Googleは世界大規模のAI言語モデル「PaLM」を開発した。AI言語モデルとは言葉を理解するシステムで、規模が大きくなるにつれ、言語機能が向上することが分かっている。Googleが開発した巨大モデルは、言葉を理解する機能に加え、推論機能、プログラムをコーディングする機能でブレークスルーを達成した。

| 出典: Sharan Narang et al. |
PaLMとは
Googleは、2022年4月、世界大規模のAI言語モデル「Pathways Language Model (PaLM)」を公開した。AIの規模はパラメータの数で示され、PaLMは540B(5400億)個で、Microsoft・Nvidia連合が開発した「Turing NLG」の530B(5300億)個を上回り、トップの座を奪った。AI言語モデルはニューラルネットワークの規模が大きくなるにつれ、言語機能が向上することが分かっているが、PaLMでもこの事象が示された。PaLMは、言語翻訳、文章要約、言語理解などの基本機能に加え、推論、常識に基づく説明、プログラミング、ジョークの説明など、多彩な機能を習得した(上の写真、PaLMが習得した機能)。
言葉を理解する能力
AI言語モデルの基本機能は言葉を理解する能力で、それを測定するため、様々なベンチマークテストが用意されている。PaLMは代表的な29のベンチマークを実行し、28の種目で現在の記録を塗り替えた。下のグラフ;ベンチマーク結果、横軸は言語機能の種別で、縦軸は記録更新の大きさを示す。PaLMは推測機能(Natural Language Inference)や常識に基づき理由を説明する機能(Common-sense Reasoning)など、知能が問われる分野で大きな成果を達成した。

| 出典: Sharan Narang et al. |
因果関係
言葉を理解する能力の測定では、AI言語モデルが設問に回答し、その得点で機能を評価する。原因と結果という二つの事象の関係を問う問題は「Cause and Effect」と呼ばれ、AI言語モデルが因果関係を理解する能力を試験する。下の写真;因果関係の試験。「試験で好成績を上げた事象と、試験勉強の関係」を問うもの。青文字がPaLMの回答。「勉強をしっかりすると、試験で高得点を取れる」という因果関係をPaLMは理解した。因果関係を理解することはAIにとって大きな障壁であった。

| 出典: Sharan Narang et al. |
下の写真;絵文字を使ったゲーム。絵文字で示された内容を理解し、それが示す映画を当てるゲーム。絵文字は「ロボット」、「昆虫」、「若葉」、「地球」で、これらと関係する映画を当てる問題。PaLMは、絵文字というイメージを理解し、それをもとに映画「Wall-E」と回答。正しく推論できる能力を示した。

| 出典: Sharan Narang et al. |
推論機能
PaLMは言語能力の中で「推論(Reasoning)」機能でブレークスルーを達成した。推論とは、いくつかの命題から、結論を引き出す思考方法で、人間の理性を代表する能力である。PaLMは、数学計算における推論 (multi-step arithmetic reasoning)と、常識に基づく推論 (common-sense reasoning)で高い性能を発揮した。
数学計算における推論機能
数学計算における推論機能とは、計算問題を解くための推論機能を指す。下の写真右側下段;算数の問題。「カフェテリアに23個のリンゴがあり、ここから20個を使い、新たに6個を購入した。リンゴはいくつあるか?」という問題で、人間は簡単に解くことができるが、AI言語モデルにとっては難解。PaLMは「11」と正しく回答した。PaLMは、9歳から12歳の子供が算数の問題を解く能力の60%に到達した。
ステップに分けて推論
数学計算はコンピュータの基本機能であるが、AI言語モデルはこれを人間のように、論理的に考えて解くことができなかった(下の写真左側)。これに対し、PaLMは、数学計算を複数のステップに分けて推測することで、正しく答えることができた。この手法は「Chain of Thought Prompting」と呼ばれ、AI言語モデルが思考過程を複数のステップに分けて実行し、その結果を出力する。人間の論理思考を模倣したもので、ステップごとに推論を重ねることで、正解率が大きく向上した。下の写真右側;黄色のシェイドの部分がPaLMの推論過程を示している。

| 出典: Sharan Narang et al. |
常識に基づく推論機能:ジョークを説明
常識に基づく推論機能とは、文章の意味を、社会常識を使い、言葉を理解し、推測する機能を指す。例えば、ジョークについて、なぜ面白いのか、PaLMはそのオチを説明することができる。下の写真;PaLMがジョークを理解しそのオチを説明。ジョーク「GoogleはTPUチームにクジラを採用した。クジラが異なるPodの間でコミュニケーションする」。PaLMがジョークの意味を解説「PodとはTPUプロセッサの集合体で、また、Podはクジラの集団という意味がある。採用したクジラは、他のTPUチームとコミュニケーションできることを意味している。」

