Googleは今週、開発者会議「Google I/O 2022」をライブとオンラインのハイブリッドで開催した(下の写真、ライブ会場)。CEOのSundar Pichaiが基調講演で、AIを中心に技術開発の最新状況を説明した。この講演は、アメリカ大統領が連邦議会に対して行う一般教書演説になぞらえ、” State of the Union Address”とも呼ばれる。今年の講演はAIの基礎研究と応用技術に焦点をあて、高機能であるが危険なAIをビジネスに適用する技法が示された。

| 出典: Google |
マルチ検索
AI言語モデルは既に検索で使われているが、今年はイメージと言葉を統合した「マルチ検索(Multisearch)」が登場した。これは、イメージ検索とテキストによる検索を併せたもので、マルチメディアの検索サービスとなる。具体的には、撮影した写真のイメージ検索「Google Lens」とテキスト検索を融合したもの。例えば、スマホで気になるドレスを撮影すると、Google Lensはドレスの概要や購買サイトを教えてくれる(下の写真左側)。更に、この検索結果をテキストで操作できる。同じモデルで色違いの商品を探すため、「Green」と入力すると(中央)、グリーンのドレスを表示する(右側)。検索はマルチメディアに進化した。

| 出典: Google |
肌色のリアルトーン
カメラで撮影した有色人種の顔の色は正しく再現されてなく、レンズの”バイアス問題”が指摘されている。例えば、黒人の顔の写真は暗すぎたり、または、明るすぎたりと、正しい色調が再生されない。日本人を含むアジア系人種も同じ問題を抱えており、本当の顔色を再現できない。このため、Googleはスマホカメラで正しい色を再現するための技術「Real Tone for Pixel」を開発し、最新モデル「Pixel 6」に搭載している(下の写真、Pixel 6で撮影した有色人種の顔でリアルトーンが再現されている)。

| 出典: Google |
コンピュータビジョン向けのリアルトーン
Googleはこれを拡充し、スマホカメラだけでなく、他の製品にリアルトーンの技術を組み込み、公正な製品の開発を始めた。これは「Real Tone Filters」と呼ばれ、顔の色調を10段階で定義する。これをAI開発に適用し、バイアスの無いアルゴリズムを開発する。コンピュータビジョンの開発で、人間の顔の色を正確に把握することで、偏りのない公正なアルゴリズムを開発する。有色人種の顔の色を正確に定義することで、人種間で公正に判定できるAIを開発する。(下の写真、Real Tone Filtersをアジア系人種に適用した事例。アジア人は、カメラで撮影すると、顔色が白っぽくなる(左側)。Real Tone Filtersで補正すると健康的な肌色が再現される。)

