ロボティックスに関するカンファレンス「RE•WORK Deep Learning in Robotics Summit」がサンフランシスコで開催された (下の写真)。ロボットの頭脳であるDeep Learningにフォーカスしたもので、OpenAIやGoogle Brainなど主要プレーヤーが参加し、基礎技術から応用技術まで幅広く議論された。

| 出典: VentureClef |
Embodied Vision
フェイスブックAI研究所 (Facebook AI Research) のGeorgia Gkioxariは「Embodied Vision」と題して最新のAI技術を紹介した。Embodied Visionとは聞きなれない言葉であるが、Computer Visionに対比して使われる。Computer Visionがロボット (Agent) の視覚を意味することに対し、Embodied Visionはロボットの認知能力を指す。ロボットが周囲のオブジェクトを把握するだけでなく、人間のようにその意味を理解することに重点が置かれている。
Learning from Interaction
フェイスブックAI研究所はこの命題にユニークな視点から取り込んでいる。Gkioxariは、AIを人間のようにインテリジェントにするためには、「Learning from Interaction」が必要だと主張する。これは文字通り、インタラクションを通じて学習する手法を意味する。いままでにAIはデータセットからComputer Vision習得した。例えば、写真データセット「ImageNet」から猫や犬を判定できるようになった。これに加え、AIは環境 (Environment) のなかで、モノに触れて、その意味を学習することが次のステップとなる。Gkioxariは、赤ちゃんが手で触ってモノの意味を学ぶように、AIもインタラクションを通じ基礎知識を学習する必要があると説明した。
仮想環境を構築
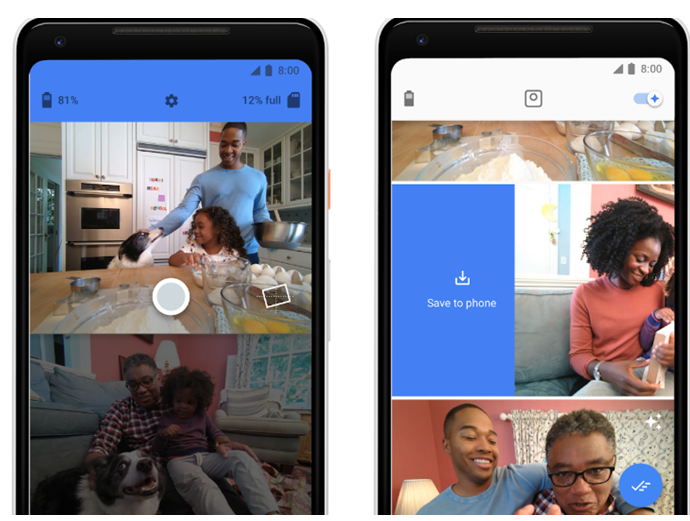
このため、フェイスブックAI研究所は、AI教育のために仮想環境「House3D」を開発した。これは住宅内部を3Dで表現したもので、ロボットがこの中を移動しながら常識を学んでいく。ロボットが移動すると、目の前のシーンが変わっていくだけでなく、シーンの中に登場するオブジェクトには名前が付けられている。つまり、ロボットは仮想環境の中を動き回り、オブジェクトに接し、これらの意味を学習する。ロボットは異なるタイプの部屋からキッチンの意味を把握し、そこに設置されているオーブンや食器洗い機などを学んでいく (下の写真)。

| 出典: Georgia Gkioxari |
学習方法
フェイスブックAI研究所は三つの視点からロボットを教育する。ロボットが仮想環境の中で、モノを見て言葉の意味を学習する。これは「Language Grounding」と呼ばれ、ロボットは環境の中でモノと名前を結び付ける (部屋の中で長い緑色のロウソクをみつけることができる)。二番目は、ロボットは家の中で指定された場所に移動する。これは、「Visual Navigation」と呼ばれ、ロボットは家の中の通路を辿りドアを開け、指定された場所まで移動する (寝室に行くように指示を受けるとロボットはそこまで移動する)。
EmbodiedQA
三つめは、ロボットは質問を受けると、家の中を移動してその解を見つけ出す。これは「EmbodiedQA」と呼ばれ、ロボットは回答を見つけるために仮想環境の中を移動する。従来のロボットはインターネット上で答えを見つけるが、EmbodiedQAは物理社会の中を移動して解を求める。例えば、「自動車は何色?」という質問を受けると (下の写真左側)、ロボットは質問の意味を理解し、家の中で自動車を探し始める。自動車はガレージに駐車されているという常識を働かせ、家の中でガレージに向かって進む。ロボットはその場所が分からないが、ここでも常識を働かせ、ガレージは屋外にあると推測する。このため、ロボットは玄関から屋外に出て、庭を移動し、ガレージにたどり着く。そこでロボットは自動車を発見し、その色が「オレンジ色」であることを把握する (下の写真右側)。

