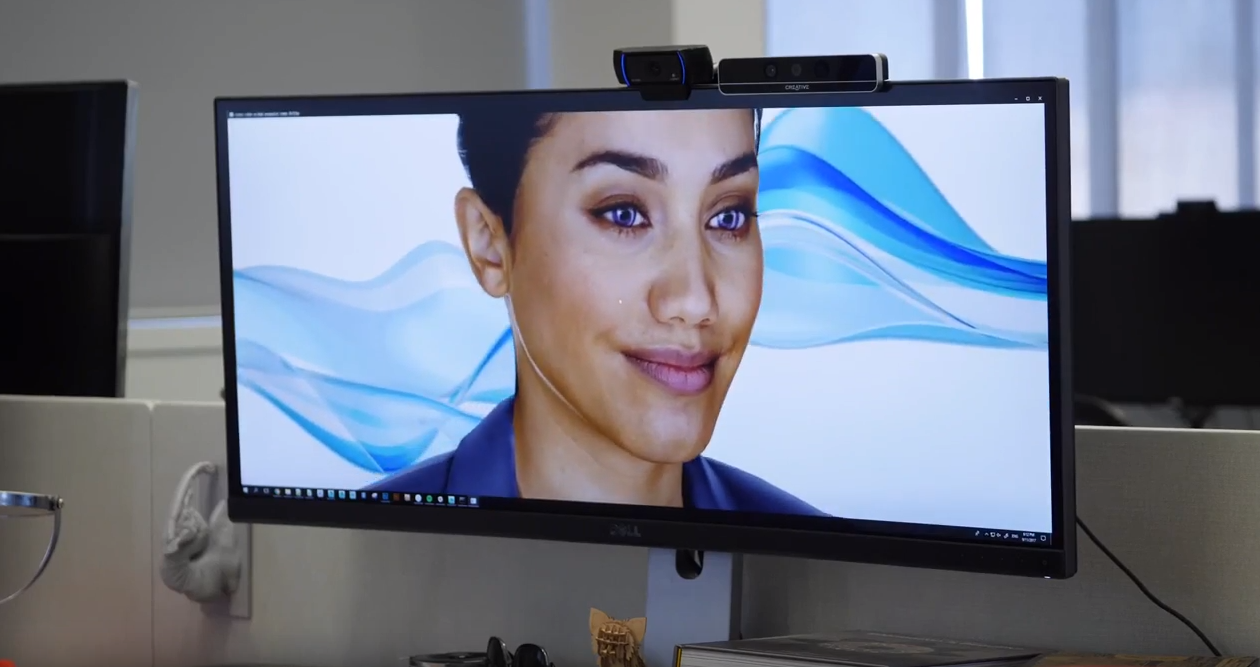
Digital Humansは人間と同じように、知性と感性でコミュニケーションする。相手の言葉を理解し、同時に、相手の感情を読み取ることができる。発せられた言葉に込められたメッセージをリアルタイムに把握し、インタラクティブに反応する。更に、Digital
Humansは多彩な感情を表現することができる。つまり、Digital Humansは相手の感情を読み取り、それに応じて自身の感情を表しコミュニケーションするAIとなる。
3D Facesで感情表現
Digital Humansの顔は「3D
Faces」と呼ばれる。3D Facesは文字通り三次元の顔で、人間の顔を精細に再現する。
顔の表情は筋肉をベースにして生成され、目は見たものに対して反応して動く。Digital Humansは身体全体を表現するもので、3D
Facesはその顔の部分となる。但し、Digital Humansはロボットではなくソフトウェアとして生成される。通常のディスプレイに表示されるほかARやVRで使われる。次のステップでヒューマノイドとして開発することが計画されている。
パーソナリティを持つ
Digital Humansは企業の仮想アシスタントとして利用され、固有のパーソナリティを持っている。パーソナリティは業務内容によって設定される。例えば、Digital
Humansがコールセンターのエージェントとなる場合、その会社を代表するにふさわしいパーソナリティを持つ。具体的には、顧客への応対方法が設定され、感情表現や挙動振る舞いまでも規定される。
Digital Humanは本物とそっくりで、人間かソフトウェアか見分けがつかない。対話においても感情豊かにコミュニケーションする。対話では相手の顔が見えることで、信頼感が格段に向上する。そもそも、人間は顔を見ながら会話することを好む。人間のエージェントに代わりAvaが顧客と応対しても、顧客との信頼関係を築くことができると期待される。顧客は音声だけのチャットボットではなく、表情と感情を持った仮想エージェントと会話することで親近感が醸し出され絆が強くなる。
しかしSocialbotはこの質問には回答できなかった。「I ask myself the same question」と返答した。相手が興味を持っていることを掘り下げて説明することを「Deep
Dive」という。Deep Diveすることで話が深くなり対話が進む。ただし、このシーンではうまくいかなかった。
このサービスは「Alexa for
Business」と呼ばれ、Amazon開発者会議「AWS
