Anthropicは3月4日、大規模言語モデルの最新版「Claude 3」を投入した。Claude 3は主要ベンチマークテスト全てでOpenAIのGPT-4を上回り、業界で最も高度なモデルとなった。特に、推論機能や数学の問題を解く能力が強化され、インテリジェンスが大きく向上した。同時に、Anthropicはモデルの安全性を最重視しており、Claude 3は最も倫理的な生成AIとなる。

| 出典: Anthropic |
Claude 3の概要
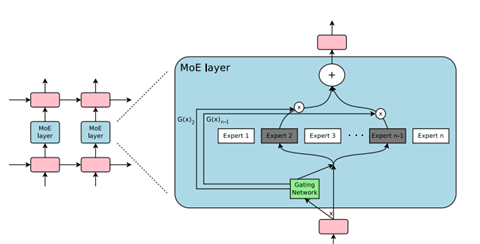
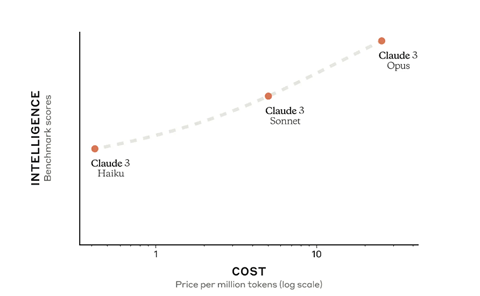
Anthropicは第三世代目となる大規模言語モデル「Claude 3」をリリースした。Claude 3は異なるサイズで構成され、最大モデル「Opus」、中規模モデル「Sonnet」、小規模モデル「Haiku」の三つの構成を提供する。ユーザは、インテリジェンスや実行速度やコストを勘案し、最適なモデルを選ぶことができる(下のグラフ)。OpusとSonnetはクラウドやAPI経由で公開され、また、Haikuは近日中にリリースされる。
| 出典: Anthropic |
Claude 3 OpusはGPT-4を上回る
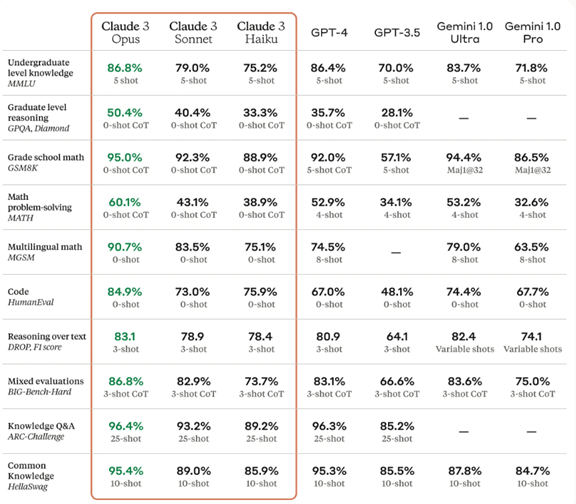
Claude 3最大構成のOpusは、主要ベンチマークテストの全ての項目でOpenAIのGPT-4の性能を上回った(下のテーブル)。基本的なベンチマーク「MMLU」(大学生レベルの知識)でGPT-4を上回り、業界トップの座を奪還した。特に、難度の高いベンチマーク、「GPQA」(大学院生レベルの知識)や「GSM8K」(数学の基本機能)や「MATH」(数学の高度な機能)を試験するベンチマークで好成績を上げた。Claude 3は理解する能力や柔軟性で人間の能力に迫り、Artificial General Intelligence(AGI)への第一歩となる。
| 出典: Anthropic |
ガードレール機能
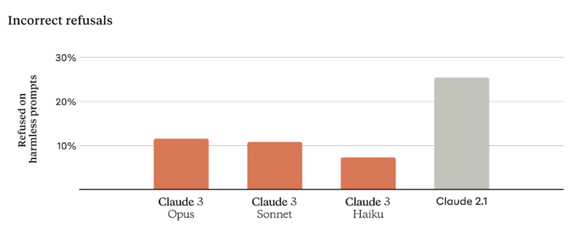
Claude 3はバイアスや危険情報を抑止するため、安全装置「Guardrails」が実装されている。ガードレールはファイアウォールとして機能し、入力されたプロンプトを解釈し、不適切な指示に対しては回答を出力することを抑止する構成となっている。一方、ガードレールは安全性を過度に重視するため、正当なプロンプトに対しても回答を拒絶し、モデルの能力が低下する問題を抱えている。このため、Claude 3はプロンプトを理解する能力が向上し、前世代のモデルClaude 2に比べ、回答を不当に拒否する率を大幅に低下させた(下のグラフ)。
| 出典: Anthropic |
コンテクスト・ウインドウ
Claude 3は入力できるプロンプトのサイズ「コンテクスト・ウインドウ」を20万トークンとして提供する。最大で100万トークンを処理する能力があり、顧客の要望に応じてコンテクスト・ウインドウを拡大する。Claude 3の特徴は、入力された大規模なデータの中で、特定の情報を正確に思い出す機能が高いことにある。これは「Needle In A Haystack」と呼ばれ、20万トークンの中の情報を正確に覚えている(下のグラフ、濃い緑色の四角が正確に記憶している個所を示す)。
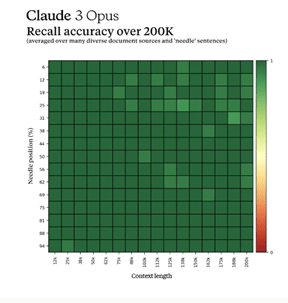
| 出典: Anthropic |
最も安全な言語モデル
Anthropicは高度な言語モデルを開発するだけでなく、モデルが社会の倫理に沿い、安全な機能を提供する。Anthropicは専任のチームが安全性を検証し、モデルが虚偽情報や児童ポルノや生物兵器情報などを出力することを抑止する。また、Anthropicはモデルが準拠すべき憲法「Constitution」を制定し、アルゴリズムはこれを学習し、社会の倫理に準拠した挙動を示す。この技術は「Constitutional AI」と呼ばれ業界で注目されている。

| 出典: Anthropic |
Claude 3 Opusを使ってみる
Claude 3は数学の問題を解く機能が向上し、業界でトップの成績をマークした。ベンチマーク「Math」ではGoogleのGemini Ultraが記録を保持していたが、Claude 3 Opusはこの成績を大きく超え、トップの座についた。Claude 3 Opusに数学の問題を入力すると、モデルはステップごとに問題を解説し、最終解を導き出す。(下の写真、数式のイメージを入力すると、モデルはこれは二次方程式であると判定し、その使い方を解説する)

| 出典: Anthropic |
GPT-4が追い越される
OpenAIが足踏み状態で、GPT-4の性能を上回るモデルの登場が続いている。GoogleはGemini Ultraを、AnthropicはClaude 3 Opusを投入し、これらがGPT-4の性能を上回った。GPT-4は一年前に投入されたモデルであり、他社がこれに追い付いた形となった。OpenAIは3月8日、取締役会のメンバーが決まり、Sam Altmanが復帰することとなった。これで経営体制が整い、OpenAIは研究開発を再開し、GPT-4の次のモデルを投入すると噂されている。大規模言語モデルの競争は新たなステージを迎える。