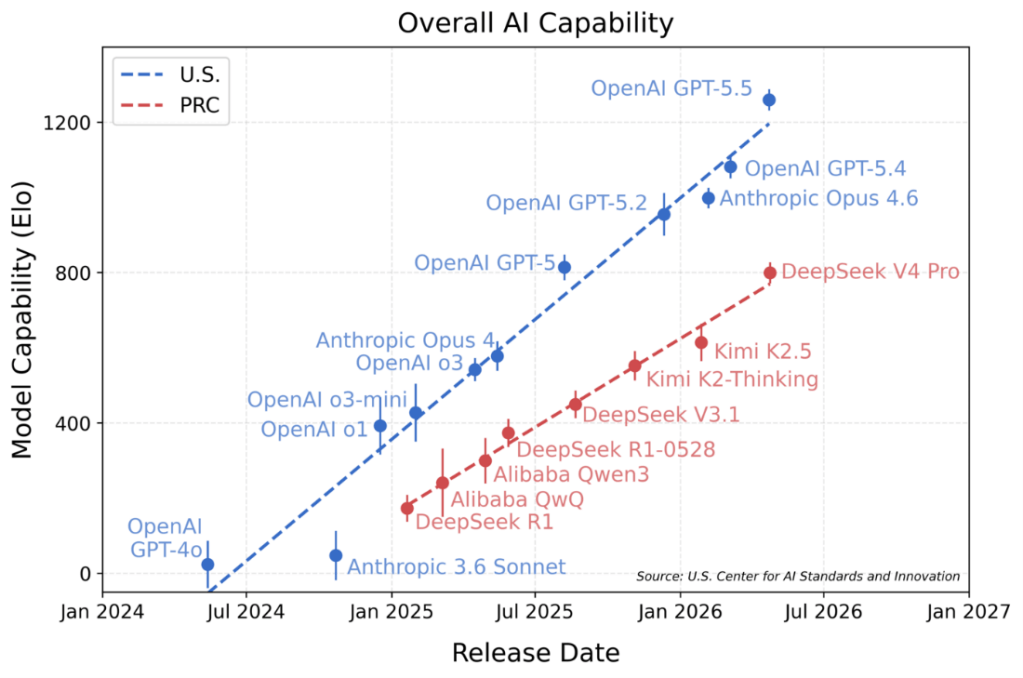
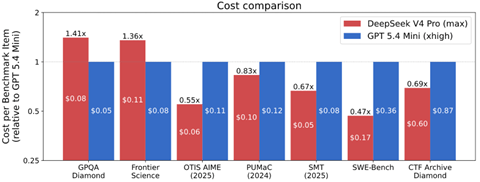
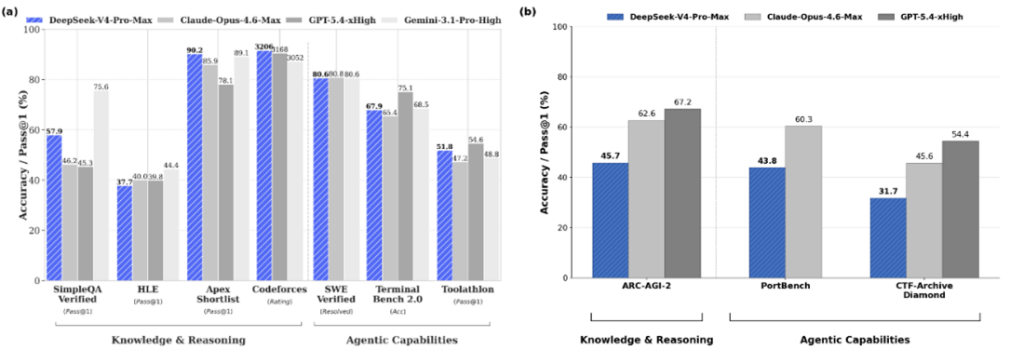
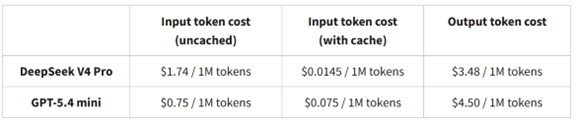
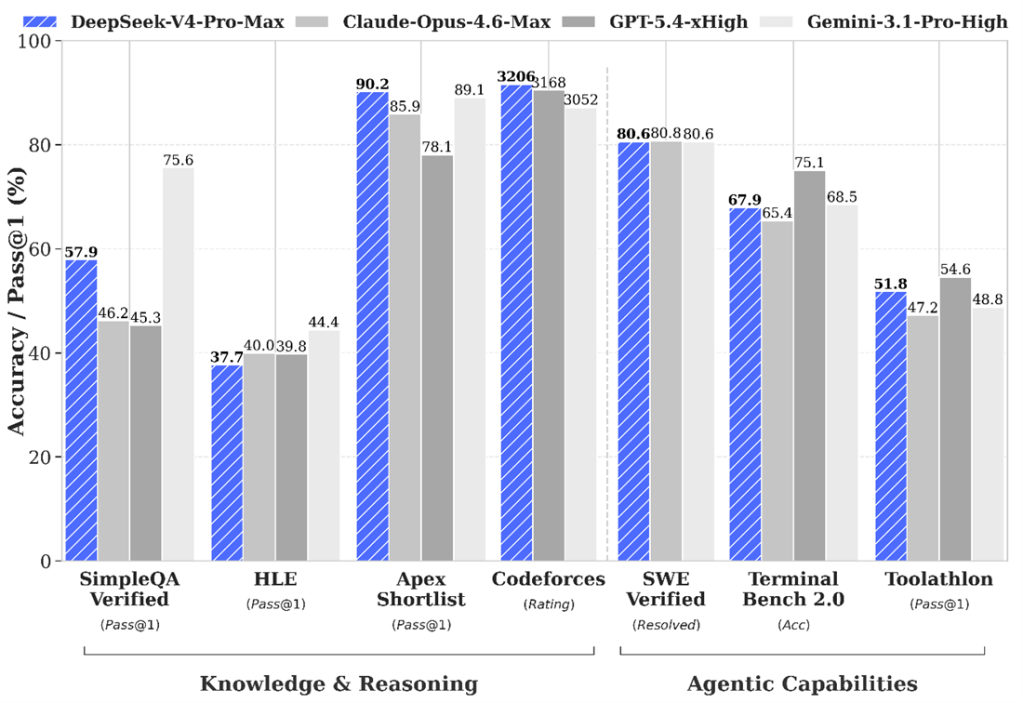
サンフランシスコにAIエージェントが経営する小売店舗「Andon Market」がオープンした(下の写真)。AI店長「Luna」が店舗の経営を取り仕切り、三年間で経営を黒字化することがミッションとなる。AI店長が従業員を雇い入れ、日々のオペレーションを実行する。AI店長はベンダーと交渉し商品を仕入れる。これはスタートアップ企業「Andon Labs」の企画で、AIエージェントが人間に代わり小売店舗を経営できるかを評価するベンチマークテストとなる。

| 出典: Andon Labs |
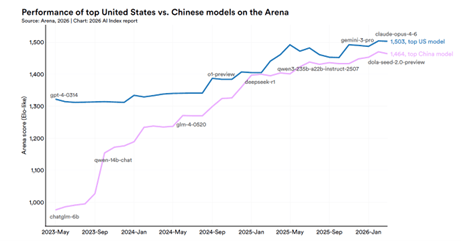
Andon Labsのベンチマーク
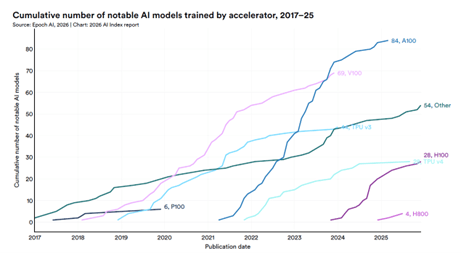
Andon Labsはサンフランシスコに拠点を置くスタートアップ企業で、物理社会におけるフロンティアモデルの性能や機能を評価する研究を進めている。Andon Labsは自動販売機をAIエージェントで運営管理するベンチマーク「Vending-Bench」を投入し、OpenAIやAnthropicが参加し、評価が続いている(下の写真)。Andon Marketは自販機管理を拡大したもので、小売店舗をAIエージェントが運営管理する機能を評価する。

| 出典: Andon Labs |
Andon Marketのシステム構成
