Googleは2月15日、生成AIの次世代モデル「Gemini 1.5」を公開した。昨年12月に、初代モデル「Gemini 1.0」をリリースしたが、Gemini 1.5はその後継モデルとなる。Gemini 1.5はアーキテクチャが改良され、処理効率が格段に向上した。また、入力できるデータ量が大きく拡張され、最大で100万トークンを処理できる。Googleは会社の威信をかけて、OpenAIのGPT-4に対抗するモデルの開発を加速させている。

| 出典: Google |
Geminiシリーズ
Googleは昨年12月、生成AI次世代モデル「Gemini」を発表している。Geminiはファウンデーションモデルで、高度な言語機能の他に、イメージやビデオやオーディオを理解するマルチモダル機能を備えている。Geminiは三つのサイズから構成される:
- Gemini Ultra:最大構成モデルでデータセンターで使われ複雑なタスクを実行する。チャットボット「Gemini Advanced」のエンジンとして使われている。
- Gemini Pro:中規模構成モデルで幅広いレンジのタスクを実行する。チャットボット「Gemini」のエンジンとして使われている。
- Gemini Nano:最小構成のモデルでスマートフォンで稼働する。ハイエンドスマホ「Pixel 8 Pro」に搭載されている。
今回発表されたのは「Gemini Pro 1.5」
今回の発表は中規模構成モデルの最新版「Gemini Pro 1.5」となる。Gemini Pro 1.5はアーキテクチャが大きく改良され、ハイエンドモデル「Gemini Ultra 1.0」と同等の性能を示す。更に、入力できるデータ量が拡大され、最大100万トークンを処理できる。Gemini Pro 1.5の主な改良ポイントは:
- アーキテクチャ:Mixture-of-Experts (MoE)という方式を実装
- コンテクスト・ウインドウ:入力できるトークンの数を100万に拡大
アーキテクチャ:Mixture-of-Experts (MoE)
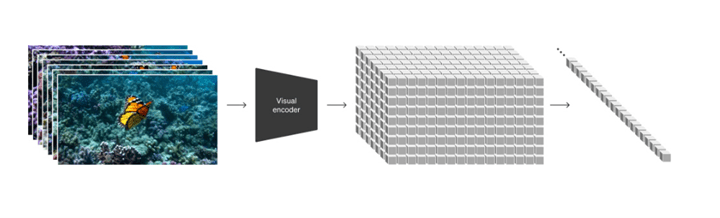
Gemini Pro 1.5の性能が大きく向上した理由は、アーキテクチャとして「Mixture-of-Experts (MoE)」を採用したことにある。Googleは早くからMoEの研究を進めており、この成果をGemini 1.5に適用した。MoEとはモデルを構成するネットワークの方式で、単一構造ではなく、複数の専門家「Expert」を持つ構成とする(下のグラフィックス)。入力された命令に対し、その分野の専門家が解答を生成する仕組みとなる。これにより、プロンプトに対しモデル全体を稼働させるのではなく、その一部のエキスパートが処理を実行するため、高速で効率的にインファレンス処理を実行できる。
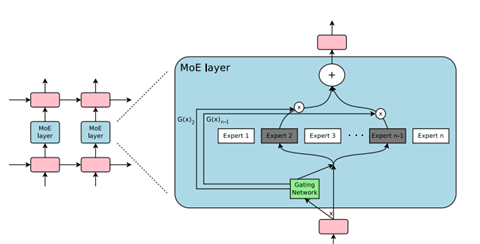
| 出典: Google |
コンテクスト・ウインドウ:100万トークン
コンテクスト・ウインドウ(Context Window)が大幅に拡大された。コンテクスト・ウインドウとは、モデルに入力できるデータのサイズを指す。Gemini Pro 1.5では、このサイズが100万トークンに拡張された。具体的には、テキストでは70万単語、ビデオでは1時間分の動画を処理できる。コンテクスト・ウインドウは、ワーキングメモリであり、この領域が大きいと一度に大量のコンテクストを処理できる。例えば、源氏物語の英訳「The Tale of Genji」の全体を読み込ませ、Gemini Pro 1.5はこの小説のに関する知識を習得し、研究者や読者からの多彩な質問に回答することができる。(下のグラフィックス上段:Gemini Pro 1.5のコンテクスト・ウインドウのサイズ、実際には1000万トークンまで処理できる、下段:GPT-4のコンテクスト・ウインドウは12万8000トークン)。

| 出典: Google |
利用方法
GoogleはGemini Pro 1.5をAIスタジオ「AI Studio」とAIクラウド「Vertex AI」で公開する。AIスタジオは生成AIモデルのプレイグランドで、異なるモデルを使ってその機能や性能を検証することができる。現在は「Gemini Pro 1.0」が公開されており(下のグラフィックス)、「Gemini Pro 1.5」は待ちリストに登録し、認可を得たユーザから利用できる状態となっている。
| 出典: Google |
Geminiの開発手法
GoogleはGeminiの開発を並列で進めており、「Gemini 1.0」はリリース済みで、先週「Pro 1.5」が公開された。これから「Ultra 1.5」が投入され、されに、並列して「Gemini 2.0」が開発されており、その公開も近いとされる。Googleはこの市場のトップを奪還するため、Geminiの開発を加速している。