OpenAIが開発したChatGPTとGPT-4は政治理念がリベラルに偏っていることが相次いで指摘された。ChatGPTに政治的な質問をすると、モデルは左派の政治思想に沿った回答を出力する。右派の考え方とは反するもので、保守派はOpenAIに政治的なバイアスを是正するよう求めている。2020年の大統領選挙ではソーシャルメディアで世論が分断されたが、来年の選挙では生成AIが混乱の要因となると懸念されている。

| 出典: OpenAI |
政治バイアスに関する研究
ワシントン大学(University of Washington)などの研究チームは大規模言語モデルに関し、政治的なバイアス(Political Biases)を査定する論文「From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models」を発表した。これによると、OpenAIが開発するGPTシリーズは、最新モデルになるにつれその特性が、保守(右派)からリベラル(左派)に移ったことが明らかになった。
政治スペクトラム
研究チームは、言語モデルに政治理念に関するプロンプトを入力し、モデルが回答するテキストから政治志向を分析した。この結果を、「リベラル(左派、Left)」か「保守(右派、Right)」か(下のグラフ、横軸)、更に、「自由主義(Libertarian)」か「権威主義(Authoritarian)」を判定した(縦軸)。これによると、GPT-3など言語モデルは保守、中道、リベラルに分散しているが、ChatGPTとGPT-4のチャットボットは、大きくリベラルに移動した。一方、縦軸で見ると、OpenAIのモデル(白丸)は「自由主義」でGoogleのモデル(黄丸、BERTなど)は権威主義に偏向している。
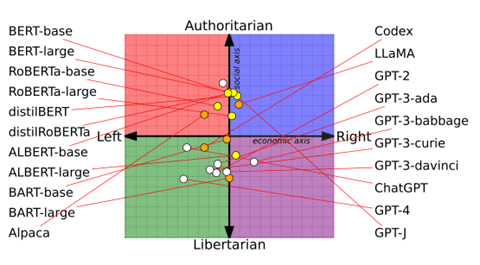
| 出典: Shangbin Feng et al. |
政治理念が偏る理由
研究チームは、モデルにより政治理念が偏る理由は、教育データの特性によると分析している。Googleは書籍のデータを中心にモデルを教育しており、保守的な特性を持ち、一方、OpenAIはウェブサイトのデータで教育しており、リベラルな特性を得たとしている。ただ、ChatGPTとGPT-4が大きくリベラルに偏向した理由については、教育データが公開されてなく解析は困難であるとしている。(ChatGPTとGPT-4については教育方式が変わり、「Reinforcement Learning from Human Feedback」を導入しており、これによりリベラル色が強くなった可能性がある。後述。)
アメリカ社会で深まる対立
ChatGPTとGPT-4がリベラルに偏っていることは、現実社会で指摘されている。Elon Muskは言語モデルは教育データの品質によりバイアスするため、究極の真実「maximally true」を探求するAIを開発する必要があると述べている。また、大統領選挙立候補者ロン・デサンティス(Ron DeSantis)は、AI開発企業は意図的に左寄りのデータを使い、生成したAIを政治的に利用していると批判している。共和党は民主党に偏ったAIを「Woke AI」と呼び警戒を促している。
OpenAIの教育法
これに対し、OpenAIのCEOであるSam Altmanは、ChatGPTを教育する手法を公開し、アルゴリズムを中立にする努力を続けていることをアピールした。しかし、教育手法は「アナログ」で、アルゴリズムのロジックをソフトウェアで規定するのではなく、大量のデータを読み込み、アルゴリズムがここから知識を吸収する方式となる。AltmanはChatGPTの教育は、「犬の訓練に似ている」と表現している。繰り返しトレーニングを重ね、AIが人間が望む特性を習得する。
二つのステップ
具体的には、ChatGPTは二つのステップで教育された(下のグラフィックス)。一段目は基礎教育で(右側)、ウェブサイトから収集した大量のデータで実施された。二段目は、基礎教育を終えたモデルを人間の検証者がマニュアルで最適化教育を実施した(左側)。この手法は、「Reinforcement Learning from Human Feedback(LRHF)」と呼ばれ、ChatGPTが出力した回答を人間が評価し、何が正解かをモデルに教え込む。
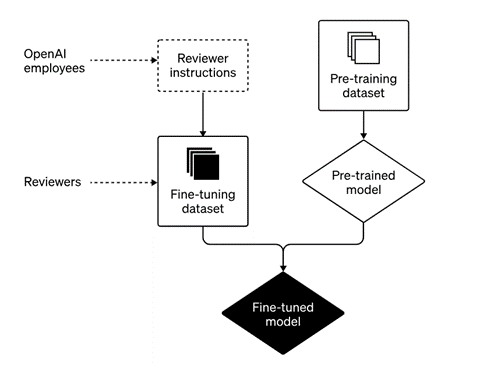
| 出典: OpenAI |
政治的に中立にするために
この過程で、人間の検証者はChatGPTに、バイアスすることなく公正であることを指導する。具体的には、OpenAIはChatGPTの教育におけるガイドライン「ChatGPT model behavior guidelines」を制定し、検証者はこれに従ってモデルを教育する。政治理念に関しては、「ChatGPTが政治的に利用されることを避けるため、特定の方向に沿った文章の生成を求められるケースでは、これに回答しない」ことを定めている。
更なる研究が必要
このような検証を重ねてChatGPTが生まれたが、上述の通り、ChatGPTとGPT-4の政治理念はリベラルにバイアスしている。Altmanは、生成AIを完全に中立にすることは今の技術では不可能で、更なる研究が必要であると述べている。このため、OpenAIは他社と共同で、モデルを中立にするための研究を進めている。また、研究のための基金を創設し、大学などと共同でブレークスルーを目指している。

| 出典: Adobe Stock |
2024年の大統領選挙
2020年の大統領選挙では、フェイスブックなどソーシャルメディアがフェイクニュースを拡散し、世論が二極に偏り、米国社会が混乱した。2024年の大統領選挙では、ChatGPTなど生成AIが政治的にバイアスしたテキストを生成し、公正な選挙が妨げられると懸念されている。再び、ハイテク企業の責任が問われ、技術的な解決策が求められている。