AIの自然言語機能が向上し、クールな仮想アシスタントの登場が相次いでいる。しかし、本当に役に立つ仮想アシスタントを開発するためには、AIはインテリジェントになり、人間のように言葉の意味を理解する必要がある。フェイスブックはこのテーマに取り組み、AIが実社会に接して一般常識を身に付け、人間のように言葉を理解する研究を進めている。
| 出典: Facebook AI Research |
Talk the Walk
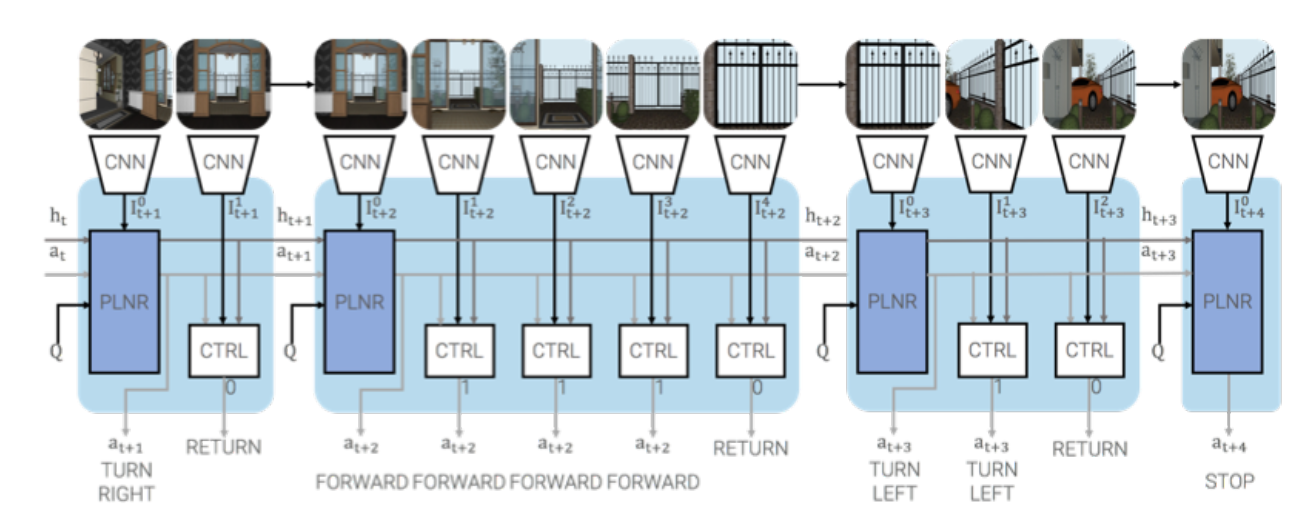
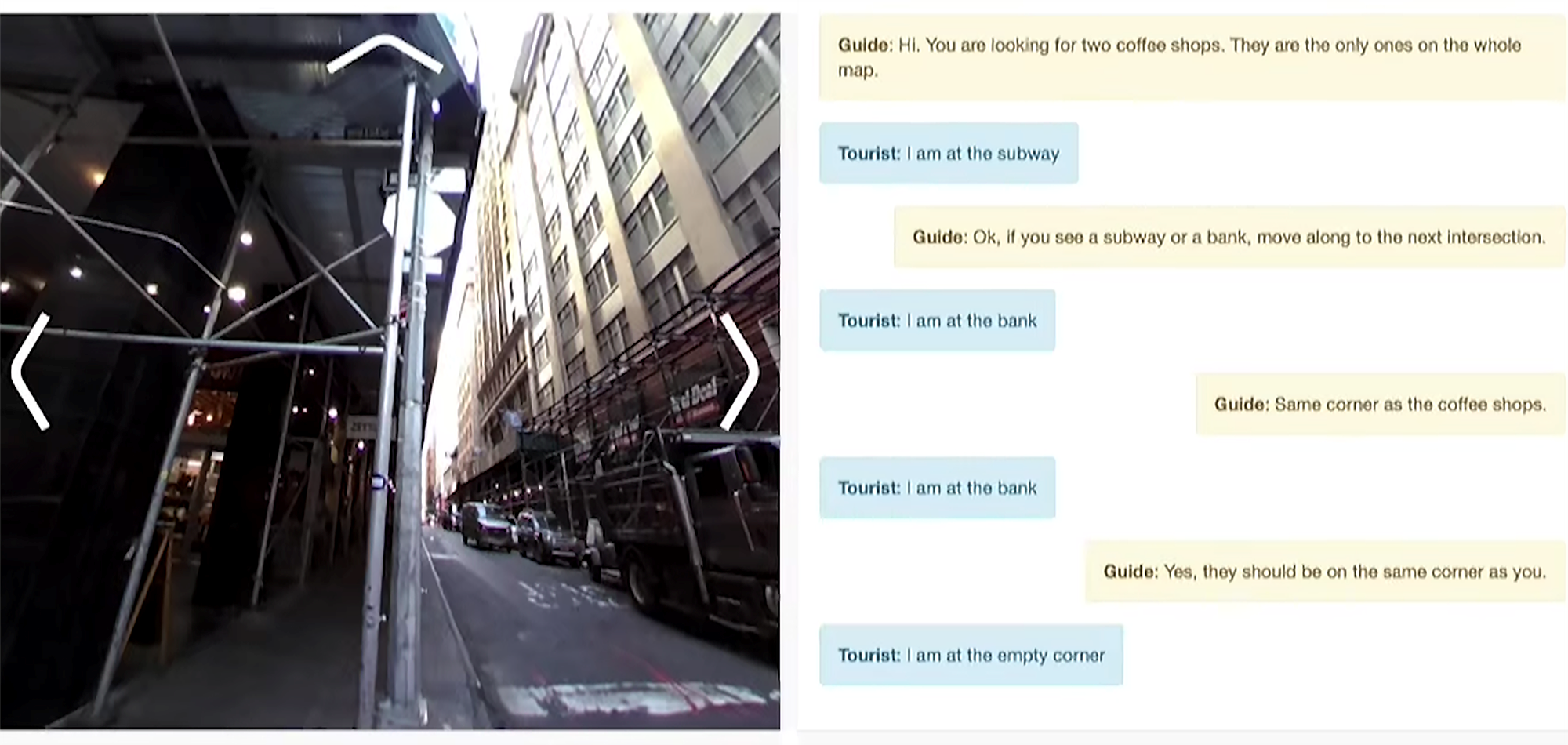
フェイスブックAI研究所 (Facebook AI Research)はこのテーマに関し、論文「Talk the Walk: Navigating New York City through Grounded Dialogue」を発表した。AIが街に出て、実社会とのインタラクションを通し、インテリジェンスを習得する技法を示している。二つのAI (Agent) が生成され、ガイドのAgentが観光客のAgentに言葉で道案内をする。このタスクは「Talk the Walk」と呼ばれ、会話を通し、ガイドのAgentが道に迷った観光客のAgentを目的地まで案内する (上の写真、右側は両者の会話で、左側は観光客が見ている風景)。
自然言語解析技法の進化
AIの登場で自然言語解析技法が飛躍的に進化した。特に、機械翻訳(Machine Translation)と言葉の理解(Natural Language Understanding)に関し、AIは飛躍的な進化を遂げ、我々の暮らしを支えている。しかし、AIは翻訳や会話ができるようになったが、アルゴリズムは言葉の意味を理解しているわけではない。AIは言葉の意味を理解しないまま、人間を模倣して会話しているに過ぎない。
教育手法が間違っている
AIが知的になれない理由は教育手法にあり、アルゴリズムは大量のテキストデータで教育され、統計手法に基づき翻訳や対話をするためである。フェイスブックは知的なAIを開発するには、社会の中で環境や他の人と交わりながら言葉を学習することで、アルゴリズムは言葉の意味を理解し、言葉を話せるようになると主張する。
道案内のタスク