| 出典: Georgia Gkioxari |
必要な機能
このタスクを実行するためには、ロボットの頭脳に広範なAI技法が求められる。具体的には、視覚(Perception)、言葉の理解(Language Understanding)、移動能力(Navigation)、常識(Commonsense Reasoning)、及び言葉と行動の結びつき(Grounding)が必要になる。Gkioxariの研究チームは、前述の3D仮想環境「House3D」でEmbodiedQAのモデルを構築しタスクを実行することに成功した。
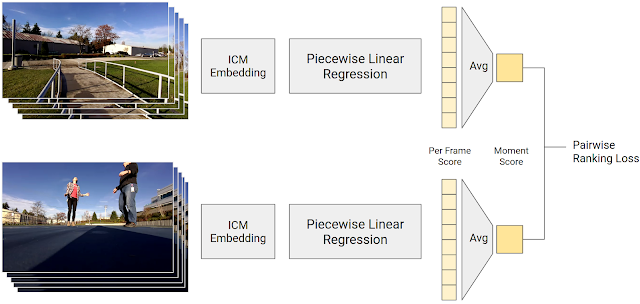
ロボットの頭脳
このモデルでロボットの頭脳はPlannerとControllerから構成され (下の写真)、Deep Reinforcement Learning (深層強化学習) の手法で教育された。Plannerは指揮官で、進行方向(前後左右)を決定し、Controllerは実行者で、指示に従って進行速度(ステップ数)を決定する。PlannerはLong Short-Term Memory (LSTM) というタイプのネットワークで構成され、上述の通り、これをDeep Reinforcement Learningの手法で教育する。Plannerは人間のように試行錯誤を繰り返しながら常識を習得する。
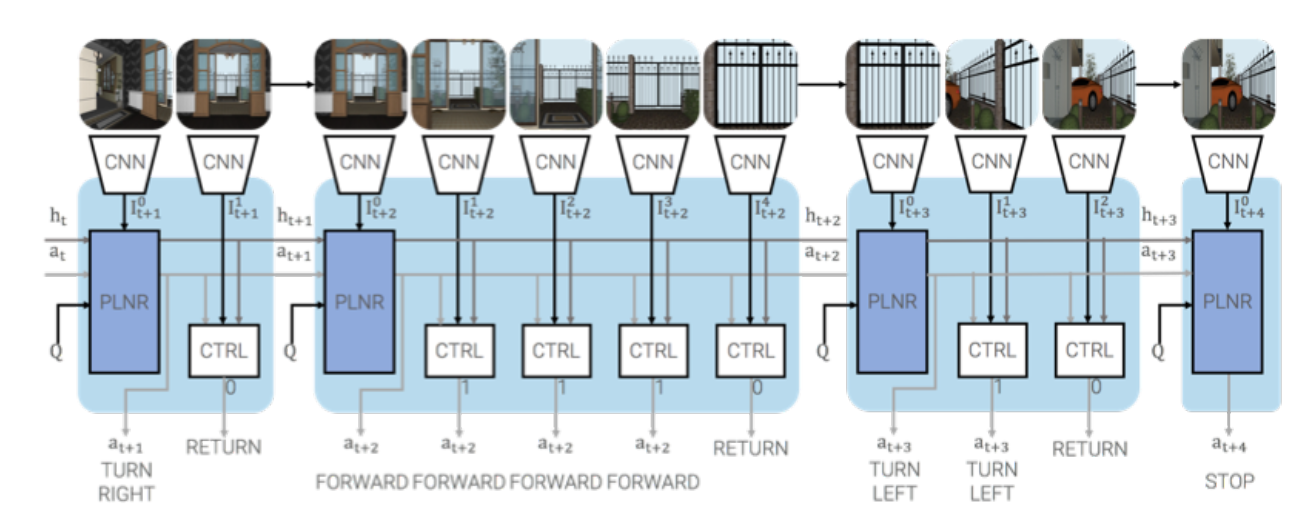
| 出典: Georgia Gkioxari |
知的なAIの開発は停滞
フェイスブックAI研究所は、これらの研究を通して、インテリジェントなロボットの開発を進めている。AIが急速に進化し、イメージ判定では人間の能力を上回り、囲碁の世界ではAIが人間のチャンピオンを破り世界を驚かせた。AIの計り知れない能力に圧倒されるが、AIは知的というにはほど遠い。AIはオブジェクト(例えば猫)の意味を理解しているわけではなく、また、囲碁という限られたタスクしか実行できない (例えばAlphaGOはクルマを運転できない)。いまのロボットは人間のように家の中を移動することさえできない。つまり、人間のようにインテリジェントに思考できるAIの開発はブレークスルーがなく滞ったままである。
精巧な仮想環境
このため、フェイスブックAI研究所は、全く異なるアプローチでAIを開発している。実社会を模した3D仮想環境の中でAIを教育し、この中でAIが複雑なタスクを自ら学んでいくことを目指している。AIが実社会の中で学習することで、人間のような視覚を持ち、自然な会話ができ、次の計画を立て、知的な思考ができるアルゴリズムを開発する。このためには、実社会そっくりな仮想環境が必要で、家の中を写真撮影したように忠実に描写した3D環境を開発している。同様にOpenAIやGoogle DeepMindもこのアプローチを取っており、精巧な仮想環境でDeep Reinforcement Learningの開発競争が激化している。
フェイスブックがロボット開発
ロボットの頭脳が知的になることで、人間の暮らしが根本的に変わる。フェイスブックは仮想アシスタント「M」を開発してきたが、製品としてリリースすることを中止した。Mはホテルのコンシェルジュのように、どんな質問にも答えてくれる仕様であったが、人間との会話トピックスは余りにも幅が広く、AIはこれに対応できなかった。また、フェイスブックはAIスピーカーを開発しているとも噂されている。Embodied Visionは仮想アシスタントやAIスピーカーを支える重要な基礎技術となる。更に、この研究が上手く進むと、家庭向けロボット開発のロードマップが見えてくる。フェイスブックがインテリジェントな家庭向けロボットを開発するのか、市場の注目が集まっている。