OpenAIは最新の推論モデル「o3」と「o4-mini」をリリースした。OpenAIは言語モデル「GPTシリーズ」と推論モデル「oシリーズ」を運用しているが、「o3」と「o4-mini」は後者の最新製品となる。最新モデルは推論機能が大幅に強化され複雑なタスクを実行する。推論機能では思考の鎖「Chain of Thought」という方式で教育され、複雑な問題をステップごとに思考し最終解を導き出す。最新モデルは、思考の過程にテキストだけでなくイメージを組み込むことができ、インテリジェンスが格段に向上した。

| 出典: Generated with OpenAI o3 |
推論モデル製品ライン
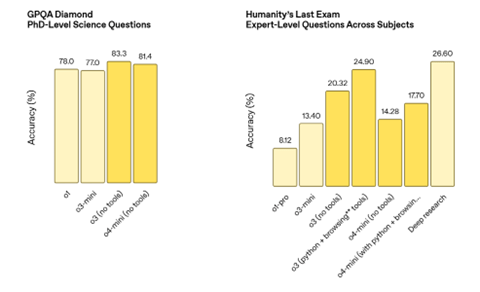
OpenAIは推論モデル「o3」と「o4-mini」をリリースした。o3はフルサイズのモデルで推論機能が極めて高く、難解な問題を解決するために使われる。o4-miniは小型の推論モデルで、実行時間が短く、プログラミングなどで実力を発揮する。両者は性能が拮抗しているが、難解な問題を解く技能についてはo3が高い能力を発揮する。(下のグラフ右側、業界で最難関のベンチマーク試験でo3は高度な能力を発揮)
| 出典: OpenAI |
マルチモダルな推論機能
OpenAIが公開したモデル情報を読むと推論機能が強化されたことが分かるが、実際に、モデルを使ってみるとそのインテリジェンスの高さに驚愕する。特に、推論機能をイメージに適用したケースでは、想像以上の機能を発揮し、マルチモダルの推論機能の高さを実感する。推論モデルが視覚を持ち、人間のインテリジェンスに最接近した。
o3を使ってみる:次の停車駅は
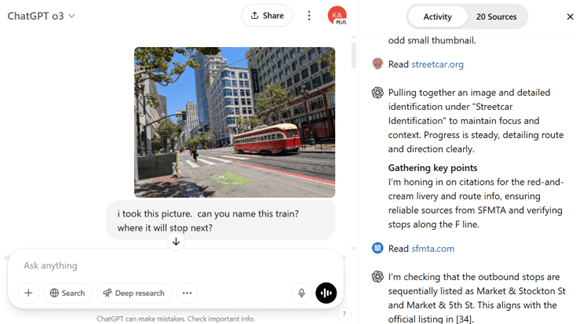
o3はChatGPTのインターフェイスでブラウザーから利用できる。o3はマルチモダルの機能と外部ツールを使用する機能が搭載され、回答できる範囲が広がった。イメージに関する解析機能が格段に向上し、入力した写真について難しい問いに回答することができる。o3にサンフランシスコ市内で撮影した路面電車の写真をアップロードし、「次の停車駅はどこか」と質問すると、これに正確に答えることができた(下の写真)。
| 出典: OpenAI |
イメージ解析の手法
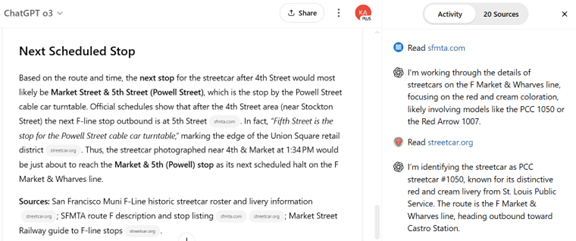
