Googleが開発したイメージ認識アルゴリズム「Google Inception」は世界でトップレベルの性能を持つ。このソフトウェアは公開されており誰でも自由に利用できる。これを皮膚ガンの判定に応用すると専門医より正確に病気を判定できることが分かった。特殊なアルゴリズムは不要でガン検知システム開発の敷居が下がった。市場では皮膚ガンを判定するスマホアプリが登場しており医療分野でイノベーションが相次いでいる。

| 出典: Stanford Health Care |
皮膚ガン検出の研究
この研究はスタンフォード大学AI研究所「Stanford Artificial Intelligence Laboratory」で実施され、その結果が科学雑誌Natureに掲載された。これによると、Deep Learningアルゴリズムが皮膚ガンの判定において専門医より優れた結果を達成した。具体的には、Convolutional Neural Networks (CNN、イメージを判定するアルゴリズム) が使われ、AIの判定精度は21人の医師を上回った。
皮膚ガンの検出方法
一般に皮膚ガンを診察する時は、皮膚科専門医 (dermatologist) は肉眼や拡大鏡(dermatoscope) でその部位 (lesion) を観察する。悪性腫瘍であると診断した場合は生体から組織片を採取して調べるバイオプシー (Biopsy、生体組織診断) に進む。また、判定がつかない場合にもバイオプシーを実施し臨床検査で判定する。このバイオプシーがガン診断の最終根拠 (Ground Truth) になる。
アルゴリズムが上回る
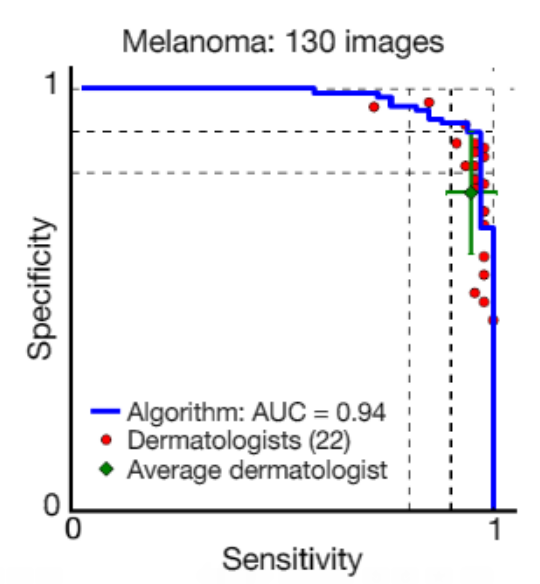
診断結果はアルゴリズムが皮膚科専門医の判定精度を上回った。条件を変えて三つのケースで試験が行われたが、いずれの場合もアルゴリズムが好成績を上げた。下のグラフはその一つのケースで、赤丸が医師の判定結果を青色グラフがアルゴリズムの判定結果を示す。右上隅に近づくほど判定精度が高いことを表している。アルゴリズムが殆どの医師の技量を上回っている。
| 出典: Sebastian Thrun et al. |
横軸は陽性判定 (正しくガンと判定) の精度で縦軸は陰性判定 (正しくガンでないと判定) の精度を示す。緑色の+が医師の判定精度の平均で、アルゴリズムがこれを上回る。対象はMelanoma (悪性黒色腫) とCarcinoma (癌腫) で判定件数は111、130、135件。上のケースはMelanomaで130枚のイメージを使用。
Googleが開発したソフトウェア
この研究ではガンを判定するアルゴリズムにConvolutional Neural Networksが使われた。具体的には、Googleが開発した「Inception v3 CNN」を利用。Inceptionはイメージデータベース「ImageNet」を使ってすでに教育されている。写真に写っているオブジェクトを高精度で認識でき、犬や猫の種類まで判定できる。この研究で同一のアルゴリズムがガンを正確に判定できることが分かった。
皮膚ガンのデータベース
研究チームはこのInceptionを変更することなくそのまま利用した。Inceptionが皮膚ガンを判定できるようにするため、ガンの写真イメージとその属性データを入力し教育した。スタンフォード大学病院 (先頭の写真) は皮膚ガンに関する大規模なデータベースを整備した。129,450件の皮膚ガンイメージ (Skin Lesion) とそれに対応する2,032種類の病気を対応付けたデータベースを保有している。このデータベースは病気の区分け (Taxonomy) とそれに対応するサンプルイメージから構成される。このデータを使ってInceptionを教育した。
