DeepMindはAIが自律的に知識を習得する囲碁ソフト「AlphaGo Zero」を公開した。AlphaGo Zeroは人間の知識や教育データは不要で、AI同士の対戦で技量を上げる。AlphaGo Zeroは人間のような学習能力を身に付け、汎用人工知能への道筋を示した。シンギュラリティに一歩近づいたとも解釈できる。

| 出典: DeepMind |
Tabula Rasa:ゼロから学ぶ
AlphaGo Zeroの技術詳細は科学雑誌Natureに「Mastering the game of Go without human knowledge」として公開された。DeepMindのAI研究最終目的は人間を超越する学習能力を持つアルゴリズムを開発することにある。ゼロの状態から知識を習得する手法は「Tabula Rasa (空白のページ)」とも呼ばれる。人間は生まれた時は空白の状態で、学習を通じ知識を増やし、判断するルールを獲得する。これと同様に、生成されたばかりのAIは空白であるが、自律学習を通じ知識やルールを学ぶアルゴリズムが最終ゴールとなる。AlphaGo Zeroは囲碁の領域でこれを達成し究極の目標に一歩近づいた。
DeepMindのマイルストーン
DeepMindは一貫してこの目標に向かってAI開発を進めている。2013年12月、AIがビデオゲームを見るだけでルールを学習し、人間を遥かに上回る技量でプレーするアルゴリズム (DQNと呼ばれる) を公開し世界を驚かせた。2015年10月、高度に複雑な技量を必要する囲碁で、AlphaGoが欧州チャンピオンFan Huiを破った。2016年3月、改良されたAlphaGoが世界最強の棋士Lee Sedolを破り再び世界に衝撃を与えた。
AIが自律的に学習
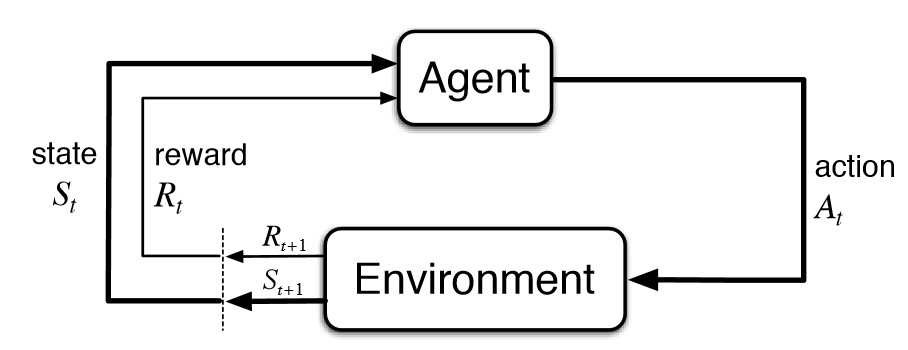
今回発表されたAlphaGo Zeroは上記のAlphaGoから機能が格段に進化した。AlphaGo Zeroは自分自身との対戦を通じ技量を習得していく。最初は初心者の状態でランダムにプレーするが、対戦を重ね技量を上げていく。この過程で人間がアルゴリズムを教育する必要はない。プロ棋士の棋譜などを入力する必要はなくAIが独自で学習する。AlphaGo ZeroはReinforcement Learning (強化学習、下の写真はその構造を示す) という技法を搭載しており、アルゴリズムが人間のように試行錯誤しながら囲碁を学んでいく。
| 出典: Stanford University |
単一のネットワーク
アーキテクチャの観点からは、AlphaGo Zeroは単一のネットワークで構成され構造がシンプルになった。従来のAlphaGoは二つのネットワーク (policy network (次の一手を決定) とvalue network (局面を評価))で構成されていた。AlphaGo Zeroではこれらを一つにまとめ、単一ネットワークが次の手を探しその局面を評価する。また、AlphaGo Zeroは次の手を探すためにTree Searchという方式を使っている。
短期間で腕を上げた
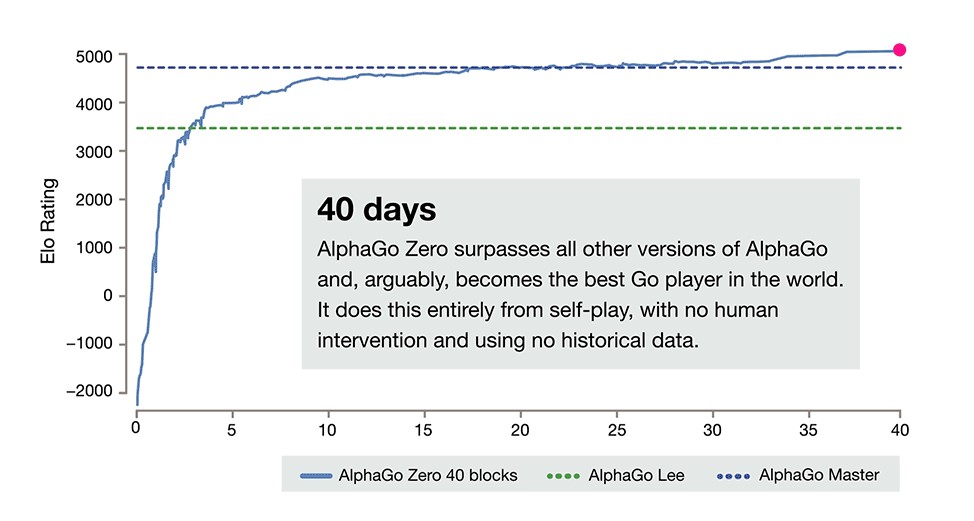
AlphaGo Zeroはセルフプレイを通じてReinforcement Learningアルゴリズムを教育した。アルゴリズムは振動したり過去の対戦成果を忘れることなく順調に技量を増していった。下のグラフは教育に要した日数 (横軸) と技量 (縦軸) を示している。3日でAlphaGo Lee (Lee Sedolに勝ったバージョン) の性能を上回った。一方、AlphaGo Leeの教育には数か月を要した。21日でAlphaGo Master (世界チャンピオンKe Jieに勝ったバージョン) の性能を上回った。40日経過したところでAlphaGo Zeroは全てのバージョンの性能を凌駕した。
| 出典: DeepMind |
人間の教育は不完全
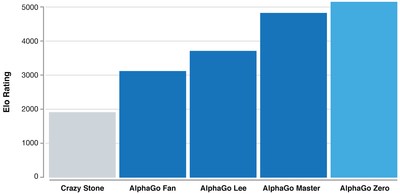
