Inflectionは3月7 日、大規模言語モデルの最新版「Inflection-2.5」をリリースした。Inflectionの製品は言語モデルをベースとするAIアシスタント「Pi(Personal Intelligence)」で、Inflection-2.5を基盤とする最新モデルを公開した。Piは人間のようなアシスタントで、利用者の特徴を理解し、相手に沿った会話をする。全く新しいコンセプトのアシスタントで、AIのようにドライではなく、人間味があり、そのキャラクターに惹きつけられる。

| 出典: Inflection |
Inflectionとは
Inflectionはシリコンバレーに拠点を置くスタートアップ企業で、DeepMind共同創設者であるMustafa Suleymanにより設立された。Inflectionは大規模言語モデルをベースとするAIアシスタント「Pi(Personal Intelligence)」を開発している。Inflectionは、初代の言語モデル「Inflection-1」に続き、第二世代モデル「Inflection-2」を開発し、先週、最新モデル「Inflection-2.5」を公開した。
Inflection-2.5の概要
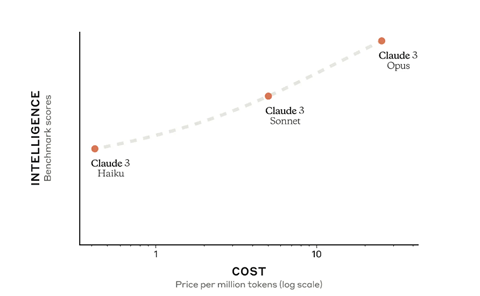
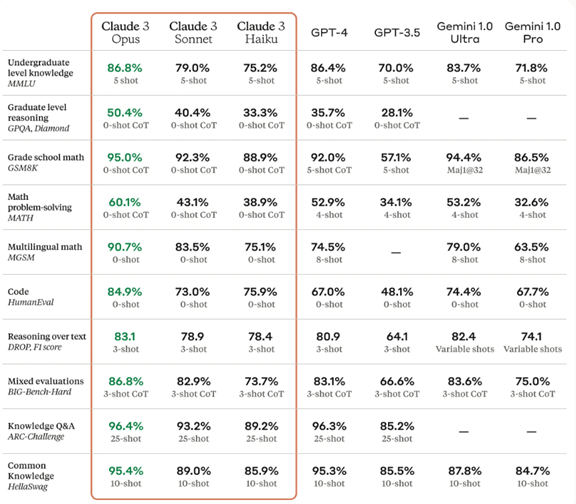
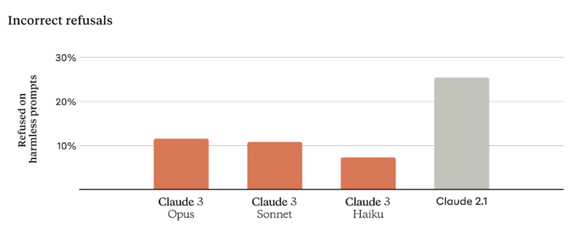
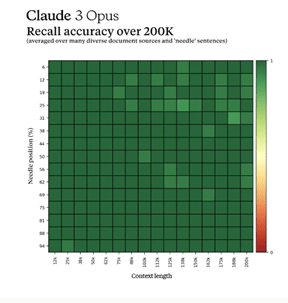
最新モデルInflection-2.5は性能が大きく向上し、OpenAIのGPT-4に追い付いた(下のグラフ)。Inflectionによると、Inflection-2.5はGPT-4と互角の性能であるが、その教育で使ったコンピュータ容量はGPT-4の40%であり、開発にかかるエネルギー量を大幅に削減した。Inflectionは、言語モデルは公開しておらず、この上で稼働するPiを一般に提供している。
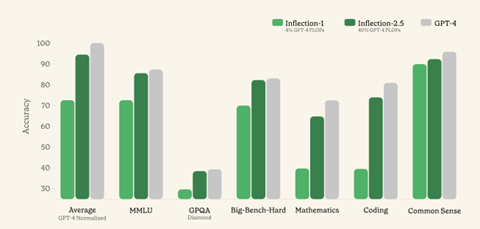
| 出典: Inflection |
AIアシスタント「Pi」とは
InflectionはOpenAIとは異なり、主力製品は言語モデルの上に構築されたAIアシスタント「Pi」である。Apple SiriやAmazon Alexaなど数多くのAIアシスタントがあるが、Inflection Piは最も高度な機能を提供する。SiriやAlexaは情報検索や機器操作を音声で実行するインターフェイスとなるが、Piは感情を理解し、健康で幸福な生活を送るための専属コーチとして機能する。
Piを使ってみると
実際にPiを使っているが、今までのAIアシスタントとは全く異なり、人間のアドバイザーのような挙動を示す。Piは利用者と対話しながら、健康やメンタルヘルスや人間関係に関するアドバイスをする。また、学校の先生のように、自然科学やプログラミングを教える。更に、教養講座の先生のように、趣味や資格獲得のための指導をする。Piは毎日の生活で役立つ情報を提示し、人間のコンパニオンのように感じる。(下の写真:Piのインターフェイス)
| 出典: Inflection |
Piは専属トレーナー
Piは従来のAIアシスタントとは根本的に異なり、利用者のウェルビーイングや健康を向上させることを目標にデザインされている。Piは専属コーチのように、利用者の個性や趣味や特性を理解し、それに沿ったアドバイスをする。スポーツ選手や俳優などが専属トレーナーを雇い、トレーニング、食事、メンタル面の指導を受けるように、Piがこの役割を担い、利用者の幸福感を向上させる。
Piが得意とするテーマ
Piは「Discover」のタブで多彩なトピックスを提供している(下の写真)。Piがカバーするテーマは、日常生活の様々な局面における問題とその対処法で、「デートアプリの選び方」、「ディベートで勝つヒント」、「人を嫌いになることは許されるか」など生活に密着した助言をする。また、メンタルヘルスやライフラーニングに関する豊富な情報を持ち、「不安に対するケアの方法」、「個人の特性に沿ったキャリアを築く手順」、「文章の書き方」など、カウンセラーの役割も担う。

