OpenAIはウェブサイトのデータを読み込まない機能を公開した。OpenAIは「GPTBot」というクローラーで世界のデータを収集している。クローラーがウェブサイトにアクセスし、掲載されているコンテンツを読み込む。収集したデータは、ChatGPTなどの生成AIの教育で使われる。しかし、OpenAIは制作者の許諾を得ることなくデータをスクレイピングしており、社会問題となっている。これに対しOpenAIは、クローラーが個人や企業のデータを読み込むことを抑止するオプションを開示した。GPTBotの機能を「オフ」にすることで、個人や企業のコンテンツを守ることができる。

| 出典: OpenAI |
GPTBotとは
「GPTBot」とはクローラー(Crawler)で、これがウェブサイトにアクセスし、掲載されているテキストなどを読み込む(Scrape)。収集したデータはデータセットとして保存され、GPT-4などの言語モデルを教育するために使われる。言語モデルは大量のデータで教育すると機能が向上することが分かっており、いかに多くのデータを収集するかがAI開発の勝敗を分ける。
OpenAIの運用指針
OpenAIはこの手法でウェブサイトのデータを収集しているが、その運用は倫理的に実行していると主張する。GPTBotは有料サイト(Paywall)に掲載されているデータは収集していない。また、個人情報が掲載されているサイトは、プライバシー保護のため、データは収集を抑止している。OpenAIは既に大量のデータを保有しているが、それを最新データで更新するために、GPTBotが定期的にサイトからコンテンツを収集している。
著作権問題
OpenAIはGPTBotを倫理的に運用していると主張するが、著作権で保護されているデータが収集され、重大な社会問題となっている。著者は、OpenAIは許諾を得ないでデータを収集し、これを言語モデルの教育で使っているとして、著作権侵害で提訴した。また、これに先立ち、ChatGPTとDALL-Eはアルゴリズム教育で個人情報が使われているとして、OpenAIは集団訴訟を受けている。
GPTBotの機能を停止
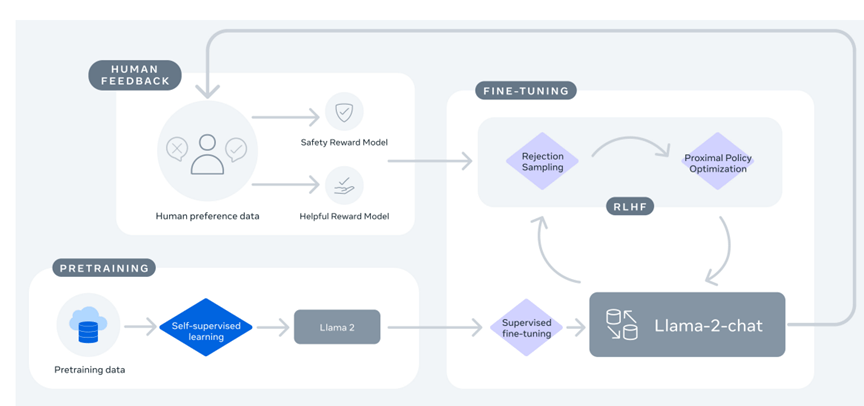
データ収集に関する問題が相次いで指摘されるなか、OpenAIはGPTBotがウェブサイトのデータの収集を中止するオプションを公開した。これはウェブ管理者向けのツールで、GPTBotの機能をオフにして、データ収集を停止させる。具体的には、ウェブページのファイル「robots.txt」に、下記のコマンド(左側)を記載すると、GPTBotはデータ収集を停止する。また、この機能をディレクトリ毎に設定することもできる。更に、OpenAIはGPTBotのIPアドレス(右側)を公開し、ファイアウォールでこれをブロックすることで、クローラーがサイトにアクセスすることを禁止する。

| 出典: OpenAI |
今までに収集されたデータは
このオプションを使うことで、コンテンツ制作者はウェブサイトに掲載しているデータを守ることができるが、考慮すべき点は少なくない。その一つが過去に収集されたデータで、これを消去する手段はない。OpenAIは、既に、ウェブサイトから大量にデータを収集し、これをベースにChatGPTなどを開発した。言語モデルのアルゴリズムは、個人や企業のデータを学習しており、これを白紙に戻すことはできない。
オープンソースのデータセット
もう一つがオープンソースのデータセットである。最新版のデータセットは「The Pile」と呼ばれ、英語を中心にウェブサイトの情報を集約している。世界最大規模のデータセットで、オープンソースとして公開され、企業や団体が生成AIの開発で利用している。先月、Metaが生成AI最新モデル「Llama 2」を公開したが、アルゴリズム教育でThe Pileが使われた。The Pileはコンテンツ制作者の許諾を得ることなく、サイトからデータが収集され、これが一般に公開され、Meta以外に多くの団体が利用している。
GPTBotに関する評価
GPTBotの発表と同時に、多くのサイトはコンテンツを保護するために、「Disallow」のオプションを導入した。先端情報を発信しているサイトを中心に適用が広がっている (下のイメージ、ニュースサイト「The Verge」はGPTBotのアクセスを禁止、シェイドの部分)。一方、CNNなどニュースサイトの多くはこのオプションを導入しておらず、企業はOpenAIのデータ収集にどういうポジションを取るのか注視していく必要がある。
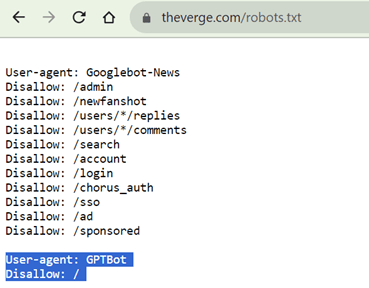
| 出典: The Verge |
検索エンジン vs 生成AI
Googleもクローラー「Googlebot」を使って、世界のウェブ情報を収集し、検索サービスで利用している。検索エンジンのケースでも、同じ議論が起こり、Googleは著作権を侵害しているとして訴訟された。しかし、Google検索エンジンは著作物の一部だけを使っており(Snippet)、これは「フェアユース(Fair Use)」であり、著作権侵害には当たらないと判定された。一方、OpenAIのケースでは、著作物や個人情報がAI教育で使われ、アルゴリズムがこれを学習し、学んだ内容を出力する。このケースは著作権を侵害しているのかどうか法廷の場で争われる。検索エンジンと生成AIではデータの利用法が異なり、新たな基準が必要となる。