o3は思考の過程を「Chain of Thought」として出力し、解析の手法を理解することができる(下の写真)。これによると、o3は写真の中で路面電車の背後に写っているホテル(Hotel Zelos)から、ここはサンフランシスコのマーケットストリートであると判断。マーケットストリートを走る路面電車の路線は「Route F」で、南向きに走行しており、次の停車駅は「Market & 5th (Powell)」と判定した。o3は推論の過程で、インターネット上の20のサイトにアクセスし、必要な情報を取集した。その中で、サンフランシスコ運輸局(San Francisco Municipal Transportation Agency)のサイト(右カラム)で路線に関する情報を収集し停車駅を特定した。
| 出典: OpenAI |
o3を使ってみる:このレストランは
o3にレストランで撮影した料理の写真を入力し、この場所を質問すると、o3はこれも正しく回答した(下の写真)。レストランの料理の写真から、想定されるレストランを特定し、それを絞り込んで最も確からしい候補を回答した。このケースでも、o3の思考の鎖(Chain of Thought、右側のカラム)を読むと、問題解決の手順を理解することができる。
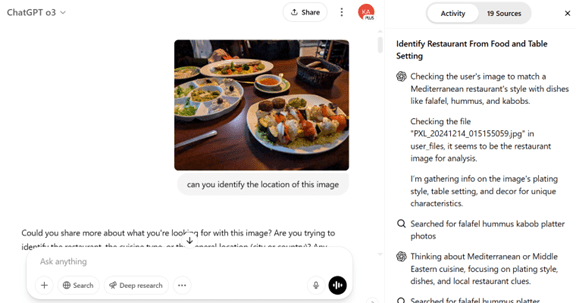
| 出典: OpenAI |
レストランを特定する
o3はテーブルに並べられた料理の写真から、これは「地中海・中近東料理」であることを特定した。また、料理のスタイルから、中近東のグリル形式の料理に絞り込んだ。更に、o3は旅行ガイドサイト「Tripadvisor」などにアクセスして、候補のレストランを複数提示した。そのトップが正解の「Café Baklava」でo3は正しく回答にたどり着いた。
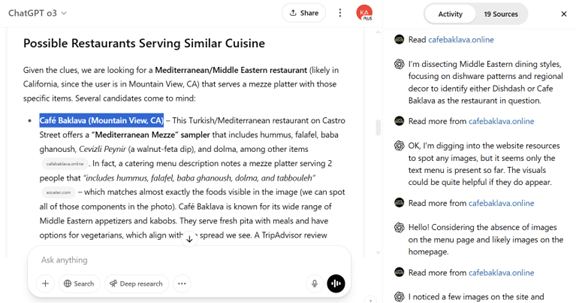
| 出典: OpenAI |
o3を使ってみる:フェイクイメージの検知
o3はフェイクイメージを検知するスキルを持っていることが分かった。o3にxAI Grok 3で生成したフェイクイメージを入力し、その真偽を判定するよう指示すると、正しく回答することができた。トランプ大統領と大谷選手が談話している合成写真に関し、o3はこれはフェイクイメージであると結論付けた(下の写真)。従来のイメージ判定AIは、ビジュアルな側面からイメージが改造された手掛かりを見つけるが、o3は多角的なアプローチを取り、FBIの捜査官ののように、ビジュアルな観点と論理的な考察を重ね総合的に判定する。

| 出典: OpenAI |
フェイクを見分ける技法