フェイスブックAI研究所は、言葉を環境と結びつける手法でAIを教育する研究を進めている。Talk the Walkが教育モデルとなり、ニューヨーク市街地で、二つのAgent (ガイドと観光客)が会話しながら、目的地を目指すタスクを実行する。ガイドはマップを見て目的地を把握できるが、観光客の場所は分からない (下の写真右側)。一方、観光客はマップを見ることはできないが、周囲360度の風景を見ることができる (下の写真左側)。ガイドは観光客と会話しながら目的地まで誘導する (下の写真中央部の吹き出し)。つまり、道に迷った観光客が案内所に電話して、目的地までの道順を聞いている状態を再現した形となる。

| 出典: Dhruv Batra et al. |
マップを作成
研究チームはこのタスクを実行するために、ニューヨークの五つの地区を選び、それらのマップを生成した。マップには360度カメラで撮影した映像 (ストリートビュー) が組み込まれ、観光客は交差点の四隅で周囲の風景を見ることができる (上の写真左側、矢印にタッチするとその方向の風景を見ることができる)。更に、写真に写っているランドマーク (バーや銀行や店舗など) には、それが何であるかがタグされている。一方、ガイド向けには2Dのマップが用意され、ここに道路とランドマークが記載されている (上の写真右側)。
ガイドが目的地まで誘導
タスクはシンプルで、マップの中の観光客と対話しながら、ガイドが目的地まで誘導する。観光客はストリートビューを見て、目の前にあるランドマークをガイドに報告する。ガイドはこの情報を手掛かりに、観光客の現在地を把握し、目的地まで道案内をする。ガイドが観光客は目的地に着いたと確信した時点で道案内が終了する。システムは観光客が本当に目的地に到着したのかを検証し、一連のタスクが終了する。
ガイドと観光客の会話
ガイドと観光客は次のような会話を交わしながら目的地を目指す:
ガイド:近くに何がある?
観光客:正面にBrooks Brothers
ガイド:交差点の北西の角に行け
観光客:背後に銀行がある
ガイド:左に曲がり道を直進
観光客:左側にRadio Cityが見える
・・・
観光客が目的地に到達するまでこのような会話が続く。
位置決定モデル
