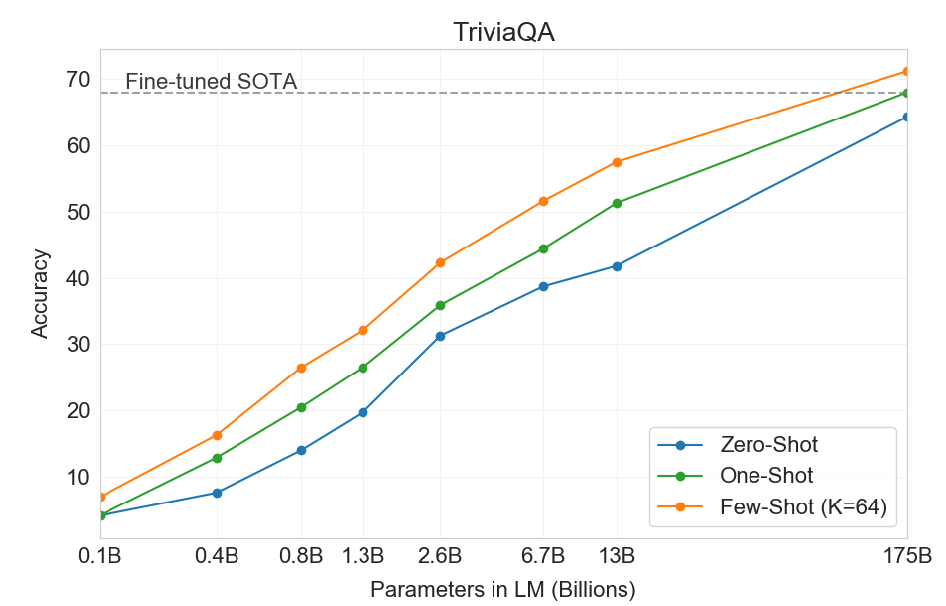
コロナの感染拡大でネット証券「Robinhood(ロビンフッド)」の会員数が急増している。アプリはお洒落なデザインで使いやすく、手数料はゼロで、個人の株式投資への敷居がぐんと下がった。手数料ゼロで利益を出せるのは訳があり、その背後で高度な情報通信技術が使われている。会員の注文は極めて短時間で決済できる超高速取引で処理され、これが収益の源泉となっている。

| 出典: Robinhood |
Robinhoodとは
Robinhoodはカリフォルニア州メンロパークに拠点を置く新興企業で証券取引のプラットフォームを提供している。Robinhoodは手数料ゼロのネット証券として2015年に事業をスタートし、ディスラプターとして証券取引ビジネスを一新した。ミレニアル世代を中心に人気が沸騰し、2020年には会員数が1300万人を超えた。
人気の秘密
Robinhoodの人気の秘密は証券取引数料が無料であることと、アプリのデザインが若者世代のテイストにマッチしていることがあげられる。白をベースとしたシンプルなデザインで、フレッシュな印象を受ける(下の写真)。今までのフィンテックアプリとは異なり、操作性も大きく向上した。更に、0.1株から購入できるため初心者でも安心して取引できる。