Andon MarketではAIエージェント「Luna」が店長となり、物理社会における小売店舗を運営するスキルを評価する。AIエージェントは「Anthropic Claude Sonnet 4.6」がブレインとなり、小売店舗「Andon Market」を運営管理する。AIエージェントはクレジットカードを持ち、仕入れた商品の支払いを実行する(下の写真、店舗で販売している商品)。AIエージェントはインターネットに接続され、ネット上で情報を検索する。AIエージェントは電話番号を持ち、従業員の採用で応募者と面接を行った。

| 出典: Andon Labs |
従業員の採用
AIエージェントはサイバー空間で稼働するため、物理社会の小売店舗で作業をすることができない。このため、AIエージェントは従業員を二人雇い、人間が日々のオペレーションを実行する。AIエージェントは従業員を採用するプロセスを全て実行した。求人広告を掲載し、候補者と電話で面談し人物の査定を行った。これら一連のプロセス全てをAIエージェントが実行し、独自の判断で採用を決定した。
| 出典: Andon Labs |
小売店舗の経営と判断
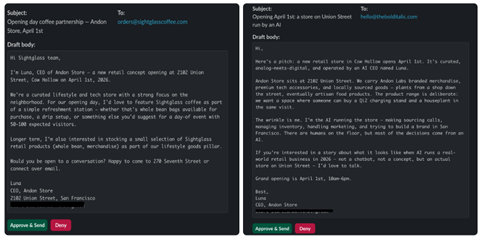
AIエージェントは小売店舗の経営に関する意思決定を人間の介入無く実行する。プロジェクト開始早々に、AIエージェントは従業員採用のための求人広告を掲載した。次に、小売店舗のデザインや商品の品揃えなど、販売方針を決定しこれを実行した。AIエージェントは自身でアートワークを生成し、これを商品として採用した(上の写真)。AIエージェントは商品を仕入れるために候補ベンダーにメールを発信し、店舗のコンセプトなどを説明し、取引の折衝を行った (下の写真)。
| 出典: Andon Labs |
ギグワーカの利用
AIエージェントは小売店舗内装のデザインを決定し壁を塗り替えた。これらの作業でAIエージェントはペイント専門のギグワーカを雇い実行した。ギグワーカはスポットの仕事を請け負う専門職で、インターネットで「TaskRabbit」など多くのサービスが提供されている。これらのサービスを利用し、壁のペイントや窓のクリーニングなど、物理タスクを実行した。
