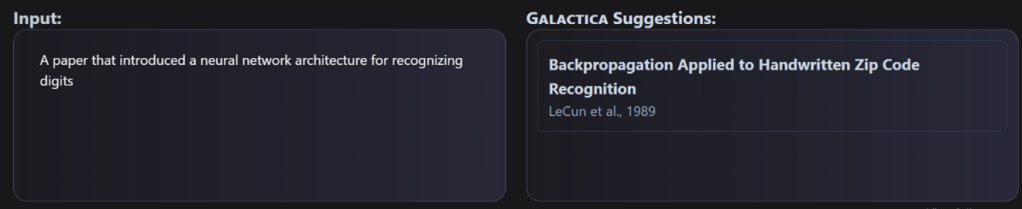
Metaは今週、開発者会議「Connect 2023」を開催し、AIの最新技術を公開した。Metaは大規模言語モデル「Llama 2」を開発し、オープンソースとして公開している。Metaはこのモデルを改良し、高度なチャットボットを開発した。「Meta AI」は汎用チャットボットで、ビジネスを中心に使われる。「セレブAI」は著名人のキャラクターを持つAIで、会話を通してスキルを学ぶ。これらは、Llama 2を改良した「Llama 2 Long」に構築されたAIモデルで、FacebookやInstagramの中に展開される。

| 出典: Meta |
Meta AIとは
「Meta AI」は汎用的なチャットボットで、質問に回答し、指示に従ってタスクを実行する。例えば、Meta AIに「おとぎ話にナマケモノを使いたいが、その名前とキャラクタを創作して」と尋ねると(下のグラフィックス左側)、それに的確に回答する(右側)。Meta AIの特徴は、会話を長く続けても、話題から逸れないで、忠実に筋を追っていく機能にある。Metaは言語モデルを改良した「Llama 2 Long」を開発し、この機能を獲得した。

| 出典: Meta |
セレブAI
Metaは著名人のデジタルツインとなるAIモデルを投入した。これは「セレブAI」と呼ばれ、著名人との会話を楽しむことができる(下のグラフィックス)。モデルはそれぞれのキャラクターを持ち、著名人が得意分野のスキルをコーチする。テニス選手の大坂なおみは「Tamika」という名前でAIとなり、アニメの専門家としてアドバイスする(左から三番目)。Metaは「セレブAI」を拡張し、クリエーターが自身のアバターを生成することを計画している。企業は独自のセレブAIを構築し、ブランドをプロモーションすることが可能となる。
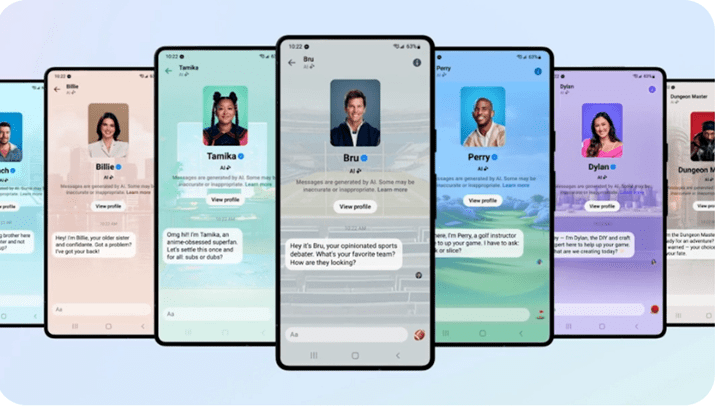
| 出典: Meta |
Llama 2 Longとは
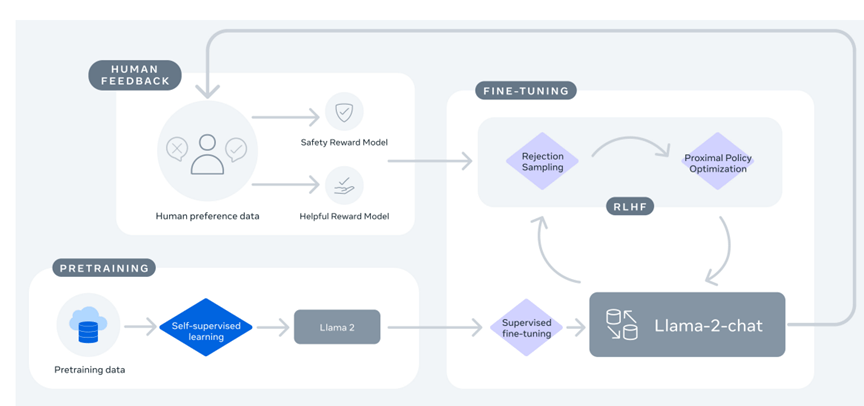
これらのモデルは「Llama 2 Long」の上に構築されたAIアシスタントとなる。Meta AIは大規模言語モデル「Llama 2」をオープンソースとして公開しているが、これを改良して「Llama 2 Long」を開発した。Llama 2 Longは入力するテキスト量(Context Window)を拡大する手法で教育された。これにより、会話を長く続けても、チャットボットはこれを忠実にフォローする機能を獲得した。
