中国のAI企業DeepSeek-AIは大規模言語モデル「DeepSeek-V3」を公開したが、その性能は高く、開発コストは低く、米国AI市場に衝撃をもたらした。DeepSeek-V3はMetaのハイエンドモデル「Llama-3.1-405B-Inst」の性能を追い越し、更に、開発コストはMetaの1/10で、極めてコストパフォーマンスが高い製品となった。米国企業がAI市場で首位を保ってきたが、その地位が逆転した。

| 出典: DeepSeek |
中国スタートアップ企業
DeepSeek-AIは中国・杭州市に拠点を置くスタートアップ企業でAI開発で高度な技術を持つ。人間の知能に匹敵するモデル「AGI」を社会に提供することを目的に、高度な言語モデルを開発を進めている。DeepSeek-AIは大規模言語モデルを投入してきたが、12月26日、最新モデルの「DeepSeek-V3」をリリースした。
DeepSeek-V3とは
DeepSeek-V3は大規模言語モデルで、AGI開発に向けたステップとして、人間のように複雑なタスクを実行する。具体的には、言語解析に加え、推論機能を備え、マルチモダルな情報を理解する。また、DeepSeek-V3は倫理的で安全なAIとして設計されており、セーフガード機構を備え、リスクを最小に抑える構造となっている。DeepSeek-V3はAPIが公開されアプリケーションから利用できる。また、ブラウザーのインターフェイスで対話形式で使うこともできる。
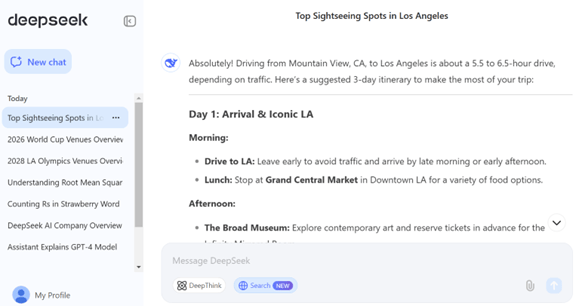
DeepSeek-V3を使ってみると
DeepSeek-V3はウェブサイトでチャットボットとして公開されており、実際に使ってその性能を検証することができる。DeepSeek-V3は対話モデルの他に、推論モデル、検索モデルとして利用できる(下の写真、検索モデルの事例、旅行プランの作成)。
- 対話モデルは汎用的なチャットボット
- 推論モデルは複雑なタスクを分割してステップごとに解いていく
- 検索モードは問われたことに関し、ウェブサイトを検索して、それを回答の形にまとめて出力する
DeepSeek-V3の知識は2023年10月までの情報で、新しい事柄に回答できない。これに対し、検索モードは最新情報までをカバーするので、使ってみて一番便利と感じる。また、DeepSeek-V3はインファレンスの反応時間が短く、質問したことをほぼリアルタイムで回答する。一方、推論機能はまだ完成度が低く、複雑な質問に正しく回答することができない。
| 出典: DeepSeek |
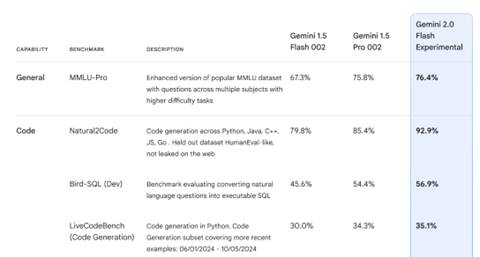
業界トップの性能に到達
DeepSeek-V3はオープンソースモデルの中でトップの成績をマークした。今までは、Meta LLama-3.2が業界をリードしていたが、DeepSeek-V3がこの座を奪った(下のグラフ、ここではLlama-3.1-405B-Instの性能が示されている。)。また、DeepSeek-V3はクローズドソースのモデルと比較しても高い性能を示し、Anthropic Claude 3.5 Sonnetに匹敵する性能を達成した。DeepSeek-V3の特徴は数学の問題を解く能力が高いことと、コーディングとエンジニアリングで高いスキルを持つことにある。

