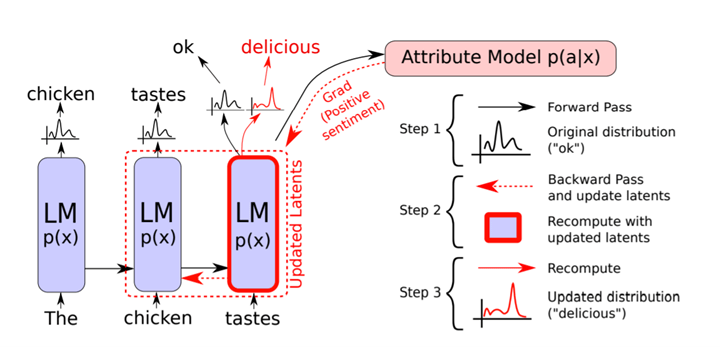
セキュリティの国際会議RSA Conference 2021(#RSAC)がオンラインで開催された。AIが社会に幅広く浸透し、その効用が理解されると同時に、国民はAIに漫然とした不安を抱き、その信頼性が低迷している。この問題に対処するため、米国政府はAIの機能を定義し、その信頼性を査定する研究を始めた。これはAIの品質を評価する試みで、医薬品と同じように、AI製品に品質保証書を添付する方策を検討している。
| 出典: National Institute of Standards and Technology |
アメリカ国立標準技術研究所
RSA Conferenceでアメリカ国立標準技術研究所(National Institute of Standards and Technology, NIST)のElham Tabassiがこの取り組みを説明し、信頼できるAI「Trustworthy AI」に関する研究成果を公表した。社会でAIが幅広く使われ、生産性が向上し、消費者は多大な恩恵を受けている。しかし同時に、失業者が増え、所得格差が増大しAIの問題点が顕著になっている。このため、NISTはAIの危険性を定量的に把握し、共通の理解を持つための研究を進めている。
AIの品質保証書
NISTはAIの信頼性を計測し、それを向上させるプログラム「Fundamental and Applied Research and Standards for AI Technologies (FARSAIT)」をスタートした。信頼できるAIとは何かを定義し、それらの要素を計測し、AIの安全性に関する指標を制定することを目標とする。国民はAIに関し漠然とした不安を抱いているが、NISTはこれを科学的に定義し、AIの品質保証書を制定することがゴールとなる。
品質保証書のドラフト
既に、NISTはAIの信頼性を査定するための試案を公開している。これは「Trust and Artificial Intelligence」と呼ばれ、NISTの考え方を纏めたプロポーザルで、一般からの意見を求めている。このプロポーザルがたたき台となり、寄せられた意見を集約し、最終的なAI査定方法を制定する。