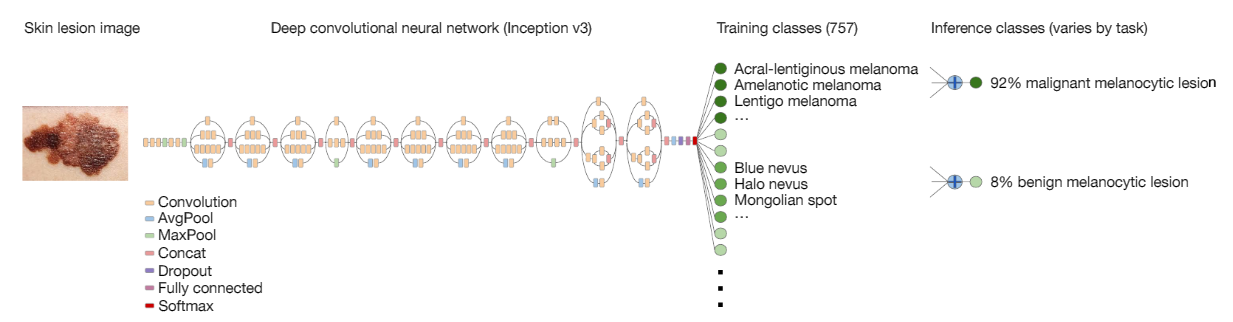
教育されたInceptionは1,942枚の写真で試験された。一方、専門医は375枚の写真に対して診断を下した。下の写真がアルゴリズムの概要で、写真 (左端) をInception (中央部、薄茶色の分部、CNNネットワークを示す) に入力すると757種類の皮膚疾病に分類し、これが良性であるか悪性であるかを判定する。
| 出典: Sebastian Thrun et al. |
Google Inceptionとは
この研究で使われたアルゴリズム「Inception v3 CNN」は公開されており、誰でも自由にTensorFlowで使うことができる。TensorFlowとはGoogleが開発したMachine Learning開発プラットフォームで、この基盤上でライブラリやツールを使ってAIアプリを開発できる。因みにInception v3 CNNは2015年のイメージコンテスト「ImageNet Challenge」で二位の成績を収め世界トップの性能を持つ (一位はマイクロソフト)。GoogleとしてはTensorFlowやInceptionを公開することで開発者を囲い込む狙いがある。
教育データの整備
Googleが開発したInceptionは身の回りのオブジェクトの判定ができるだけでなく、皮膚ガンの判定でも使えることが分かった。システム構成を変更することなくガン細胞の判定で威力を発揮した。ただ、開発には大規模な教育データが必要となり、データベース整備が大きな課題となる。同時に、このことは臨床データを所有している医療機関は高精度なガン診断システムを構築できることを意味している。
メディカルイメージング技術が急速
実際の有効性を確認するためには臨床試験を通しFDA (米国食品医薬品局) の認可が必要となる。製品化までの道のりは長いが、アルゴリズムをそのまま利用できるため多くのベンチャーがメディカルイメージング技術開発に乗り出している。スタンフォード大学研究チームはこのアルゴリズムをスマホアプリに実装することを計画している。研究成果をスマホで提供すると消費者は病院に行かなくても手軽に皮膚ガンを検知できる。
スマホでガン検診
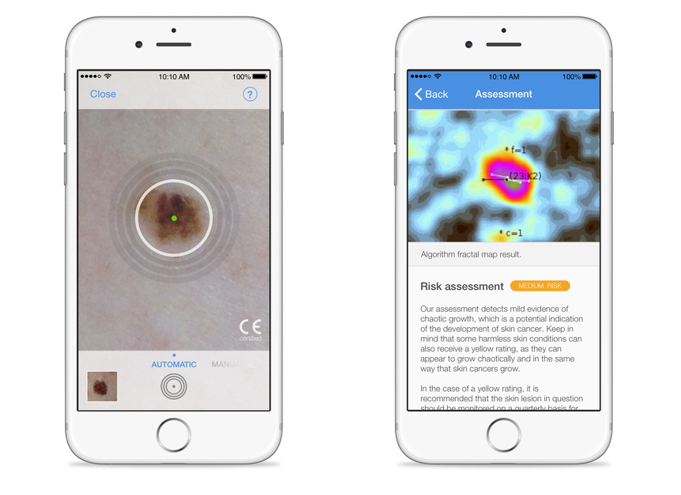
実際、市場には皮膚ガンを判定するスマホアプリが数多く登場している。スマホカメラで皮膚の黒点を撮影するとアプリはそれが皮膚ガンの疑いがあるかどうかを判定する。米国ではまだFDAの認可を受けたアプリはないが、多くの企業が参入を目論んでいる。(下の写真はオランダに拠点を置くSkinVision社が開発した皮膚ガンを判定するアプリ。ドイツとイギリスで臨床試験が実施され効用が確認された。FDAに認可を申請しており米国市場参入を目指している。)
| 出典: SkinVision |
未公認アプリは数多い
一方、FDAの認可を受けていない未公認簡易アプリは既に市場で流通している。注意書きを読むと「ガン検知精度を保証しない」と書かれているが、殆どの利用者は気にしないで使っている。あたかもスマホで皮膚ガンを判定できる印象を受けるがその効用は保障されていない。これらを使って拙速に判定するよりFDAなど政府機関から認定されたアプリの登場を待ったほうが賢明なのかもしれない。