Googleは最新モデル「Gemini 2.5」をリリースし、ベンチマークテストで二位に大きく差を付け、業界トップとなった。GoogleはGemini 2.5を最もインテリジェントなモデルと呼び、推論機能が強化され、プログラミングや複雑なタスクの実行で実力を発揮する。Gemini 2.5はDeepSeek R1の性能を大きく上回り、米国企業が再び実力を示した。

| 出典: Generated with Google ImageFX |
推考モデル
Gemini 2.5はGoogle DeepMindが開発した最新モデルで、推論機能が強化され、最もインテリジェントなモデルとなった。Google DeepMindはGemini 2.5を「Thinking Model(推考モデル)」と呼び、推考を重ね複雑な問題を解く構造となる。プログラミング機能が高く、複雑なコードをエラー無く生成することができる。
主要機能と開発手法
Gemini 2.5は高度な推論機能を持ち、情報を解析し、論理的な帰結を導き、情報に基づく意思決定を行う。Googleは推論機能の開発で、強化学習「Reinforcement Learning」や思考連鎖「Chain-of-Thoughts」の手法を用いてきた。この結果が前世代モデル「Gemini 2.0 Flash Thinking」に反映された。Gemini 2.5はこれをベースにポスト教育で機能が強化され、インテリジェンスが大きく向上した。
ベンチマーク結果
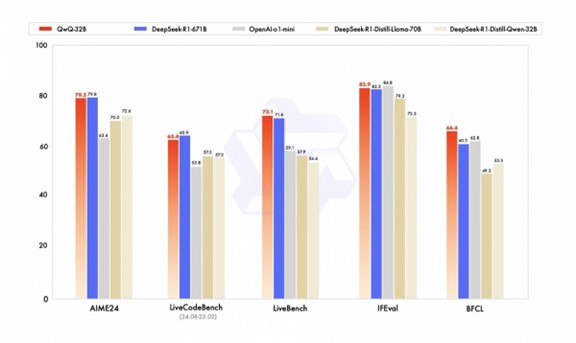
Googleはこのモデルを「Gemini 2.5 Pro Experimental」として製品化しこれを公開した。また、GoogleはGemini 2.5 Proのベンチマーク結果示し、高い性能をマークしたことをアピールした(下のグラフ)。これによると、Gemini 2.5 Proはコーディング、数学、科学など、推論機能が問われるタスクで高度な成績を示した。Gemini 2.5 Proの対抗機種はOpenAI 03-miniであるが、ほぼすべての項目で性能が上回った。また、DeepSeek R1に対しては全ての項目で性能が大きく上回った。

| 出典: Generated with Google Gemini 2.5 Pro |
利用環境
Gemini 2.5 ProをGoogleのAIスタジオ「Google AI Studio」で利用することができる(下の写真)。Google AI Studioは最新モデルGemini 2.5の他に、Gemini 2.0やGemini 1.5などを提供している。また、GoogleのオープンソースモデルGemma 3とGemma 2を使うことができる。AI StudioはAIモデルのサンドボックスで、ここでモデルを試験し、機能や性能を検証することができる。またGoogleは、AIクラウド「Vertex AI」でGemini 2.5を近日中に提供するとしている。

| 出典: Google |
プログラミング性能
実際にGemini 2.5 Proを使ってみるとプログラミングの機能が極めて高いことが分かる。プログラムを作成するにあたり、コーディングする必要は無く、Gemini 2.5 Proに言葉で指示するだけでコードを生成できる。例えば、人気ゲーム「テトリス」をJavaScriptでコーディングするよう指示すると、Gemini 2.5 Proはコードを生成し、その機能や使い方を説明する(上の写真)。生成されたコードを何も修正することなく、そのままJavaScript開発環境「p5.js」で実行することができる(下の写真)。
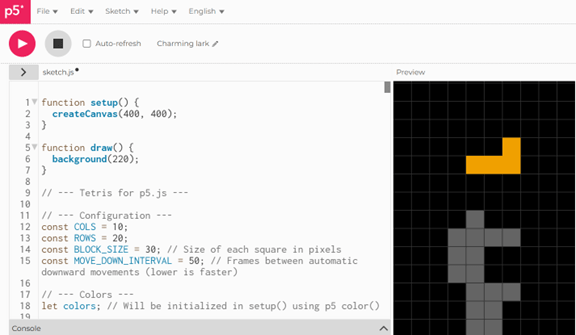
| 出典: p5.js |
ソフトウェア開発機能
Gemini 2.5 Proはソフトウェア開発における強力なツールとなり、ウェブアプリケーションやAIエージェントの開発で威力を発揮する。Gemini 2.5 Proはグラフィカルなインターフェイスのプログラムを得意とし、ウェブサイトやウェブゲームの開発で使われる(下の写真、Gemini 2.5 Proで簡単にインタラクティブなグラフを生成できる)。また、AIエージェントの開発が急速に進んでおり、Gemini 2.5 Proは人間に代わり複雑なプログラミングを実行する。Gemini 2.5 Proは実社会のエンジニアリングで役に立つモデルとして設計された。

| 出典: Google |
コーディングの品質
Gemini 2.5 Proを使うと、最低限のプログラミングのスキルで、コードを生成できる。プロンプトにプログラムの概要や使用する言語を入力するだけで、Gemini 2.5はコードを出力する。多くの推論モデルがコーディング機能を備えているが、Gemini 2.5の機能が最も洗練されているように感じる。Gemini 2.5はワンショットでエラーの無い高品質なコードを生成する。
バイブコーディング
言葉だけでAIモデルを使ってコーディングする手法は「バイブコーディング(Vibe Cording)」と呼ばれ話題となっている。いま、必要なプログラム言語は「Python」ではなく「英語(普通の言葉)」であるといわれている。コンピュータの知識が無くてもプログラミングできる時代が到来したとも言われている。しかし、実際にGemini 2.5 Proなどを使って言葉でコーディングしてみると、コードは自動で生成されるが、それを編集し運用するためには、それなりのスキルが求められる。コードの位置づけや、開発環境、実行環境など、プログラミングに関する基礎知識が必須となる。バイブコーディングはトレンディなコンセプトであるが、企業のプログラム開発で使うことができるのか、実社会でのベンチマークが必要となる。