Metaは最新のオープンソース言語モデル「Llama 4」を公開した。Llama 4はOpenAI GPT-4.5など業界のトップモデルの性能に並び、オープンソースがクローズドソースのレンジに入った。Llama 4はマルチモダルな構造で、イメージやビデオをそのまま処理することができる。Llama 4は「Mixture of Expert (MoE)」というアーキテクチャを採用し、複数の専用モジュールがモデルを構成する。これにより、教育や実行のプロセスで計算量を低減し、運用コストを大幅に抑えた。

| 出典: Generated with Meta Llama 4 |
Llama 4のモデル構成
Llama 4はMetaの最新言語モデルで三つのラインから構成される。規模の順に「Behemoth」、「Maverick」、「Scout」となる。Behemothはまだ開発中で、MaverickとScoutがリリースされた。Llama 4はマルチモダルで「Mixture of Expert(MoE)」というアーキテクチャとなる。モデルの特徴は:
- Llama 4 Behemoth:ハイエンドモデル、最もインテリジェントなモデル、教師モデルとして他のモデルをKnowledge Distillation(知識抽出)の手法で開発、パラメータ数は2T
- Llama 4 Maverick:ミッドレンジモデル、マルチモダル処理に特徴、パラメータ数は400B
- Llama 4 Scout:ローエンドモデル、コンテクストサイズ(入力できるデータの量)は10Mと巨大、パラメータ数は109B

| 出典: Meta |
Llamaの利用方法
MetaはLlamaを「Meta AI」に公開しており、このサイトで利用することができる。Meta AIはLlamaのインファレンスサイトで、ブラウザーのインターフェイスで、モデルを使うことができる(下の写真、Llama 4 Scoutがイメージを生成)。対話形式のAIモデルで、プロンプトに対し、Llamaが回答を生成する。特に、Metaはイメージ生成技術にフォーカスしており、Llamaは指示された内容に沿って綺麗なイメージを生成する。

| 出典: Meta AI |
Llama 4をダウンロード
Llama 4をHugging Faceからダウンロードして利用することができる。Hugging FaceはオープンソースAIのハブで、ここにLlama 4が公開されている。ここは開発者向けのサイトで、社内のサーバやデスクトップにダウンロードして利用する。但し、Llama 4はモデルのサイズが大きく、PCでは容量が足りず、最低限でもNvidia GPU H100が1ユニット必要となる。また、Hugging Faceはインファレンスサービスを提供しており、ここでLlama 4をトライアルで実行しその機能や性能を検証することができる(下の写真、Maverickで入力した写真を解析)。

