トランプ大統領はホワイトハウス・ローズガーデンで、米国の関税を引き上げることを発表した。大統領は貿易相手国に「相互関税(Reciprocal Tariff)」を課すことで米国が再び豊かになる(Make America Wealthy Again)との見通しを示した。また、貿易相手国の関税率や非関税障壁を基礎データとし、自国の関税を引き上げたと説明した。日本には24%の関税が課されることになる。しかし、米国社会ではどのように関税率を算定したのか、その根拠について議論が広がっている。また、米国の市民生活では、物価が上昇し、iPhoneの価格が2,300ドル(345,000円)の時代になると不安感が増幅している。

| 出典: White House |
関税率算定の根拠に関する議論
ソーシャルメディアでトランプ政権が関税率を算定した根拠についての議論が広がっている。米国主要メディアは、関税率をリバースエンジニアリングして、「関税率=貿易赤字÷輸入額」としたと報じている(下のテーブル)。日本のケースでは、貿易赤字($68.5B)÷輸入額($148.2B) = 46%となる。一方、トランプ大統領はホワイトハウスでの発表会見で、貿易相手国に“優しい”政策を取り、関税率を半減すると説明した。そのため、日本への関税率は「46%÷2 = 約24%」となる。
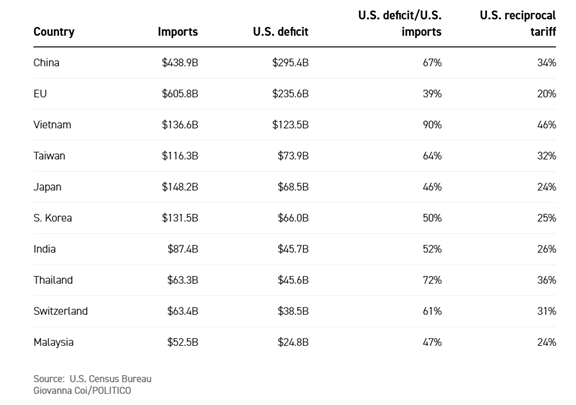
| 出典: Politico |
ホワイトハウスの見解
ホワイトハウスはメディアからの問い合わせを受けて、関税率算出の根拠となる資料を公表した(下の写真)。これはアメリカ合衆国通商代表部(Office of the United States Trade Representative)が作成したもので、相互関税(Reciprocal tariffs)の目的は、貿易相手国と貿易赤字のバランスを取るための政策であるとしている。税率は、相手国の関税と非関税を勘案して算定し、これにより相手国からの輸入量を低減し、長期的なバランスを保つことができるとしている。

| 出典: United States Trade Representative |
関税率算定の方式
通商代表部はこの中で、関税率算定のアプローチについて説明している(下の写真)。これによると、関税率は「(貿易赤字÷輸入額)÷(弾力性)」となり、メディアで議論されている方式と同じ考え方となる。ただ、「弾力性(Elasticity)」という係数が導入され、輸入品の関税率に対する変動率が加味された。弾力性とは、関税を上げた際の輸入量の減少の変動率を示すもので、弾力性が高い商品と低い商品がある。ジュエリーなど装飾品は関税率を上げると購買量が低減し、弾力性が高い商品となる。一方、半導体など社会インフラを構成するアイテムは、関税率を上げても購買量がそれほど低減しないで、弾力性が低い商品となる。ホワイトハウスは弾力性=1.0として算定し、大統領の“優しい政策”で弾力性=2.0とし、関税率を半減した。
計算方法
通商代表部が公開した関税率算定数式(下の写真最下部)の定義は:
- Δτᵢ: 貿易相手国(i)に対する関税率の変化(新関税率)
- ε: 貿易品の弾力性
- φ: 輸入価格への転移率
- mᵢ: 輸入総額
- xᵢ: 輸出総額
これらの記号で関税率を表すと次の通りとなる:
- 新関税率(Δτᵢ) =(貿易赤字(xᵢ – mᵢ )÷輸入額(mᵢ))÷(弾力性(ε * φ))

| 出典: United States Trade Representative |
関税率算定方式をAIで評価すると
この数式で関税率を算定することに関し、AIモデルにその妥当性について質問してみた。Gemini 2.5に上述の方式を入力し、その評価について質問すると、この数式は「単純化しすぎており妥当な方式ではない」との回答が返ってきた(下の写真)。この方式は二国間における関税率を算定するための簡便な法式であるが、基本的に間違っていると判定した。貿易赤字は関税率だけで決まるものではなく、投資レベルや為替レートなど複雑な要素が関連しており、これらを加味する必要があると説明した。

| 出典: Google |
関税率算定方式を尋ねると
Gemini 2.5に関税率を算定する方式を尋ねると、トランプ政権の方式は「単純すぎる手法で間違っている」と指摘し、国際社会で共通理解が確立されていないが、一般に使われている手法を解説した(下の写真)。これによると、関税率の算定では1)ダンピング課税(Anti-Dumping (AD) Duties)と2)相殺関税(Countervailing Duties (CVD))があり、そのコンセプトと計算式を解説した。関税率を世界全体に一律に算定することは不可能で、国ごとの要件を勘案し、二国間でこれを決定することが基本ルールとなる。

| 出典: Google |
トランプ政権の関税率早見表
トランプ政権の関税率の考え方に基づき、GPT-4oで関税率の早見表のコードを生成した。このコードを実行すると、米国の貿易相手国に対する関税率を可視化するグラフを生成できる。日本の場合は、日本からの輸入額と日本への輸出額を入力すると、関税率を算定する(下の写真)。ここでは、トランプ大統領が発表した”優しい関税政策”「弾力性 = 2.0」を使った。Gemini 2.5やGPT-4oを使うと、関税率に関する作業を自動化できる。社会生活で不安が広がる中、ホワイトハウスはこれらAIモデルを使って、国民に関税政策を分かりやすく伝えてほしいと感じた。
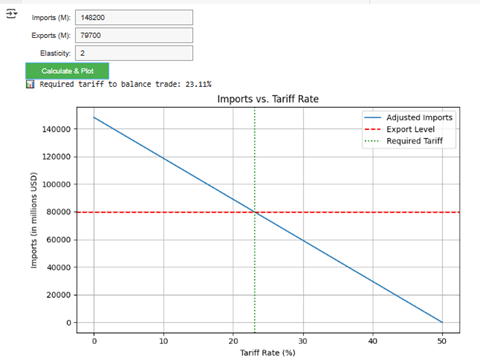
| 出典: Google CoLab Notebook |