AGIのリリースが目前に迫るなか、AnthropicはAGIが社会にもたらすインパクトを研究する組織「Anthropic Institute」を開設した。AGIは社会に多大な恩恵をもたらすと期待されるが、同時に、社会構造が根本から変わり大きな混乱が予想される。Anthropic Instituteは同社のフロンティアモデルをベースに、技術・社会・経済の観点からこれを検証し、責任あるAGI開発を実施する。AGI社会にソフトランディングすることが究極のゴールとなる。

| 出典: Anthropic |
Anthropic Instituteとは
Anthropic InstituteはAGIのインパクトを研究するシンクタンクとして位置付けられる(下の写真、イメージ)。共同創設者であるJack Clarkが代表を務め、技術から経済まで幅広い分野の専門家から成るチームで構成される。「Frontier Red Team」はAGIを技術の観点から検証する。「Societal Impact Team」はAGIの利用方法など社会に及ぼすインパクトを検証する。「Economic Research Team」はAGIが雇用や経済に与える影響を継続して監視する。(AnthropicはAGIという用語は使わず、これを「Powerful AI」と表現する。ここでは用語を統一するために「AGI」と記載する。)

| 出典: Generated with Google Gemini 3.1 Pro |
研究対象エリア
Anthropic InstituteはAGI社会で発生が予測される問題を中心に研究を進める。AGIに関して様々な問いが投げかけられており、これらに回答することを主題とする。対象領域は:
- 雇用と社会:AGIは雇用や社会にどのようなインパクトを与えるか
- リスクと耐性:AGIはどのようなリスクをもたらすか、また、社会はこれらのリスクに耐えることができるか
- 価値観:AGIの価値をどう評価するか
- 回帰型システム:AGIが自己の機能を改良する技術(Recursive Self-Improving)をどう制御するか
大規模フィールド調査
Anthropic InstituteはAIに期待する機能について大規模な調査を実施した(下の写真)。159か国の81,000人の利用者を対象に、AIをどのように活用しているか、また、AIをどのように使いたいかにつて、包括的なデータを収集した。この調査ではAIモデルが「調査エージェント (Anthropic Interviewer)」となり、利用者と対話する形式でデータを収集した。更に、調査エージェントが収集したデータを解析し、それを特性に基づいて分類・階層化した。フィールド調査の全てのプロセスを調査エージェントが実行した。

| 出典: Anthropic |
AIモデルに期待すること
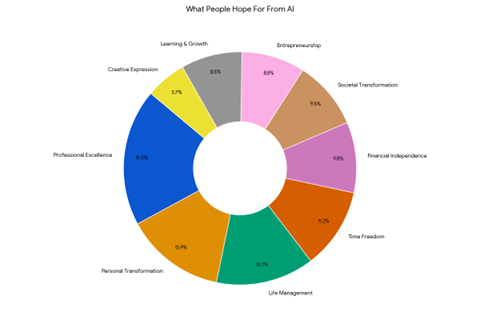
調査ではAIモデルに期待することを質問し、その結果を9のカテゴリーに分類した(下のグラフ)。そのトップが、「Professional Excellence」で、AIモデルをルーチン業務に適用し、専門分野で才能を発揮することを期待している実態が明らかになった。期待していることの主要項目は:
- Professional Excellence (18.8%):専門職で才能を発揮、ルーチン作業をAIモデルで実行し、空いた時間で意味のある仕事を遂行
- Personal Transformation (13.7%):健康やメンタルヘルの改善、AIで自分自身を理解しフィジカルヘルスやメンタルヘルスを改善
- Life Management (13.5%):日々のスケジュール管理、AIを秘書として使い、日程管理など生活や仕事をオーガナイズ
- Financial Independence (9.7%):経済的な自立、AIでビジネスを立ち上げ、収益をあげ、仕事に縛られない生活をすること
- Societal Transformation (9.4%):グローバルな問題を解決、AIで病気、貧困、地球温暖化問題などを解決
- Learning & Growth (8.4%):パーソナル・チューター:AIを個人教師として利用し、新しい分野のスキルを獲得
| 出典: Anthropic / Generated with Google Gemini 3.1 Pro |
何を恐れているか
調査エージェントはAGIに関する懸念事項や切迫する恐怖感について質問した。AGIがリリースされると社会は劇的に変わり個人生活が激変する。人々は将来を予見できなくなり、多大な恐怖感を抱いていることが明らかになった。その主なものは:
- Job & Economic Displacement:AIにより職を奪われること
- Cognitive Atrophy & Loss of Autonomy:AIにより人間は考えることを停止し、思考能力が退化すること
- Unreliability & Misinformation:AIが出力する情報は誤りを含み、人間がこれをチェックす作業が大きな負担となる
- Loss of Meaning & Creativity:AIにより人間の創造性の価値が下がり、存在感が低下する
- Wellbeing & Dependency:AIと会話する時間が長くなり、社会的に孤立する。人間の代わりにAIを友人として選ぶという異常事態
AGIトラスト
Anthropic Instituteは技術・社会・経済に関する検証チームから成るシンクタンクとして位置付けられ、AGIの開発や運用を安全に実行するための組織となる。この組織や手法が米国におけるAGIトラストのテンプレートとして捉えられる。米国連邦政府はAI規制を撤廃し、企業がフリーハンドで先進技術を開発する政策を取る。米国では法令による規制ではなく、民間企業がAGI開発と運用を責任もって遂行する自主規制の路線が取られる。AGIにおいてはAnthropic Instituteがその先端を進み、AI業界がその成果に着目している。