ガイドが観光客を案内するためには、まず観光客の位置を把握する必要がある。観光客は目の前の風景を言葉でガイドに伝え、対話を通じてガイドは観光客の位置を把握する。このタスクを実行するために位置決定モデル「Masked Attention for Spatial Convolutions (MASC)」が開発された。MASCは風景の描写を言葉で受け取り、それを位置情報に変換する機能を持つ。
判定精度の評価
ニューヨーク市街地でMASCを試験してその性能を評価した。MASCの判定精度は高く、88.33%をマークし(下のテーブル三段目)、人間の判定精度76.74%を上回った(下のテーブル二段目、実際に人間同士がこのタスクを実行した)。但し、AIのケースでは人間の言葉は使わないで、特別な言語モデル(Emergent Communication)が使われた。この方式ではAIが生成する生データでAI同士が会話した。
一方、AIが人間の言葉を使って会話すると判定精度は50.00%に低下した(下のテーブル最下段)。この評価結果から、人間の言語は情報を正確に伝えるためには適した構造とはなっていないことも分かる。

| 出典: Dhruv Batra et al. |
この研究の意義
Talk the WalkはAIが言語を学習するためのフレームワークを提供する。この方式は「Virtual Embodiment」とも呼ばれる。これは、複数のAgentが、生成された環境の中で、体験を通し、言葉の意味を学習する手法を指す。Talk the Walkはこのコンセプトに基づくもので、知覚(Perception)、行動(Action)、会話(Interactive Communication)機能を、AIが社会とのインタラクションを通して学習する。
上述の通り、AIが人間の言葉を使ってコミュニケーションすると、意思疎通の精度が大きく低下することも明らかになった。人間が使う言葉は曖昧さが多く、コミュニケーションツールとしては不完全であることが改めて示された。つまり、AIに課された命題は、言語という不完全なコミュニケーションツールから、厳密に意味を把握することにある。このためには、人間がそうしてきたように、AIも環境に接し言語を学ぶ努力が必要になる。Talk the Walkはオープンソースとして公開されており、AIが言語を学習するための環境を提供する。