| 出典: Sharan Narang et al. |
常識に基づく推論機能:論理的推論
PaLMは提示された文章の内容を論理的に推論することができる。一見、不条理で意味不明な文章を示されると、PaLMはそれを論理的に推測し、その真意を把握する。下の写真;提示された文章を考察し、PaLMがその意味を推論する問題。意味不明な文章「長い間、頭を持っている山があり、それを見学するためにドライブした。その東隣の州都はどこか?」。PaLMの推論:「頭を持っている山は、ラシュモア山(Mount Rushmore)で、サウスダコタ州にある。その東隣はミネソタ州で州都はミネアポリス。」(ラシュモア山には大統領の胸像が彫られている。)

| 出典: Sharan Narang et al. |
プログラミング機能
PaLMはプログラミングする技術を習得した。具体的には、人間が言葉で指示した内容をPaLMがプログラムに変換する(下の写真)。また、PaLMがプログラムを他の言語に変換する。更に、PaLMはプログラムのバグを修正することができる。下の写真;人間が言葉でタスクを指示すると(左側)、PaLMはその内容をプログラミングする(右側)。ここでは異なる音符の長さを合計するコードを生成。

| 出典: Sharan Narang et al. |
アルゴリズムのバイアス
PaLMが判定した結果は、公正ではなく、バイアスしているため、この危険性を事前に評価した。また、アルゴリズムが、性別や人種に関し、危険な表現を出力する可能性を指摘した。例えば、PaLMは、イスラム教(Islam)という言葉に暴力を結び付ける傾向が強い。これは教育に使われたデータが公正ではないために起こる現象で、Googleはこれらを事前に測定し、制限事項としてドキュメントに纏めた。このドキュメントは「Model Card」と呼ばれ、PaLMの使用説明書となり、ここに機能概要や制限事項が記載されている(下の写真、Model Cardの一部)。AIは医薬品と同じように、使い方を誤ると生活に支障をきたすので、その使用手引きが重要な役割を担う。

| 出典: Sharan Narang et al. |
プロセッサ構成
PaLMの開発は、Googleが開発したAIプロセッサ「TPU V4」で実行された。AIプロセッサはラックに搭載され、「Cloud TPU v4 Pods」というAI専用サーバを構成する(下の写真)。PaLMの開発では、2台のCloud TPU v4 Podsが使われ、合計で6144台のTPU V4でアルゴリズムの教育が実行された。このシステムはGoogleが構築した最大構成のTPU Podで、ここでPaLMの教育が並列に実行された。

| 出典: Google |
Pathwaysとは
PaLMは「Pathways Language Model」の略で、AIモデル「Transformer」を「Pathways」という方式で教育した言語モデルを意味する。Pathwaysとは、大規模なアルゴリズムの教育を並列に実行する方式で、多重で処理することで処理効率を上げることができる(下の写真)。教育では二つのPod(Pod 1とPod 2)を使い、教育データを二分割 (AとB)し、それぞれのPodで実行する。Aのデータで教育が終了すると、その結果(Gradient)をBに送り、残りの半分のデータを教育する。これにより、Podを効率的に使うことができ、稼働率57.8%を達成した。
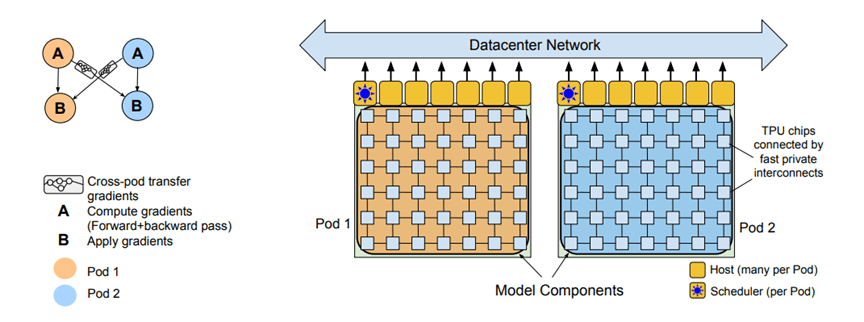
| 出典: Sharan Narang et al. |
AI言語モデルの開発競争
AI言語モデルの開発競争がし烈を極め、ニューラルネットワークのサイズが急速に拡大している。OpenAIは「GPT-3」(パラメータの数は1750億)を開発し、AIモデルが巨大化する口火を切った。これに対し、MicrosoftとNvidia連合は「Turing NLG」(パラメータの数は5300億)というモデルを開発し、NvidiaのGPUスパコンでアルゴリズム教育を実行した。GoogleのPaLMはこれを100億上回り、世界最大規模のAIモデルとなった。
大規模AIモデルを開発する理由
各社が競って大規模AIモデルを開発する理由は、ニューラルネットワークはサイズが大きくなるにつれ、機能が格段に向上するためである。基礎機能が強化されることに加え、アルゴリズムが新たな能力を習得することが分かっている。PaLMでもこの事象が観測され、ニューラルネットワークのサイズを更に大きくすることで、推論機能など知能の一部を獲得した。これから更にAIの規模を拡大すると、人間レベルの知能を得ることができると期待されている。