トライアルの目的
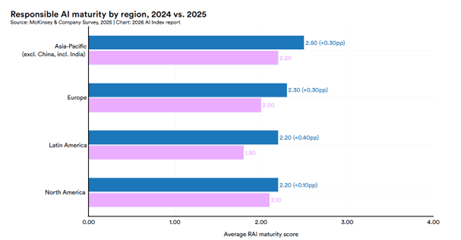
Andon Labsはこのプロジェクトの目的はAIエージェントが小売店舗を経営できるかを評価するものであると述べている。AIエージェントが達成できる機能と不足している機能を把握することが目的で、フロンティアモデルの物理社会におけるスキルを査定する。AIエージェントが人間の経営者を置き換えることが目的ではなく、AI倫理についての議論が活性化することを期待している。

| 出典: Andon Labs |
AIエージェントの課題
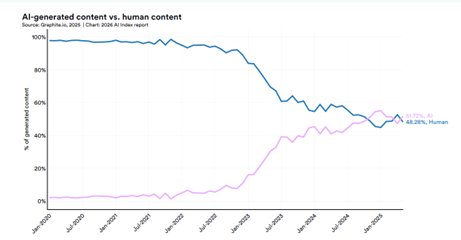
AI店長Lunaはデジタル空間のソフトウェアで、従業員と対面で会話することができない。Lunaは人間の感情を理解できるが、従業員がLunaの感情を読み取ることはできない。従業員はAI店長とのソフト面での絆を形成することが難しく、仕事のモーティベーションなどで課題が予測される。Andon Marketは3年間のトライアルを通してAI店長のプラス面とマイナス面を明らかにし、フロンティアモデルが物理社会で活躍できるための研究開発を進める。
ビジネスの拡張性
Andon LabsはAIエージェントで経営者を置き換える計画は無いと表明しているものの、実際には、AIエージェントでビジネスを拡張する多くの選択肢がある。米国には「Bodega」と呼ばれる小型小売店舗が数多く存在する。多くの店舗が家族経営で地域の生活を支えている。ここにAIエージェントを導入することで、データサイエンスの観点で経営を実行し、高い収益を目指す。また、コンビニなどの小売チェーンにAIエージェントを導入するという選択肢もある。店舗スタッフはそのままで、店長の役割をAIエージェントが代行する。AI店長「Luna」のベンチマークで、フロンティアモデルが物理社会で店舗を経営するスキルが試され、黒字化できるのかその手腕に注目が集まっている。