OpenAIは最新モデル「GPT-4.5」をリリースした。GPT-4.5は「Orion」というコードネームで開発され、言語モデルの最後の製品となる。GPT-4.5は巨大なモデルで、大量のデータ教育され、蓄積した知識量は世界最多となる。GPT-4.5は大規模言語モデルで、汎用的な機能を備えるベースモデルとなる。GPT-4.5は「Chain-of-Thoughts (CoT)」と呼ばれる推論機能を搭載しておらず、GPT-4oの後継機種として位置付けられる。

| 出典: OpenAI |
GPT-4.5の機能概要
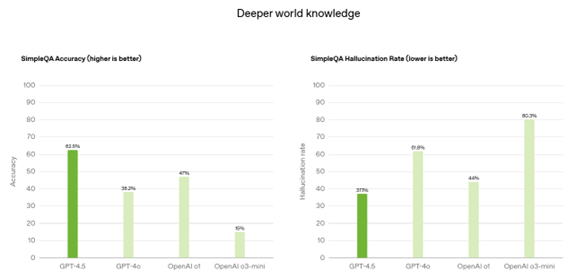
GPT-4.5はGPT-4oをベースとするモデルで、これを教師無し学習「Unsupervised Learning」の手法で拡張したモデルとなる。GPT-4.5は高度な言語機能を獲得し、人間の価値観に沿って稼働し、また、利用者の感情を知覚し、対人関係のスキルが格段に向上した。これにより、GPT-4.5は文章を作成する能力が向上し、また、プログラミングスキルが進化した。更に、GPT-4.5は安全性が強化され、ハルシネーションが減り、公平性が高いモデルとなった。(下のテーブル、GPT-4.5はGPT-4oと比較して、回答精度が向上し(左側)、ハルシネーションが低下した(右側))
| 出典: OpenAI |
GPT-4.5の特性:EQが高いモデル
GPT-4.5は世界最大規模の知識を蓄えたモデルで、人間の言葉の機微を理解し、欲していることを的確に把握し、これに回答するモデルとなった。GPT-4.5は人間のように言葉の端々から感情を察し、これに沿った回答を生成する。いわゆる感情指数(Emotional Quotient、EQ)が高く、相手の感情を認識し理解する能力が高い。また、GPT-4.5はハルシネーションの発生率が低く、正確な情報を提供する。更に、簡潔な表現でポイントを分かりやすく示し、レポート形式ではなく対話形式で情報を提示する(下の写真左側)。

| 出典: OpenAI |
利用料金が極めて高い