AlphaGo Zeroは40日の教育で2900万回対戦し世界最高の性能に到達した。下のグラフはAlphaGoのそれぞれのバージョンの性能を示している。興味深いのはAlphaGo Masterとの性能比である。AlphaGo MasterはAlphaGo Zeroと同じネットワーク構成であるが、Masterは人間が教育したアルゴリズムである。このグラフは人間が教育すると技量が伸びないことを示している。つまり、人間が教育するよりAIが独自で学習するほうが技量が伸びることが証明された。人間の教育は不完全であることの立証ともなり、AIが自律学習することの必要性を示した結果となった。
| 出典: DeepMind |
プロセッサ構成
AlphaGo Zeroはアーキテクチャがシンプルになり計算量が大幅に減少した。AlphaGo Zeroは4台のTPU (tensor processing units) を使いシングルコピーで稼働する。これに対し、AlphaGo Leeは48台のTPUを使い複数コピーを稼働させていた。AlphaGo Zeroは機能が向上したことに加え、効率的に稼働するシステムとなった。TPUとはGoogleが開発した機械学習に特化したプロセッサで、ASIC (専用回路を持つ半導体チップ) でTensorFlow向けに最適化されている。
定石を次ぎ次に発見
AlphaGo Zeroは教育の過程で囲碁の「定石」を次々に発見した。定石とは最善とされる決まった打ち方で、人間が数千年かけて生み出してきた。AlphaGo Zeroはこれら定石を72時間の教育で発見た。更に、AlphaGo Zeroは人間がまだ生み出していない「定石」を発見した。新しい定石は人間の試合では使われていないが、AlphaGo Zeroはこの定石を対戦の中で頻繁に利用し技量を上げた。
Reinforcement Learningの改良
AlphaGo ZeroはReinforcement Learningアルゴリズムが大きな成果をもたらすことを実証した。DeepMindが開発したReinforcement Learningは人間をはるかに上回る技能を獲得し、更に、人間が教育する必要はないことを証明した。人類は数千年かけて囲碁の知識を獲得したが、Reinforcement Learningは数日でこれを習得し、更に、人間が到達していない新たな知識をも獲得した。
汎用AIの開発が始まる
AlphaGo Zeroの最大の功績は自律的に学習する能力を獲得したことにあり、汎用的なAI (General AI) へ道が大きく開けた。汎用的なAIとは狭義のAI (Narrow AI) に対比して使われ、AIが特定タスクだけでなく広範にタスクを実行できる能力を指す。AlphaGo ZeroのケースではAIが囲碁をプレーするだけでなく、科学研究のタスクを実行することが次のステップとなる。ルールが明確でゴールが設定されている分野でAlphaGo Zeroの技法を展開する研究が始まった。
新薬開発などに応用
短期的には、DeepMindはAlphaGo Zeroを新薬開発に不可欠な技術であるProtein Foldingに応用する。Protein Foldingとはタンパク質が特定の立体形状に折りたたまれる現象を指す。ポリペプチド (polypeptide) がコイル状の形態から重なり合って三次元の形状を構成するプロセスで、このメカニズムを解明することが新薬開発につながる。しかしProtein Foldingに関するデータは限られており機械学習の手法では解決できない。このためReinforcement Learningの手法ででこれを解明することに期待が寄せられている。
自らルールを学ぶAIが次の目標
長期的には量子化学 (Quantum Chemistry)、新素材の開発、ロボティックスへの応用が期待される。Reinforcement Learningを実社会に適用するためにはアルゴリズムが自らルールを学習する技能が必要になる。DQNがテレビゲームを見るだけでルールを学んだように、AlphaGo Zeroが自らルールを学ぶ能力が求められる。DeepMindはこの目標に向かって開発を進めていることを明らかにしている。AlphaGo Zeroの次はもっとインテリジェントなAIが登場することになる。