re:Invent 2017」で発表された。音声アシスタント機能をビジネスに適用するもので、家庭向けに提供されているAlexaを企業向けに拡大した構成となる。会社では煩雑な事務作業が多いが、Alexaがインテリジェントな秘書となり、言葉で指示したことを実行してくれる。
Alexaをデスクに置いて、スケジュール管理などで利用する
(上の写真)。「Alexa, what’s
my first meeting today?」と尋ねると、Alexaは次の打ち合わせ予定を回答する。また、Alexaに指示して、打ち合わせを設定することもできる。「Alexa, schedule a meeting with sales
team at 2 pm on Thursday?」と言えば、販売チームとの打ち合わせをセットしてくれる。
会議室で利用する
会議室ではAlexaがミーティングのアシスタントとして活躍する (下の写真)。テレビ会議を始めるときに、「Alexa,
start a sales meeting」と指示すると、Alexaが指定の番号に電話を発信し、モニターに参加者が映し出される。プレゼン中に資料が必要になると、「Alexa,
pull up the last month sales」と指示すると、Alexaがディスプレイに先月の売り上げ情報を表示する。
出典: Amazon
コピー室に設置しておくと
Alexaをオフィスの様々な場所に設置しておくと意外な使い方ができる。オフィス入り口に設置しておくと、Alexaが受付の役割をこなす。「Where is the Tyler’s office?」と尋ねると、オフィスの場所を教えてくれる (下の写真)。
出典: Amazon
コピー室に設置しておけば、用紙が切れた時に、Alexaに指示すれば発注してくれる。「Alexa, ask the office for more
printer paper.」。 Alexaはプリンター用紙を発注するだけでなく、印刷中のタスクについて、「Should
I send your job to Printer 3?」と質問し、別のプリンターで印刷するよう取り計らってくれる。
会議室を予約するときは、部屋に設置してあるAlexaに、「Alexa, ask Teem to book this room」と指示する。また、ディスプレイの「Reserve」ボタンにタッチして予約することもできる。会議室を使い始めるときは、「Alexa,
ask Teem to check in this room.」と言い、時間を延長する時は、「Alexa, ask
Teem to extend this meeting by 15 minutes.」と指示すると、15分間延長できる。
出典: Teem