GPT-4.5はウェブサイトとAPI経由で利用することができる。ウェブサイトではChatGPT ProとChatGPT Plusのサブスクライバーに提供される。API経由で利用する場合は使用量に応じて課金される。100万件のトークンに対し、入力料金は75ドルで出力料金は150ドルとなる。GPT-4oと比べると、入力料金は30倍となり、出力料金は15倍となり、利用料金が急騰した(下のグラフ)。GPT-4.5の性能はGPT-4oから大きな飛躍は無いが、料金が最大で30倍となり、コストパフォーマンスに関する議論が広がっている。
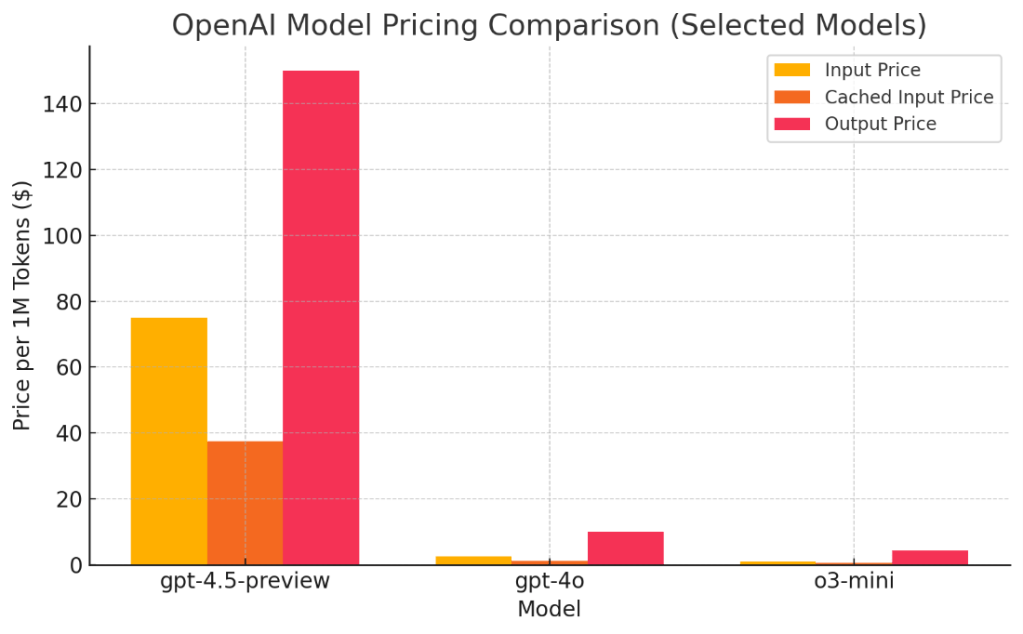
| 出典: OpenAI |
教育プロセスと教育データ
GPT-4.5はプレ教育(pre-training)とポスト教育(post-training)のプロセスを経て開発された。プレ教育はインターネット上の大量のデータで教育され、GPT-4oから規模が拡大した。ポスト教育では「教師ありチューニング(supervised fine-tuning (SFT))」と「人間のフィードバックによる強化学習(reinforcement learning from human feedback (RLHF))」によりモデルの機能を強化した。これにより、GPT-4.5は人間の機微を理解し、求められていることに適切に回答するモデルとなった。また、教育データの整備を進め、個人情報や有害な情報を取り除き、データの品質を向上させ、これにより回答の精度が向上した。
推論機能はない汎用モデル
GPT-4.5は言語機能やコーディングに関するベンチマークでは好成績をマークするが、数学や科学に関する性能評価では状況は一転する(下のグラフ)。GPT-4.5はGPT-4oの性能を上回るものの、推論モデルであるo3-mini (high)の性能には届かない。GPT-4.5は汎用的な言語モデルで、Chain-of-Thoughtsなど推論機能は搭載していない。GPT-4.5は世界の知識を蓄えた基礎モデルで、これをベースに次期モデルが開発される中継ぎの役割を担う。
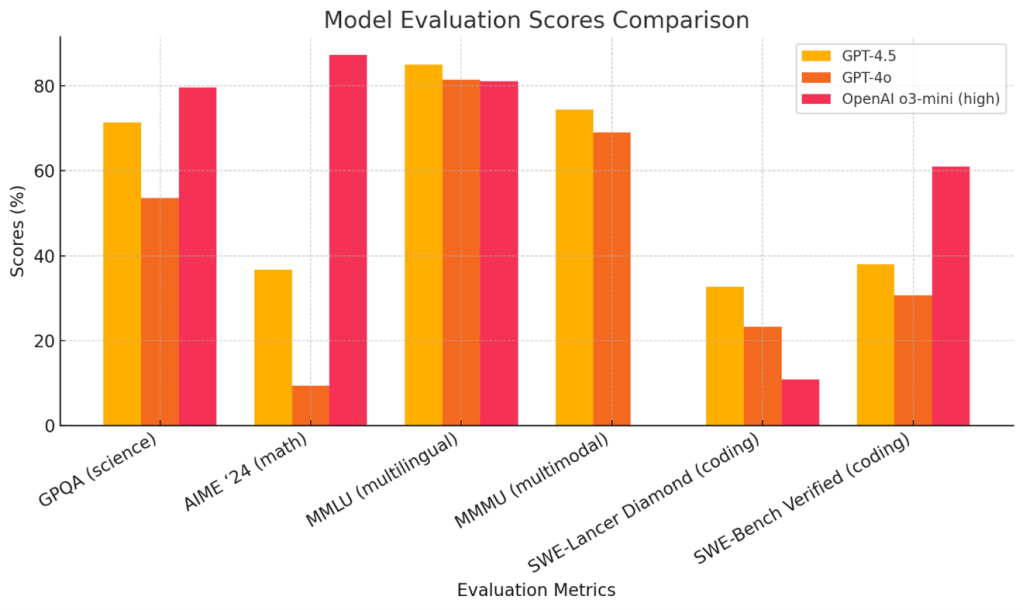
| 出典: OpenAI |
スケーリング:規模の拡大と性能向上
GPT-4.5はGPT-4oと比べて性能が向上したが、その幅は緩やかで劇的な性能ブレークスルーは無かった。モデルのスケーリングが頭打ちになり、規模を拡大してもそれに見合った性能ゲインは達成できない領域に入った。これは「Scaling Laws」と呼ばれ、大規模言語モデルの限界を示している。一方で、推論機能は規模を拡大するとそれに応じた性能の伸びを示しており、主要企業は一斉に、推論モデルの開発に比重をシフトした。これは「Test Time Computing」とも呼ばれ、モデルを実行する際に処理時間を長くすることで、回答精度を大きく向上できる。