| 出典: Robinhood |
アプリ利用方法
Robinhoodはスマホアプリから利用する。最初に、会員登録のプロセスで個人情報などを入力し、銀行口座をリンクする。株を購入するときは銘柄を指定し、株数と単価とオプションを指定する。例えば、テスラ「TSLA」1株を330ドルでMarket Orderで購入するなどと指定する。このほかに、Limit Orderを指定すると条件を満たす価格で購入できる。
ビジネスモデル
Robinhoodは利益を得る仕組みを説明している。それによると、株式やオプションの手数料はゼロであるが、信用取引口座(Margin Account、Robinhoodから資金を借りて投資する口座)は有償で、会員は手数料(5ドル/月)と金利(年率5%)を支払う。また、Robinhoodは会員の余剰現金を貸付事業に展開している。これらがRobinhoodの収益を構成すると説明している。
もう一つのモデルが存在
これだけではなく、Robinhoodは「Payment for Order Flow」と呼ばれる手法で収益をあげていることが判明した。Robinhoodはこのモデルについては公開しておらず、証券取引委員会(Securities and Exchange Commission)が捜査に乗り出した。Payment for Order Flowは合法的な手法であるが、Robinhoodはこの事実を会員に公開していなかった。これが情報開示義務違反に該当する可能性があるとされる。
Payment for Order Flowとは、顧客の注文をブローカー間で超高速で取引し、利益を上げる手法を指す。Robinhood会員が株式やオプションを発注すると、これがそのまま証券取引所で売買されるのではなく、ブローカー(Market Maker)に渡る。Market Makerとは金融サービス企業で、お互いに買い値(Bid)と売り値(Ask)を提示し、相対取引を実行する機関を指す。Market MakerはRobinhoodからの注文を受け、他のMarket Makerと取引し、売り買いの幅(Bid-ask spread)で利益を上げ、その後、注文の処理結果をRobinhoodに返す。
Payment for Order Flowの流れ
例えば、Robinhood会員がTesla株を330ドルで買う注文を出すと、それがMarket Makerに渡る。Market Makerは他のMarket Makerが提示する価格をスキャンし、好条件の提示価格を見つける。例えば、Tesla株を他のMarket Makerから329ドルで買い、それをRobinhoodに330ドルで売り、1ドルの利益を上げる。
| 出典: Robinhood |
Robinhoodが利益を得る仕組み
RobinhoodはMarket Makerから利益に応じた手数料を受け取り、これがRobinhoodの利益となる。SECの資料によると、Robinhoodは2020年4月-6月期にMarket Makerから1億8026万ドルの手数料を受け取っている。これがRobinhoodの収益を支え、手数料無料でネット証券を運営できる理由となる。
Market Makerと高速取引
Robinhoodは提携しているMarket MakerはCitadel SecuritiesやVirtu Financialなどであることを公開している。これらは証券取引を極めて短時間で実行できる高速取引(High-Speed Trading)と呼ばれるシステムを構築し事業を展開している。トランザクションを超高速で実行し、他社より有利な条件で証券を売買し、これがPayment for Order Flowが成立する基盤となる。
他のネット証券も利用
Payment for Order FlowはRobinhoodだけでなく、他のネット証券も利用しており、業界では取引モデルとして定着している。E-TradeやTD AmeritradeはRobinhoodに追従して証券取引手数料をゼロとしたが、これらネット証券もPayment for Order Flowを使って利益を上げている。
Robinhoodの特殊性
ただ、Robinhoodが受け取る手数料が他社に比べて高いことが議論となっている。Robinhood会員は株取引を始めたばかりのアマチュアが多く、これが高い手数料に繋がっているとの見方もある。プロの投資家と違いアマチュア投資家は甘い条件で取引を発注するので、スプレッドが大きくなり、Market Makerが利益を上げやすい構造になる。Robinhoodが投資家初心者を勧誘する理由はここにある。

| 出典: Robinhood |
ネット証券の新たなビジネスモデル
GoogleやFacebookをタダで使えるが、その背後で個人情報が集められ、広告収入に結び付いていることを消費者は理解している。ネット証券も同様に、タダで株を売買できる代わりに、利用者の注文から利益が絞り出されることを理解する必要がある。この手法が倫理的でないとの議論もあるが、ネット証券の新しいビジネスモデルになっている。
ネット証券の新たなイメージ
Robinhoodの功績はミレニアル層など若い世代に投資の魅力を説いたことにある。若者はリーマンショックなどを経験し、株式投資に消極的な世代とされてきた。Robinhoodはこれら世代を対象に、ブログ「Snacks」で株式市場の動向を発信している(冒頭の写真)。食べやすいスナックという意味があり、複雑な政治・経済情勢を消化しやすい形で解説する。ポッドキャスト「Snacks Daily」はこれをヒップホップな音楽に乗せて若者に語り掛ける。この軽快さがRobinhoodの顔となり、アマチュア投資家の案内人として資産形成を支援する。