ERPとの連携
Acumaticaという新興企業は、Alexaを使って在庫管理システムを音声で提供している。Alexaに言葉で在庫状態を尋ねることができる。「Alexa,
ask Acumatica how many laptops do we have in stock?」と質問すると、Alexaはラップトップの在庫量を答えてくれる。在庫がない場合は、Alexaに商品発注を指示できる。「Alexa,
ask Acumatica order 10 please.」というと、その商品を10点発注する。
Alexa for Businessに先立ち、Amazon
Echoはホテル客室で使われている。Wynn Las Vegasはラスベガスの高級リゾートホテルで、全ての客室にAmazon
Echoを導入すると発表。4,748台のAmazon Echoが設置され、宿泊客はホテルや客室情報をEchoに尋ねることができる (下の写真)。
また、宿泊客は音声で部屋の設備をコントロールできる。「Alexa, I am here」と言えば、部屋の電灯が灯り、「Alexa, open the
curtains」と言えばカーテンが開く。「Alexa, turn on the news」と言えばテレビがオンとなり、ニュース番組が放送される。Alexaがコンシェルジュとなり、宿泊客をサポートする。ホテル側としては、宿泊客がフロントに電話する回数が減り、コスト削減にもつながるという読みもある。
出典: Wynn Las Vegas
有償のサービス
家庭向けのAlexaは無償で使えるが、企業向けのAlexa for Businessは有償のサービスとなる。サービス料は共有モデルではデバイスごとに月額7ドルで、個人モデルでは利用者あたり月額3ドルとなる。また、企業のIT部門がデバイスや利用者を管理する体制となる。
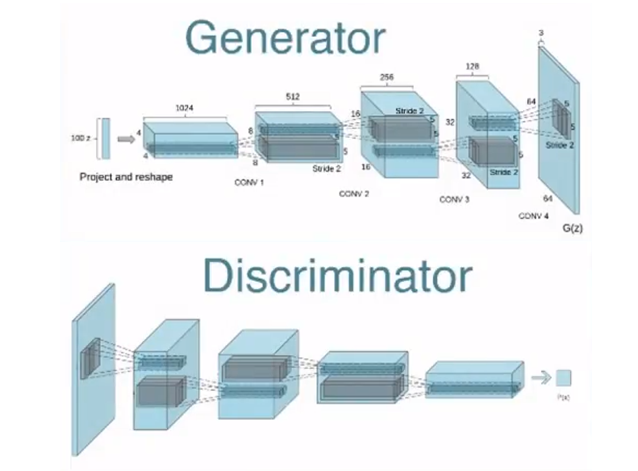
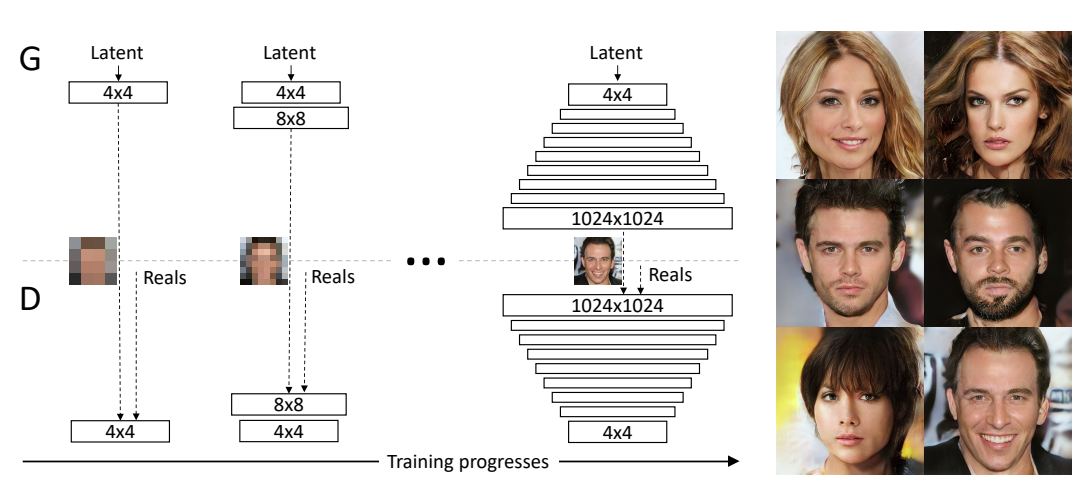
この研究は論文「Progressive
Growing of GANs for Improved Quality, Stability, and Variation」として公開された。この技法はGenerative
Adversarial Network (GAN)と呼ばれ、写真撮影したように架空のセレブ (上の写真) やオブジェクトを描き出す。どこかで見かけた顔のように思えるがこれらは実在の人物ではない。GANが想像で描いたものでこれらのイメージをGoogleで検索しても該当する人物は見当たらない。このようにGANは写真撮影したように鮮明な偽物を生成する技術である。