このケースでは、イメージ解析の側面からは、トランプ大統領がビール瓶を握っている指の形が不自然で、o3はAIで生成する際の特性であると判定した。また、トランプ大統領のライフスタイルを解析し、大統領はアルコールを飲まないことを公表しており、このイメージはこのシナリオに反していると判断。また、ホワイトハウスのビジネス慣習の観点からは、重要なイベントはプレスリリースとして公開され、複数の写真が添付されるが、写真が単独で公開されている点や、主要メディアがこれを報道していないなど、不自然な点が多いとし、総合的な見地からフェイクイメージと断定した(下の写真)。

| 出典:OpenAI |
IQテスト
o3はリリースされているAIモデルの中で最も高いIQ(Intelligence Quotient、知能指数)をマークした。AIの技術動向をモニターする団体「Maximum Truth」はAIモデルのIQ試験を実施し、その結果を公表している(下のグラフ)。それによると、o3のIQは136で業界トップの成績を達成した。二位はGoogle Gemini 2.5 Proで128をマークした。同時に発表されたo4-miniは118で五位の成績となる。このIQテストは「Mensa Norway」という方式で、人間の平均的なIQは85から114のレンジとなる。o3のIQが136とは、人間の上位1%の知能を持つことを意味し、天才(Moderately Gifted)であると定義される。AGIの定義は確定していないが、o3はこのレンジに入っているとの解釈もある。
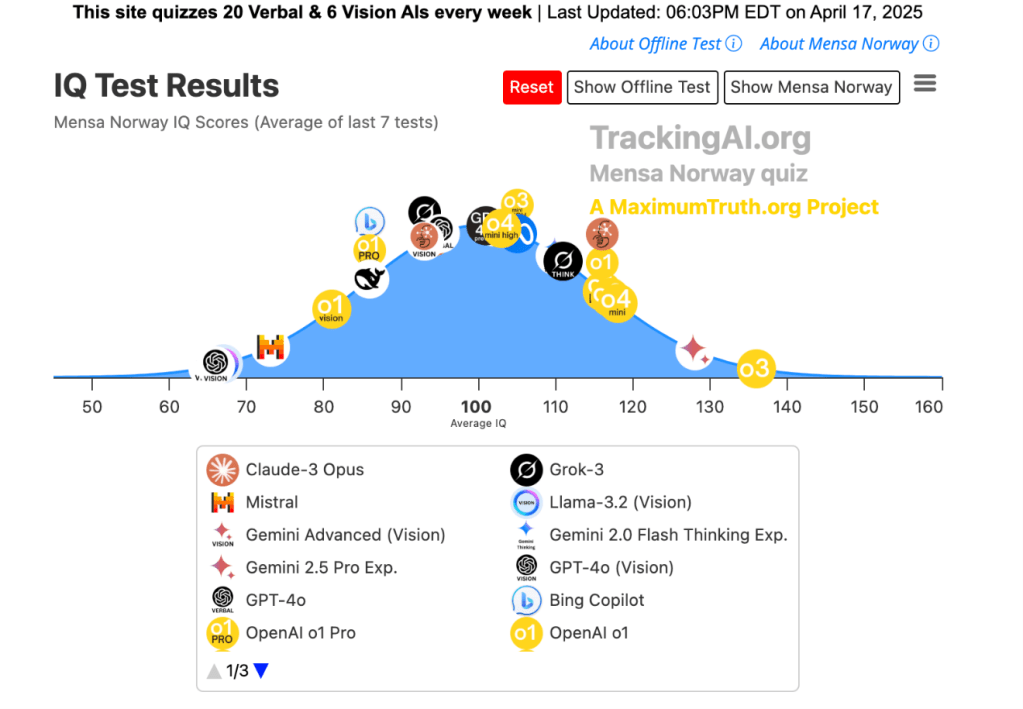
| 出典:OpenAI |
インファレンス・コンピューティング
o3は言語モデルとは異なり、推論機能を実行するためには、計算時間が長くなる。上述の路面電車の停車駅を判定するケースでは、計算時間は9分20秒を要した。言語モデルはほぼリアルタイムで回答を生成するが、推論モデルでは計算時間が20倍から100倍長くなる。これはインファレンス・コンピューティングと呼ばれ、実行時のプロセスで計算資源が必要となる。
スケーリング
OpenAIなど開発企業の観点からは、インファレンス・コンピューティングで大規模な計算環境が必要となり、運用コストが増大する。利用者の観点からは、AIモデルの使用料が上がり、出費が増大することになる。o3は「ChatGPT Plus(月額20ドル)」のサブスクリプションが必要で、かつ、利用件数は50件/週に限定される。制限なしに利用するためには「ChatGPT Pro(月額200ドル)」のサブスクリプションを購入する必要がある。利用者としては負担が増えるが、AIビジネスの観点からは、推論モデルの性能がスケーリングし、事業拡大が見込まれる。市場が再び大きく拡大するチャンスとなる。