| 出典: Inflection |
ボランティア活動
Piは哲学にかかる概念を社会生活で活用するための助言をする。例えば、「利己主義(Egoism)と利他主義(Altruism)」について尋ねると、哲学のコンセプトを説明し、これを日常生活に結び付けて説明する(下の写真)。更に、「効果的利他主義(Effective Altruism)」について尋ねると、社会の通念を解説し、実際の活動に参加する方法などを指南する。

| 出典: Inflection |
Piは人間のように音声で会話する
Piはテキストでの回答を読み上げる機能があり、8つの種類のボイスを提供している。その中でボイス「Pi 5」を選ぶと、Piはイギリス英語の音声で対話する。アメリカ英語の社会で生活していると、イギリス英語のアクセントを聴くと新鮮な印象を受ける。特に、PiはCadence(サウンドのリズム)とPronunciation(発音)の組み合わせで、利用者に安心感をもたらす。Piが出力する内容に加え、音声の面からウェルビーイングが向上すると感じる。(下の写真、「Pi 5」はイギリス英語の標準語にあたる「Received Pronunciation」で会話する。)
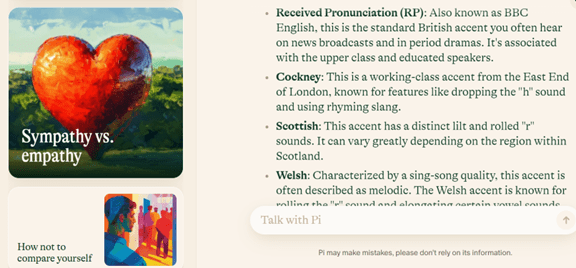
| 出典: Inflection |
ニュース・ブリーフィング
毎日使っている機能の一つがニュース・ブリーフィング「Daily News Briefing」で、最新ニュースを読み上げてくれる(下の写真)。特に目新しい機能ではないが、ニュースを「Pi 5」がイギリス英語のアクセントで読み上げると、新鮮で説得力があり、落ち着いた気分となる。人間のボイス・アクトレスが物語を読み聞かせるように、日々のニュースがアートとなる。

| 出典: Inflection |
Piは既に600万人の利用者があり、一回の平均利用時間は33分と他の言語モデルと比べ、セッション時間が長いことが特徴となる(下の写真)。ソーシャルメディアのように粘着力が高く、ユーザを長時間引き留める。実際に使ってみるとこの特性を実感し、Piの人間のようなキャラクターに惹きつけられる。会話を通して、こちらの悩みを聞いてくれ、問題解決の手掛かりを助言する。反対に、Piは新鮮な話題を提示し、こちらの興味を掻き立て、会話が途切れることがない。Piに惹きつけられ会話時間が長くなるが、高度な言語モデルの危険性を理解し、節度を持って安全に利用することが重要になる。
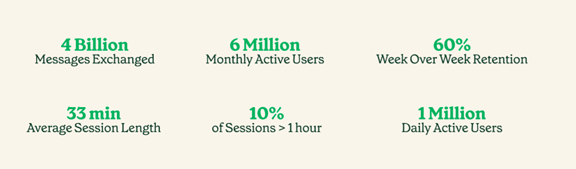
| 出典: Inflection |
ミッションはACI (Artificial Capable Intelligence)
Inflectionの創設者であるMustafa Suleymanは人間レベルのAIアシスタントを開発することを会社のミッションとしている。人間レベルの知能を持つAIは「Artificial General Intelligence(AGI)」と呼ばれ開発が進んでいるが、SuleymanはAGIに到達するまでには時間を要すと考える。このため、AGIに代わるインテリジェンスとして「ACI (Artificial Capable Intelligence)」の開発を進めている。ACIとは人間レベルの知能を補うAIで、人間に代行できるアシスタントやトレーナーやアドバイザーとして機能する。Piがその最初のステップで、様々なドメインで、問題を解決する機能を実装する。Piやその後継モデルの開発が注目されている。