Llama 2 Longの性能
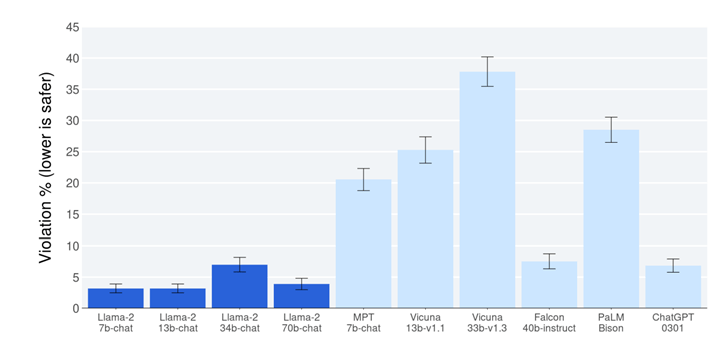
このモデルは「Long-context Language Models」と呼ばれ、長いコンテクストを正しく理解できる言語モデルとなる。このモデルは、同時に、チャットボットの基本機能である、問われたことに正しく回答する機能も向上した(下のグラフ)。ベンチマーク結果によると、Llama 2 Longの精度は「GPT-3.5 Turbo」(下から二番目)と「Claude-2」(最下段)を上回った。しかし、GPT-4の精度には及ばなかった(下から三番目)。
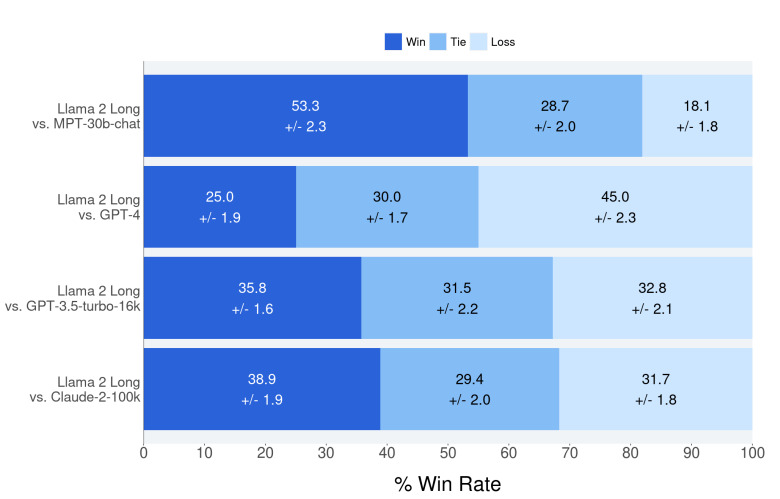
| 出典: Wenhan Xiong et al. |
イメージ生成モデル
Metaは同時に、テキストでイメージを生成するモデル「Emu」を公開した。EmuはMeta AIの中で使われ、言葉の指示に従って、カラフルなイメージを生成する。この機能を使うと、言葉でスタンプを生成できる(下のグラフィックス左側)。「買い物に行こう」とテキストを入力すると、これに応じたスタンプを生成する(中央)。また、Meta AIに、「雲の上でサーフィン」と指示すると、そのイメージが生成される(右側)。Meta AIはFacebookやInstagramやWhatsAppに展開され、友人にオリジナルなスタンプやイメージを送るために使われる。
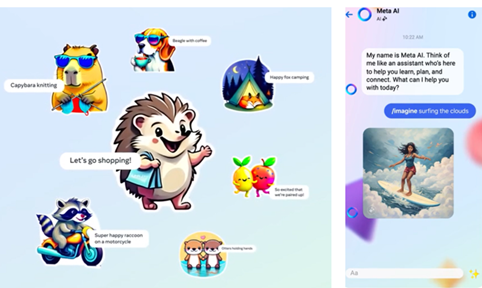
| 出典: Meta |
Metaのオープン戦略
Metaは他社とは異なり、大規模言語モデルをオープンソースとして公開する戦略を取っている。企業や大学は、Llama 2をダウンロードして、独自の生成AIを開発し、これをビジネスで利用できる。Llama 2を核とするエコシステムが拡大しており、MetaはAI開発の原動力として高く評価されている。
Metaの目論見は
オープン戦略の目的は社会貢献だけでなく、自社の製品開発にこれを生かすことにある。Connect 2023でZuckerbergは、開発者コミュニティからLlama 2に関する様々な意見を聞き、これを製品開発に反映していると述べた。この第一弾がMeta AIで、ソーシャルメディアで利用者が簡単に使えるAIモデルが生まれた。来年には後継モデル「Llama 3」を投入するとしており、MetaはChatGPTに対抗する製品を次々に開発する計画を明らかにした。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}