| 出典: National Institute of Standards and Technology |
AIの信頼性を構成する要素
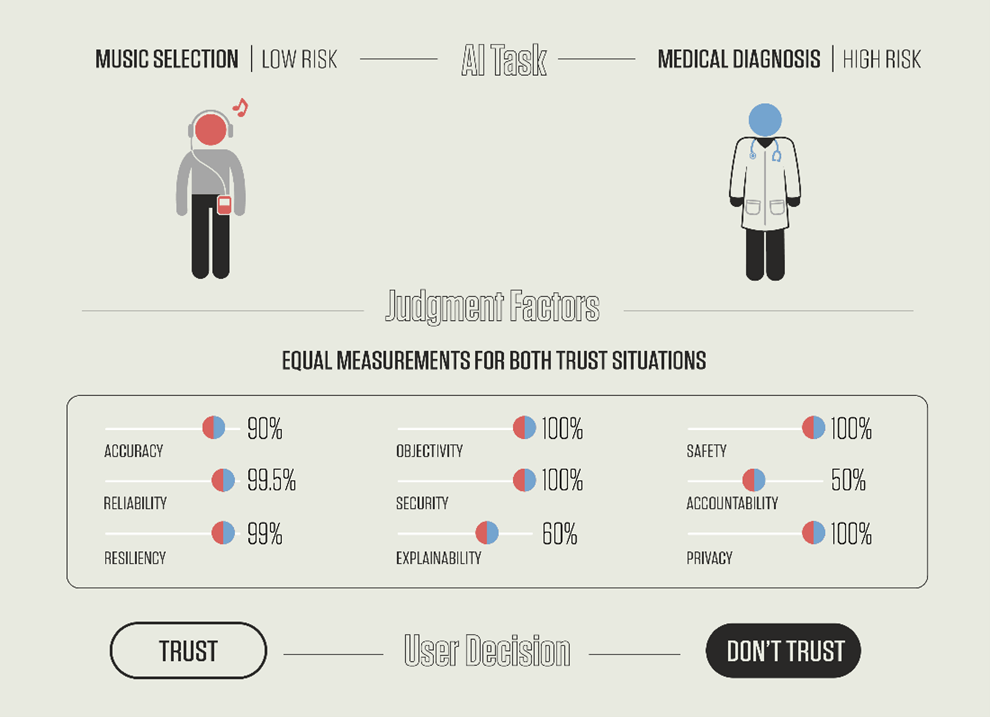
まず、AIの信頼性を構成する要素は何かを突き詰めることが最初のステップとなる。NISTはAIの信頼性は9つの要素で構成されるとしている(先頭の写真、枠の中)。「精度」(判定精度が高いこと)、「バイアス」(判定精度に偏りがないこと)、「説明責任」(判定理由を説明できること)、「プライバシー」(個人のプライバシーが保護されること)、「堅固」(システムが安定して稼働すること)などが構成要素になるとしている。
AI査定方法のモデル
NISTはAIの信頼性を評価するモデル「Perceived System Trustworthiness」を提案(上の写真)。これは、ユーザ(u)がシステム(s)でコンテンツ(a)を処理する際に、システムをどの程度信頼できるかというモデル(T(u,s,a))となる。このモデルは、ユーザ特性(U)とシステムの技術的信頼性(PTT、Perceived Technical Trustworthiness)から構成される。ユーザ特性とは利用者の主観で性別や年齢や性格や今までの経験などに依存する。
システムの技術的信頼性
問題はシステムの技術的信頼性(PTT)で、これをどう査定するかが課題となる。システムは上述の通り9の要素で構成され、PTTはこれら9の要素の重みづけ(Perceived Pertinence)と各要素の重要度(Perceived Sufficiency)で決まる。つまり、AIシステムの技術的信頼性は、対象とするコンテンツに対し、9の要素を査定し、統合した値で決まる。
AI信頼性を評価する事例
NISTは、AIの信頼性を評価する事例として、1)AIがガンを判定するケースと、2)AIが音楽を推奨するケースを提示している。前者は、画像解析AIが患者のレントゲン写真からガンを判定するケース。後者は、音楽ストリーミングでAIが視聴者の履歴を解析し好みの曲を推奨するケース。
9要素の評価
AIの信頼性は9の要素で構成されるが、その重要度は対象とするコンテンツにより決まる。ガン判定AI(下のグラフ、左側)と音楽推奨AI(右側)では各要素の重みが異なる。例えば、判定の「精度」に関しては、ガン判定AIでは極めて重要であるが、音楽推奨AIでは厳しい精度は求められない。仮に、AIの判定精度が90%と同じでも、ガン判定AIでは不十分と感じるが、音楽推奨AIではこれで十分と感じる。

| 出典: National Institute of Standards and Technology |
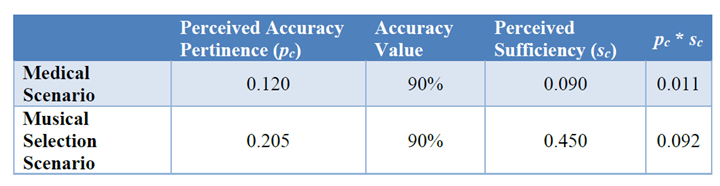
AI信頼性評価結果:「精度」のケース
NISTは、9項目の中の「精度」に関して試算した結果を示している。どうちらも「精度」が90%であっても、システムの技術的信頼性(PTT)は大きく異なる(下のテーブル、右端のカラム)。ガン判定AIではPTTが0.011で、音楽推奨AIではPTTが0.092となる。つまり、ユーザは音楽推奨AIに対しては信頼感を感じるが、ガン判定AIに対しては信頼感は90%下落する。
| 出典: National Institute of Standards and Technology |
AIシステム全体の評価
NISTの試案では、AIが判定する対象が何であるかが、ユーザの信頼感に大きく寄与する。音楽推奨AIのように、判定が外れても大きな問題がない場合は、AIへの評価は甘くなる。一方、ガン判定AIでは、判定が外れると生死にかかわる重大な問題となり、AIに対し厳格な精度を要求する(先頭の写真)。このように、AIの信頼性は対象コンテンツの内容により決定される。上記は「精度」に関する信頼性の結果で、その他8の要素を評価して、それらを統合してAIシステムに対する最終評価が決まる。
最終ゴールは法令の制定
これはNISTの試案で、このモデルを使い実際に計測して、AIの信頼性が数値として示される。これから、一般からの意見を取り込み、AIの信頼性に関するモデルが改良され、最終案が出来上がる。これがAI品質保証書のベースとなり、NISTはこれを法令で制定することを最終ゴールとしている。最終的にAI品質保証書に関する法令が制定されると、AI企業はこの規定に沿って対応することが求められる。

| 出典: Pfizer Inc. / BioNTech Manufacturing GmbH |
AI企業の責務
どのような内容になるかは今の段階では見通せないが、AI製品に機能概要や制限事項や信頼性など、品質に関する情報を添付することを求められる可能性もある。医薬品を買うと薬の効能や副作用や注意点が記載された説明書が添付されている(上の写真、Pfizer製コロナワクチンの品質保証書の事例、効用や副反応などが記載されている、ワクチン接種時に手渡された)。これと同様に、AI製品を販売するときは、企業は製品説明書や品質保証書を表示することを求められる可能性が高まってきた。