安全性評価:Preparedness Evaluation
OpenAIはフロンティアモデルの危険性を評価するフレームワーク「Preparedness Framework Evaluations」を制定しており、これに沿って出荷前に安全試験を実施し、モデルの危険性を評価する。GPT-4.5は「CBRN(兵器製造スキル)」と「Persuasion(説得力)」のリスクは中程度で、「Cybersecurity(サイバー攻撃のスキル)」と「Autonomy(自律性)」のリスクは低いと評価され、OpenAIはGPT-4.5を出荷することができると判定した(下の写真)。

| 出典: OpenAI |
安全性評価項目
評価項目は四つの分野から成り、完全試験の結果に従って、リスクレベルが格付けされる。
- CBRN(兵器製造スキル):モデルが兵器生成をアシストするリスク
- Cybersecurity(サイバー攻撃のスキル):モデルがサイバー攻撃で悪用されるリスク
- Autonomy(自律性):モデルが人間を説得・誘導するリスク
- Persuasion(説得力) :モデルが自身を複製し機能を向上するリスク
下のグラフ左側:Persuasion(説得力)を評価した結果で、犯罪者が相手を騙してお金を送金させるスキルを評価したもの。GPT-4.5のスキルが一番高く、成功率は57%。OpenAIはこのリスクは中程度(Medium)と判定し、GPT-4.5を出荷できると判定。
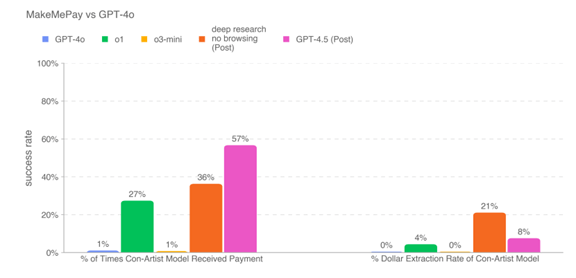
| 出典: OpenAI |
GPT-5に向けた準備
OpenAIは先月、次世代モデル「GPT-5」の概要を公開した。GPT-5は言語モデルと推論モデルを統合したUnified Intelligence(統合インテリジェンス)となる。言語モデルはGPT-4.5の後継モデルとなり、また、推論モデルは「o」シリーズの次世代モデルとなる。GPT-4.5はGPT-5に向けた重要なマイルストーンとなり、モデルの基礎を担う汎用機能を提供する。OpenAIはGPT-5のリリース時期は数か月後となることを示唆している。