| 出典: Hugging Face |
クラウドサービス
主要クラウドはLlama 4のホスティングを開始し、ここでモデルを利用することができる。Googleはクラウド「Vertex AI」でLlama 4のホスティングを始め、この環境でモデルを実行することができる(下の写真)。また、独自のデータでLlama 4をファインチューニングし、専用モデルを開発することができる。GoogleはLlamaの他に、DeepSeekなど主要オープンソースをホスティングをしており、ここで様々なモデルを利用できる。
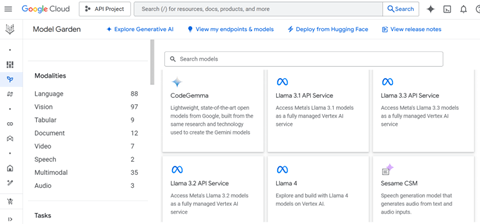
| 出典: Google |
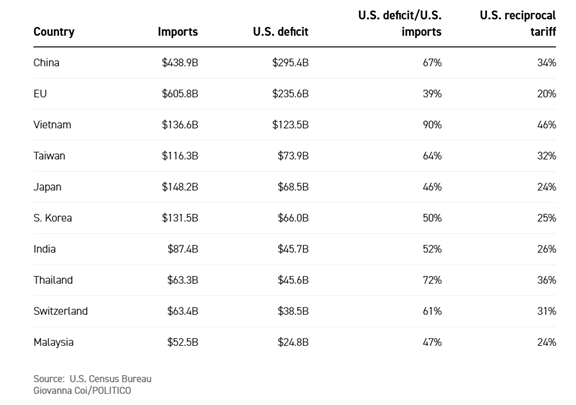
Llama 4 Maverickの性能
Llama 4 Maverickはシリーズの中核モデルで、他社の主要モデルに対抗する位置づけとなる。MaverickはMoEアーキテクチャを採用し、128のエキスパートで構成される。モデル全体ではパラメータ数は400Bであるが、インファレンス時に活性化されるパラメータ数は17Bで、効率的に稼働させることができる。ベンチマークサイト「LMArena」はモデルの性能を公開しており、これによると、MaverickはGPT-4.5やGrok 3などを追い越し、二位の位置を占めている(下のグラフ)。
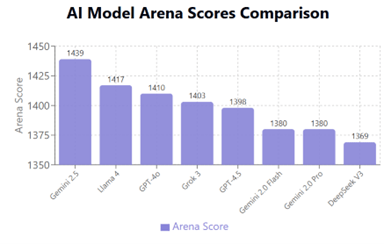
| 出典: AI Arena benchmark scores |
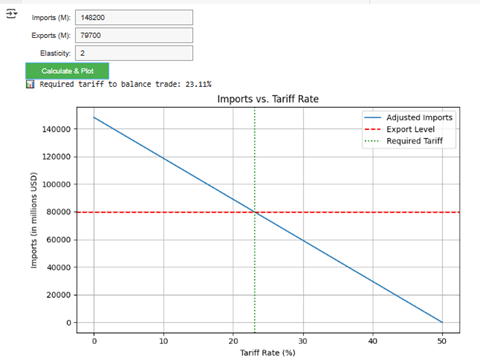
Mixture of Expertsの採用
アーキテクチャの観点からは、MetaはLlama 4で「Mixture of Experts (MoE)」という方式を採用した。Llama 3までは「Dense Model」と呼ばれる単一構成のモデルで、Llama 4からMoEに移った。MoEとは入力されたプロンプトに対し、最適なエキスパート(専門モジュール)がアサインされ、タスクを実行する仕組みとなる(下のダイアグラム)。
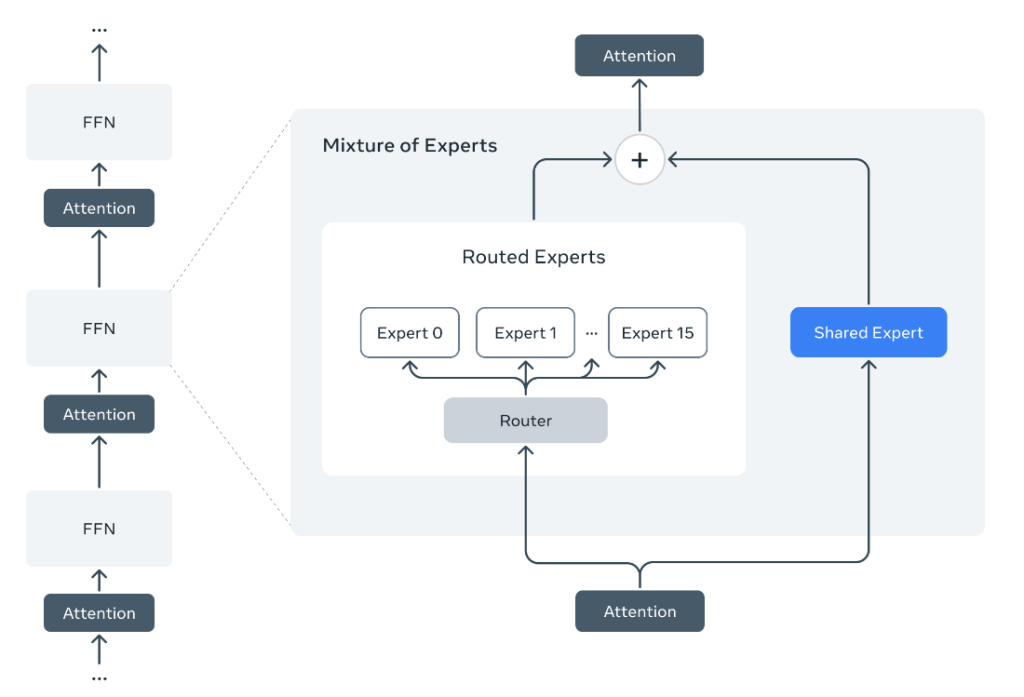
| 出典: Meta |
Mixture of Expertsの仕組み
具体的には、ルーター「Router」がプロンプトを解析し、最適なエキスパートにデータを転送、この専門モジュールで処理が進むまた、共有エキスパート「Shared Expert」はプロンプトの内容に関わらず、常に使われるモジュールとなる。MoEにより活性化されるネットワークが限定され、トレーニングやインファレンスを効率的に実行できる。Llama 4 Maverickのケースでは、モデル全体でパラメータの数は400Bであるが、実行時には17Bのパラメータが活性化され、システムの4%の部分だけが稼働し、計算処理を大きく低減する。
DeepSeekとの競合
MetaはDeepSeekの衝撃を受けてLlama 4の開発を急ピッチで進めた。DeepSeekが高度な言語モデル「DeepSeek-V3」をリリースし、MetaのAI開発チームはこの技術を詳細に解析し、これがLlama 4に反映されている。Llama 4 MaverickはDeepSeek-V3を意識した設計となっており、DeepSeek-V3と同等の推論機能を半分の規模(パラメータの数が1/2)で実現した。DeepSeekとの競合でMetaの技術開発が大きく前進したかたちとなった。