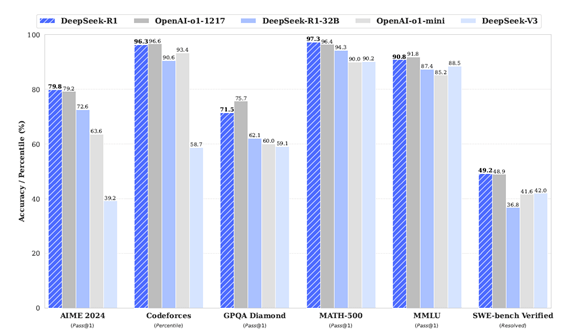
スタンフォード大学の研究グループは推論モデル「s1」を開発し、その性能はOpenAIの「o1-preview」を超えたと発表した。開発費は極めて低く、高品質な教育データを使うだけで、高度な推論モデルを開発できることを証明した。低価格で高度な推論モデルを開発できた理由は、「知識抽出技術(Distillation)」にあり、GoogleのGemini 2.0の知識をs1に移転した。Distillationは合法的な手法かどうか議論が続いているが、s1は簡単に推論モデルを開発できる手法を開発し、これをオープンソースとして公開した。

| 出典: San Francisco Peninsula |
推論モデルの開発
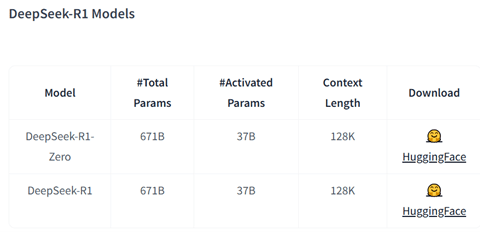
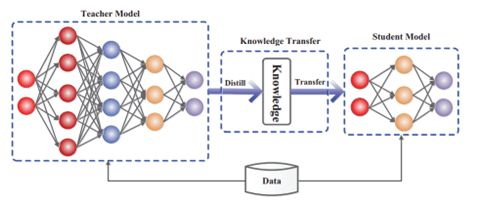
スタンフォード大学は他の研究機関と共同で推論モデル「s1」を開発し、これをオープンソースとして公開した。言語モデルの性能が頭打ちになるなか、研究グループは実行時のプロセスを改良することで性能を向上させる「Test-time scaling」の手法でs1を生み出した。この手法で開発されたAIは推論モデルと呼ばれ、OpenAIの「o1」がその先駆けとなり、AI開発の新しいルートを切り開いた。一方、o1はクローズドソースで、モデルの構成などを理解することができない。このため、スタンフォード大学はオープンソースの手法で推論モデルを開発し、その技法を一般に公開し、研究成果をコミュニティと共有している。

| 出典: Adobe Generated with AI |
s1の構造と開発手法
s1はオープンソースの言語モデルをベースに、これを独自に開発したデータセットで教育することで、推論モデルを生成した。具体的には、Alibabaが開発した言語モデル「Qwen2.5-32B-Instruct」をベースとし、これをスタンフォード大学が開発したデータセット「s1K」で教育することで、推論モデル「s1」を生成した。「s1K」はタグ付きの教育データセットで、1,000のデータから構成される。僅か1,000件のデータで高度な推論モデルを生成した。また、教育の過程では「Budget Forcing」という手法を導入し推論機能を向上した。Budget Forcingとは、s1に、“しっかり考察することを指示”する機能で、モデルは回答を再考することで、正解の確度を高める。また、反対に、推論を打ち切る機能としても使われる。教育データ「s1K」と教育方法「Budget Forcing」がこの研究のイノベーションとなり、OpenAIのo1-previewの性能を上回った(下のグラフ)。

| 出典: Niklas Muennighoff et al. |
推論モデル教育データ
スタンフォード大学は推論モデルを教育するデータセット「s1K」を開発した。言語モデルの教育とは異なり、推論モデルを教育するデータは「Triplets」と呼ばれ、三つの要素から構成される。三要素を含むデータが基本単位となり、言語モデルをファインチューニングし、推論モデルを生成する。s1Kの構成要素は(下の写真):
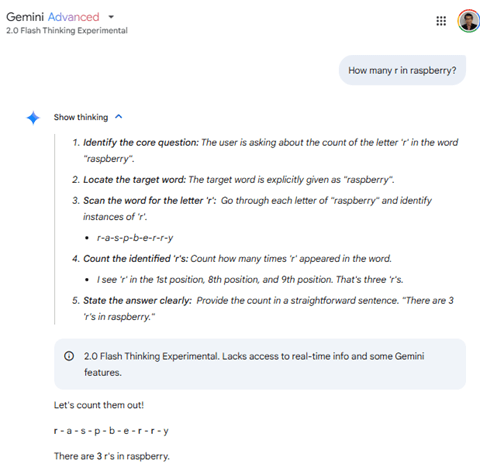
- 質問(Question):モデルに入力する質問や命令 (例:Raspberryに含まれるrの数は)
- 推論過程(Reasoning Trace):質問に対するモデルの考察過程を出力したもの (回答を検証する過程など)
- 回答(Response):モデルが考察の結果導き出した最終回答 (例:3)

| 出典: Niklas Muennighoff et al. |
推論モデルの開発方法
スタンフォード大学は教育データセット「s1K」を知識抽出技術「Distillation」の手法で生成した。教育データは、数学の問題を中心に、生物学や物理学など幅広い領域をカバーし(下の写真)、59,029の事例を収集した。これを、品質や難度などに応じて、1,000件に絞り込んだ。これが「s1K」で、精選された教育データが生成された。このs1Kをファインチューニングの手法(Supervised fine-tuning)でモデルを教育しs1を生成した。その際に、「Budget Forcing」の手法を導入し、モデルに解を再考させる命令(Wait、上の写真、赤字の部分)を挿入し、回答の品質を向上した。
| 出典: Niklas Muennighoff et al. |
Distillationの技法
スタンフォード大学は教育データを生成するためにGoogleの推論モデル「 Gemini 2.0 Flash Thinking Experimental」を使った。このモデルはGoogleの推論モデル最新版で、クラウド経由でAPIからアクセスした。このモデルに質問を入力し、その推論過程(Reasoning Trace)と最終回答(Response)を記録し、これを教育データとして利用した。これはDistillationという手法で、Gemini 2.0 Flash Thinking Experimentalの知識を収集し、これをs1に転移することで、短時間で高度な推論モデルを生成した。(下の写真、実際にGemini 2.0 Flash Thinking Experimentalに質問「How many r in raspberry?」を入力すると、推論過程と最終回答が示される。s1のケースではこれを教育データとして使用した。)
| 出典: Google |
Distillationの手法に関する議論
GoogleのGemini 2.0 Flash Thinking Experimentalを使うことで、短時間に高品質な教育データを整備することができた。一方、GoogleはGemini 2.0 Flash Thinking Experimental などAIモデルを使って競合モデルを生成することを禁止している。企業はDistillationを禁止するものの、その検知は難しく、この手法で多くのモデルが生まれている。スタンフォード大学は論文の中でGemini 2.0 Flash Thinking Experimentalを使ったことを明示しているが、モデルの殆どはその開発手法を明らかにしていない。Distillationは知的財産のコピーなのか、法的解釈がグレイなエリアであるが、この手法により推論モデルの開発が急進していることも事実である。