meta |
モデルの教育方法
Llama 2-Chatは、Llama 2という言語モデルを、会話モデルに最適化する手法で開発された。Llama 2はプレ教育(Pretrained)された大規模言語モデルで、これを会話データで再教育し、Llama 2-Chatを生成した(下のグラフィックス)。その際に、人間のフィードバックでアルゴリズムを教育し、モデルは人間と対話するスキルを習得した。前述の通り、Llama 2-Chatは、有益性(Helpfulness)と安全性 (Safety)という二つの基軸を持つチャットボットとして生成された。
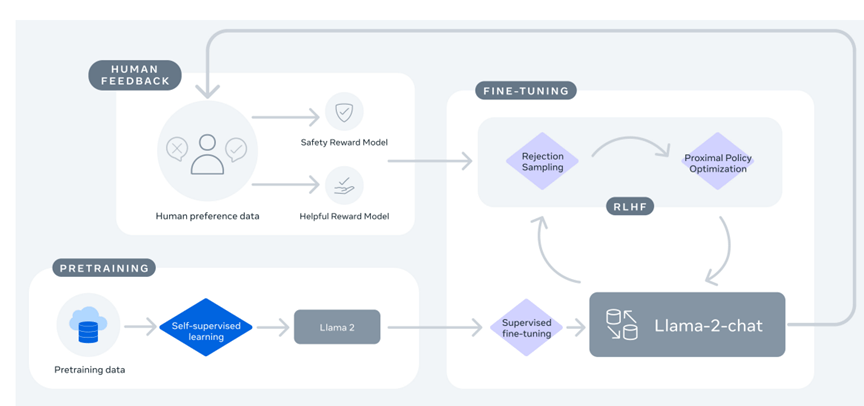
| 出典: Meta |
教育で使ったデータ
Llama 2はインターネットに公開されているデータで教育された。但し、Metaが運用しているFacebookなどのデータは使われていない。また、公開情報の中でも、個人情報が多数含まれているサイトでは 、公開情報から個人情報を削除している。Llama 2は2兆トークンで教育され、Llama 1の1.4倍の量となり、これが性能向上の大きな要因となる。
Red Teaming
MetaはLlama 2の開発でモデルの安全性を強化するために、「Red Teaming」という手法を使った。これは、開発者がモデルを攻撃し、アルゴリズムの脆弱性を発見し、これを補強する手法となる。攻撃者は、サイバー攻撃の専門家の他に、電子詐欺や偽情報開発の専門家、法律家、政治家、人権団体など、幅広い分野のエキスパートが参加した。また危険性を検証する分野として下記を選定した:
- リスク分野:犯罪計画、人身売買、非合法薬物、ポルノ、非合法医療など
- 攻撃分野:仮定の質問、プロンプトの改造、繰り返される対話など
- 兵器製造:核兵器、生物学兵器、化学兵器、サイバー攻撃など
安全性に関する評価
Red Teamingという手法を導入することで、Llama 2-Chatは極めて安全なモデルとなった。Llama 2-Chatは、人間のフィードバックでアルゴリズムを教育し安全性を高めたが、それでもアルゴリズムは危険性を内包している。これらをRed Teamingの手法で改良することで、安全性を向上させた。バイデン政権はAI企業に、安全なモデルを生成するために「Red Teaming」の手法を推奨したが、Metaはこれに準拠した最初の企業となった。その結果、危険な情報を出力する割合が大きく低下し(下のグラフ、紺色の部分)、ChatGPT(下のグラフ、右端)と比較し、高い安全性をマークした。
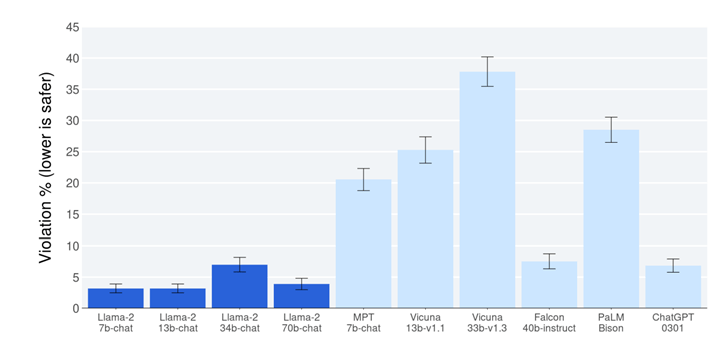
| 出典: Meta |
Metaの目論見は
MetaはLlama 2をオープンソースとして公開する理由として、コミュニティと共同で生成AIを開発することで、成長のスピードが速まるとしている。具体的には、Metaは、Llama 2の利用状況を把握し、それをベースにモデルを改良することで、大きな進展が期待できるとしている。この背後には、Facebookで偽情報が拡散し、アメリカ社会が混乱した問題がある。これを教訓にMetaは、生成AIでは他社に先駆けて安全なモデルを投入し、社会に寄与することを目指している。










