先週、Nvidiaは開発者会議「Nvidia GTC 2021」で、地球温暖化対策に寄与する新技術を発表した。これは、地球をメタバースで構築し、ここで気候モデルをシミュレーションし、温暖化対策に役立てるという構想である。気候モデルは巨大で、新たにスパコンを開発して、これを実行する。しかし、高精度なモデルを実行するにはスパコンでも性能が十分でなく、AIで物理法則を解く技法を導入した。スパコンとAIを組み合わせ、数十年先の地球の気候を正確に予想する。

| 出典: Nvidia |
地球温暖化問題
イギリス・グラスゴーで開催されたCOP26は、世界の平均気温の上昇を、産業革命前に比べ、1.5度に抑える努力をすることを再確認した。同時に、世界の平均気温は1.1度上昇しており、その影響が各地で広がっていることに警鐘を鳴らした。今年は、記録的な熱波や豪雨など、気象災害が世界各地で発生している。カリフォルニア州は記録的な干ばつで、大規模な森林火災が続き、気候変動がこれらの災害を加速している(下の写真)。

| 出典: Nvidia |
メタバースでシミュレーション
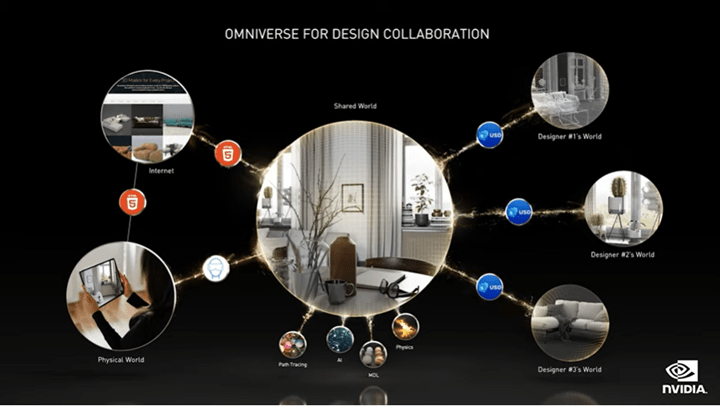
GTC 2021で、CEOであるJensen Huangが、NvidiaのプロセッサとAIを気候モデルに適用し、地球温暖化対策に寄与する手法を発表した。これはOmniverseで地球のデジタルツインを生成し、このモデルで地球の気候変動を解析する手法となる。具体的には、地球の気候モデル(Climate Model)を生成し、これをスパコンとAIでシミュレーションするアプローチを取る(下の写真、イメージ)。Nvidiaはメタバースの開発環境をOmniverseとして提供している。

| 出典: Nvidia |
気候モデルを生成
地球規模の気候モデルを生成することで、世界各地の気候を数十年先のレンジで予測する。将来の気候を正確に予想することで、危険性を正確に可視化でき、温暖化対策やインフラ整備のための基礎データとなる。天気予報は短期間の大気の物理現象を予測するが、気候モデルは数十年単位の気候シミュレーションで、物理学、化学、生物学などが関与し、巨大なモデルとなる。
豪雨や干ばつを予測
気候モデルを高精度で解析するには、地球規模の水の循環をシミュレーションする必要がある。これは「Stratocumulus Resolving」と呼ばれ、海水や地表面の水が、大気や雲を通して移動するモデルとなる(下の写真)。この循環が変わると、豪雨や干ばつによる被害が甚大となり、社会生活に大きな影響を及ぼす。

| 出典: NASA Goddard Space Flight Center |
専用スパコンと最新のAI技法
しかし、このモデルをシミュレーションするためには、地表面をメートル単位の精度で計算する必要がある。現行の気候モデルのメッシュはキロメートルで、これをメートルにすると、演算量は1000億倍となり、世界最速のスパコンを使っても処理できない。このため、Nvidiaは気候モデル専用のスパコン「Earth-2」を開発するとともに、物理モデルをAIで解く技術の研究を始めた。下の写真は気候モデルの計算量の増加を示している。水循環モデル(Stratocumulus Resolving)をスパコンだけで計算するには、2060年まで待つ必要がある。

| 出典: Nvidia |
物理法則をAIで解く
このため、AIで物理法則を解く技法の研究が進んでいる。気候モデルのシミュレーションとは、物理法則に沿った挙動を可視化することを意味する。自然界の動きは物理法則に従い、古典力学、流体力学、電磁気学、量子力学などがその代表となる。気候モデルでは流体力学が重要な役割を果たし、流体の動きはナビエ–ストークス方程式(Navier-Stokes Equations)などで記述される。ニューラルネットワークでこの方程式を解く技法の開発が進んでいる。(下の写真、AIでハリケーンなどの異常気象を予想したケース。)

| 出典: Nvidia |
物理法則をAIで解くフレームワーク
Nvidiaは物理法則をニューラルネットワークで解くためのフレームワーク「Modulus」を提供している(下の写真)。Modulusを気候モデルに適用することで、AIでナビエ–ストークス方程式の解法を求めることができる。従来方式に比べ処理時間が大幅に短縮され、AIの新しい技法として注目されている。このプロセスを専用のスパコン「Earth-2」で実行することで、高精度な気候モデルのシミュレーションが実現する。

| 出典: Nvidia |
気候変動に備える
気候モデルのシミュレーションで、数十年先の気候を正確に予測する。世界の主要都市は、数十年先に起こる気候条件に応じて、インフラ整備を進める。また、温暖化防止対策を策定する際に、どの方式が一番有効であるかを検証できる。地球のデジタルツインは、計測されるデータでアップデートされ、異常気象を高精度で予測し、地球温暖化対策の重要なツールとなる。