| 出典: Google |
大規模AI会話モデル「LaMBD 2」
Googleは大規模AI言語モデルを開発しており、その中で、会話型AIは「LaMDA」と呼ばれる。今年は、その最新モデル「LaMDA 2」が公開され、その利用法について様々なアイディアが披露された。LaMDA 2は人間のように会話できる高度な機能を持つが、これをビジネスに応用する手法は確立されていない。
会話型AIを生活で活用するアイディア
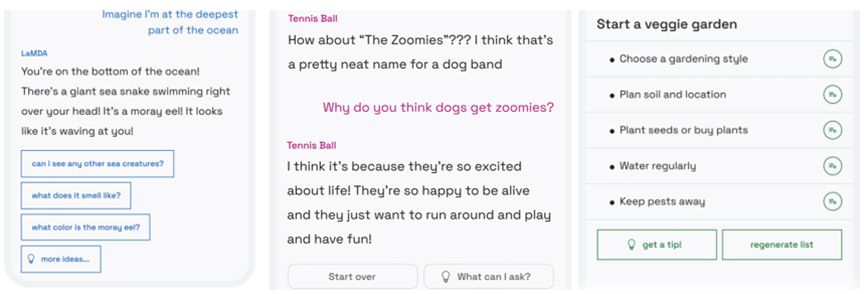
Googleは、LaMDA 2と会話することで、日々の生活が便利になる三つのモデルを示した(下の写真)。
- 「Imaging it」は、LaMDA 2が人間の質問に回答するモデル(左側)。「海で一番深い場所にいると想像すると」と指示すると、LaMDA 2は「マリアナ海溝の底にいて、、、」と、その説明をする。
- 「Talk about it」は、LaMDA 2が指定された話題で会話するモデル(中央)。「犬のバンドの名前は」と問われるとその候補名を回答する。その後の会話で、話題は「犬」から逸れず、人間のように一貫性がある。
- 「List it」はタスクを実行するために、必要なアクションをリストアップするモデル(左側)。人間が「家庭菜園を計画している」と述べると、LaMDA 2はそれに必要な作業項目をリストアップする。
会話型AIとの対話で知識を得るだけでなく、人間が雑談するように、AIとの会話を楽しむことができる。更に、会話型AIはプロとして、専門スキルを伝授する。
| 出典: Google |
AIテストキッチン
人間のように高度な会話機能を持つLaMDA 2であるが、一般には公開されてなく、閉じた試験環境「AI Test Kitchen」で機能の検証が進められている。LaMDA 2は、アルゴリズムがバイアスしており、差別的な発言や、正しく回答できないケースがあると予測されている。これをGoogleだけで検証することは難しく、外部のパートナーと共同で試験する作業を進めている。AIの規模が大きくなるにつれ、バイアスの無い完全な形でリリースすることには限界があり、問題をどこまで洗い出せるかが課題となる。

| 出典: Google |
大規模AI言語モデル「PaLM」
Googleは世界大規模のAI言語モデル「PaLM」を開発した。Googleが開発した巨大AIは、言葉を理解する機能に加え、推論機能、プログラムをコーディングする機能が大きく進化した。数学計算はコンピュータの基本機能であるが、AI言語モデルはこれを人間のように、論理的に考えて解くことができない。これに対し、PaLMは、数学計算を複数のステップに分けて推測することで、正しく答えることができた。
この手法は「Chain of Thought Prompting」と呼ばれ、AI言語モデルが思考過程を複数のステップに分けて実行し、その結果を出力する(下のグラフィックス)。人間の論理思考を模倣したもので、ステップごとに推論を重ねることで(水色のシェイド)、正解率が大きく向上した(黄色のシェイド)。「5月は何時間あるか」という問いに、PaLMは「1日は24時間で、5月31日あり、24 x 31で744時間」という思考過程を経て回答した。

| 出典: Google |
AI向けのデータセンター
GoogleはAI機能をクラウド「Google Cloud」で提供しているが、機械学習専用の計算設備「Machine Learning Hub」を新設した。これは、オクラホマ州のデータセンター(下の写真)に構築されたもので、8システムのAI専用サーバ「Cloud TPU v4 Pods」から成る。性能は9 Exaflopsで、世界最大規模のAIスパコンとなる。また、このセンターの電力消費量の90%はクリーンエネルギーで供給されている。AI計算で大量の電力を消費することが社会問題となっているが、Googleはエコな環境でAIシステムを開発していることをアピール。

| 出典: Google |
信頼できるAIの開発
Googleは言語モデル向けにニューラルネットワークを開発してきたが、2017年ころから「Transformer」というアーキテクチャに乗り換えた。これをベースに、「BERT」や「MUM」などの言語モデルを開発し、検索エンジンなどに適用し、検索クエリーの意味を理解するために使っている。今では、大規模AI言語モデル「LaMDA 2」や「PaLM」を開発したが、まだ基礎研究の段階で、これらを使ったサービスは登場していない。Googleはこれら大規模AIモデルをどうビジネスに応用するか、試行錯誤を重ねている。また、大規模AIモデルが内包する危険性を把握し、これを抑止することがチャレンジとなる。Googleは開発者会議で、AI言語モデル開発戦略を明らかにし、信頼できるAIを開発する取り組みを社会にアピールした。

| 出典: Google |