| 出典: DeepSeek |
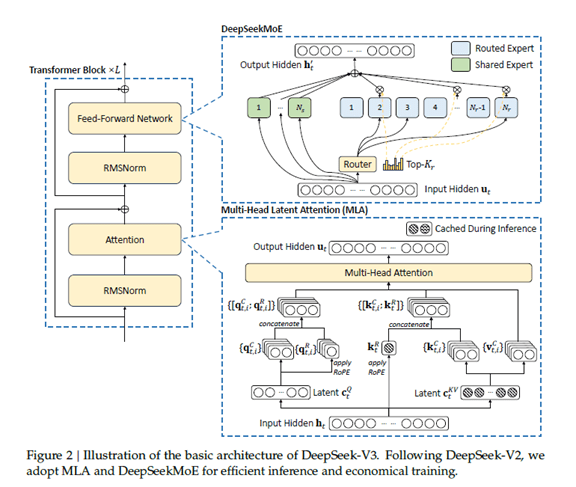
アーキテクチャで数々の工夫
DeepSeek-V3は671Bのパラメータから構成される大型モデルで、「Mixture-of-Experts (MoE)」というアーキテクチャを採用している。MoEとはモデルが複数のモジュールから構成され、トークン(入力データ)に対し最適のモジュール(エキスパート)が回答を生成するという構造となる(下の写真右上の部分)。実際には、257のエキスパートから構成され、1つの共有エクスパートと、256の専門エキスパートが金融や医療など専門分野の知識を持つ。また、DeepSeek-V3は「Multi-head Latent Attention (MLA)」という方式を考案した。これはトランスフォーマ(Transformer)のアテンション機構に関する方式で、インファレンスのプロセスで、「Key-Value」 (入力されたトークンの位置と値の組合せ) をベクトル形式(Latent Vector)に変換し、それを圧縮して格納する(下の写真右側下段)。これにより、実行時のメモリー容量を格段に縮小し効率的に稼働できる。
| 出典: DeepSeek |
開発コストは十分の一
DeepSeek-V3の開発では、プレ教育において14.8兆のトークンがつかわれた。また、ポスト教育においては人間によるファインチューニングと強化学習により、モデルが人間の価値に沿って稼働するよう最適化された。この教育ではNvidia GPUの「H800」というモデルが2778K時間使われた。これを金額に換算すると5.576Mドルとなる(下のテーブル)。これに対し、Meta Llama-3.2の教育では、Nvidia GPUの「H100」を30.8M時間稼働させ、コストに換算すると500Mドルと推定される。DeepSeek-V3はLlama-3.2の性能を上回り、これを1/10のコストで達成した。

| 出典: DeepSeek |
API価格が激安
開発コストが低いことは開発者の観点からは使用料金が低いことを意味する。API価格(1Mトークン当たりの価格)で比較すると、DeepSeek-V3の性能は他社に比べて高く、価格は大幅に低く設定されている(下のグラフ)。特に、Anthropic Claude 3.5 Sonnetと比較すると、性能は同程度であるが、API価格は1/10となっている。DeepSeek-V3のインパクトは甚大で、AI市場で価格競争が激化するトリガーとなる。

| 出典: DeepSeek |
GPU規制とイノベーション
米国政府はNvidia GPUの中国への輸出を制限しており、ハイエンドモデル「H100」は規制の対象になり、中国へ出荷することができない。これに代わり、Nvidiaはローエンドモデル「H800」を投入し、これを中国に出荷している。DeepSeekはローエンドモデルH800を使い、このプロセッサでDeepSeek-V3を開発した。H800でMetaに勝る性能に到達した理由はソフトウェアやハードウェアで様々な工夫を凝らしたことにある。トランスフォーマでは上述の通り、「Multi-head Latent Attention (MLA)」という技法を導入し、効率的なインファレンスを達成した。ハードウェアではNvidiaの高速リンク(「InfiniBand」 (ノード間通信)と「NVLink」(ノード内通信))の使い方を最適化した。DeepSeekは高速GPUを使えないという制限が課され、これがイノベーションに繋がったとも解釈できる。
フェアな開発競争か
一方、DeepSeekはGPT-4をベースに開発され、公平な競争とは言えないとの議論が広がっている。DeepSeekにモデルの構成を尋ねると、「OpenAIのGPT-4のアーキテクチャに基づくモデル」と回答した(下の写真)。GPT-4に関する技術資料を参照しモデルが開発されたと説明してくれた。一方、市場ではDeepSeekの教育においてGPT-4が生成したデータが使われたとの解釈が広がっている。その根拠として、GPT-4が出力する文言がそのままDeepSeekに受け継がれている。DeepSeekはGPT-4の知識を継承したモデルとなり、これはフェアな開発手法か意見が分かれている。OpenAIはGPT-4などでAIモデルを開発することを禁止しており、DeepSeek-V3はこの使用条件に違反したことになる。DeepSeekの開発手法に懸念が示されているが、モデルの性能は高く価格は安く、AI市場の”黒船”となった。

| 出典: DeepSeek |