OpenAIは企業向けのChatGPTを投入した。これは「ChatGPT Enterprise」と呼ばれ、セキュリティを強化したモデルで、AIアプリケーションを安全に運用できる。これに先立ち、ChatGPTを最適化する機能「Fine-Tuning」を公開した。企業は業務専用のモデルを開発し、アルゴリズムの挙動を制御する。大企業の80%がChatGPTを導入しており、開発競争の中心はエンタープライズ機能にシフトした。

| 出典: Adobe |
企業が生成AIの導入を加速
OpenAIは、先週、セキュリティとプライバー機能を強化した「ChatGPT Enterprise」を公開した。このモデルは企業がビジネスで利用できる品質で、高速版「GPT-4」にアクセスする機能など、処理速度がアップグレードされた。この背景には、企業が「GPTシリーズ」の導入を加速している事実がある。フォーチュン500企業の80%がChatGPTを使っており、ビジネスで使える品質と機能が求められている。
ChatGPT Enterpriseの機能
ChatGPT Enterpriseはこの要請に応えたモデルで、特に、プライバシー保護とセキュリティ機能が強化された。このモデルは利用者が入力するプロンプトを教育で使うことはなく、企業の機密情報がリークすることはない。また、モデルが使うデータは暗号化され外部からの盗聴を防ぐ構成となっている。具体的には、システム内のデータは「AES-256」で、交信データは「TLS 1.2+」で暗号化される。ChatGPT Enterpriseは業界の安全規格「SOC 2」に準拠し、安全にかつダウンすることなく運用できる(下のグラフィックス)。

| 出典: OpenAI |
チューニングして処理速度をアップ
これに先立ち、OpenAIはChatGPTを最適化する機能「Fine-Tuning」をリリースした。これは、ChatGPT (GPT-3.5 Turbo) 向けの機能で、モデルを業務に合わせて最適化し、処理スピードを上げる。ChatGPTは汎用的な対話モデルで、これを特定のタスクに応じて最適化することで、処理速度を高速化できる。最適化したChatGPTはGPT-4に匹敵する性能となる。
アルゴリズムの挙動を制御
実行速度を高速化する他に、業務を忠実に実行するよう、モデルの挙動を制御することができる。チューニングされたChatGPTは、脇道に逸れることなく、命令を忠実に実行する。プロンプトの指示に沿って、指定された形式で回答出力する。更に、モデルが出力する文章のトーンを設定でき、企業ブランドに沿ったChatGPTを生成できる。

| 出典: Adobe |
チューニングの手法
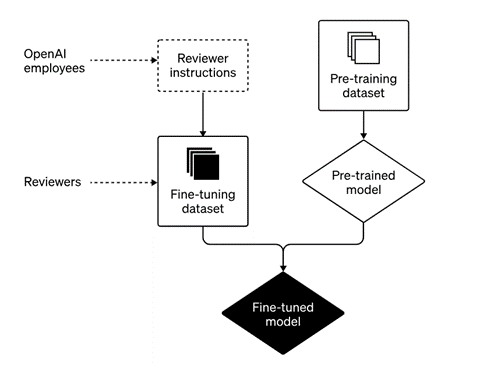
モデルの最適化は、ChatGPTに対話事例を示し、アルゴリズムがこれを学習するプロセスとなる。会話事例として、回答のスタイルやトーンやフォーマットなどを使うと、アルゴリズムがこれを学習する、また、業務の専門知識を盛り込むと、その分野のエキスパートモデルを生成できる。
教育データ
教育データは会話のサンプルを指定された形式で編集したものとなる。その代表が「Chat Completion」で、入力されたテキスト(プロンプト)に対しモデルが回答する。その際に、モデルの属性を定義することができる。例えば、モデルの属性を「皮肉なチャットボット」という設定に (下の事例、シェイドの部分)すると、この機能を持つChatGPTが出来上がる。これに続いて、対話事例を入力する。「フランスの首都は?」と問われると、モデルは「パリであるが、知らない人はいないはず」というように、皮肉な会話事例を教え込む。このような会話事例を50から100用意してモデルを教育する。

| 出典: OpenAI |
教育したモデルを運用
チューニングされたChatGPTは専用モデルとなり、企業はこれをビジネスで利用する。ChatGPTは教育された知識やスタイルを持っており、専門分野の質問に正確に回答することができる。また、ChatGPTは教育されたトーンで回答するため、企業ブランドを反映したチャットボットが生まれる。
モデルのサンプル
ChatGPTのチューニングを始める前に、企業はサンプルを使ってモデルの機能や属性を検証することができる。OpenAIはモデルのサンプル「Examples」を多数公開しており(下のグラフィックス)、これらを使って異なる機能や属性を持つChatGPTと対話して、それらの挙動を理解することができる。例えば、「Summarize for a 2nd grader」(右上)を使うと、ChatGPTは難しいトピックスを小学二年生が理解できる言葉で要約する。

| 出典: OpenAI |
モデルを検証する環境
OpenAIはモデルの挙動を検証する環境「Playground」を提供しており、ここでモデルを稼働させ、実際に対話を通して機能や属性を理解する。例えば、上述のモデル「Summarize for a 2nd grader」をここで稼働させ、対話を通じて機能や解答事例を評価する(下のグラフィックス)。プロンプトに「量子力学とは?」と入力すると、モデルは難解なコンセプトを分かりやすく纏めて出力する(中央)。ここでは、モデルの属性を、「入力されたコンテンツを小学二年生向けに要約」と定義している(左側)。このように、Playgroundでモデルの属性を定義し、実際の対話を通じて、出力された回答の内容やトーンをチェックする。

| 出典: OpenAI |
企業向け生成AI
米国を中心に大企業の80%がChatGPTを導入しており、生成AIのビジネス活用が急速に広がっている。企業で生成AIを使う際には、安全性やプライバシー保護に加え、モデルが社内規定に従って正しく稼働することが重要な要素となる。中身がブラックボックスの生成AIを如何にコントロールするかが問われている。OpenAIやGoogleは、企業向け生成AIの機能強化を急ピッチで進めている。