シリコンバレーで2019年12月、量子コンピュータのカンファレンス「Q2B」(#Q2B19)が開催された。IBMは基調講演で「IBM’s Hardware-focused Collaborative Quantum Network」と題し、量子コンピュータの開発経緯と共同研究の成果について説明した(下の写真)。量子プロセッサの性能は毎年倍増しており、このペースでいくと2020年代に高信頼性量子コンピュータが登場する。

| 出典: VentureClef |
IBM Q System One
IBMは2019年1月、世界初の商用量子コンピュータ「IBM Q System One」を発表している。システムは演算機構や冷却機構を統合し、一つのパッケージに格納される。プロセッサは20 Qubit構成で、エラー無く稼働できる時間(Coherence Time)は100マイクロセカンド。IBMはこれを「Quantum Devices」と呼び、最終目標の高信頼性量子コンピュータ「Fault-Tolerant Quantum Computers」と区別している。Quantum DevicesはいわゆるNISQ(Noisy Intermediate Scale Quantum Computer)タイプで、エラー発生率が高い中規模のマシンとなる。IBMは次期モデルは53 Qubitを搭載することを明らかにした(下の写真)。

| 出典: VentureClef |
量子コンピュータセンター
IBMは2019年9月、量子コンピュータセンター「Quantum Computation Center」をPoughkeepsie (ニューヨーク州)に開設したことを明らかにした。ここで15台のシステムが稼働しており、最大構成のシステムは53 Qubitを搭載している。これらのシステムは量子クラウド「IBM Q Experience」で一般ユーザに提供されている。また、大学や企業との開発コミュニティ「IBM Q Network」がこのシステムを使って量子アルゴリズムの開発を進めている。
量子プロセッサ開発経緯
IBMは量子コンピュータ開発で業界のトップを走っている。最初の量子プロセッサは5 Qubit構成で「Tenerife」と呼ばれ、2017年から量子クラウドで公開されている。その後、16 Qubit構成のプロセッサ「Melbourne」や20 Qubit構成のプロセッサ「Poughkeepsie」など複数のモデルが開発された。最新モデルは53 Qubit構成の量子プロセッサ「Rochester」で上記の量子コンピュータセンターで運用されている。
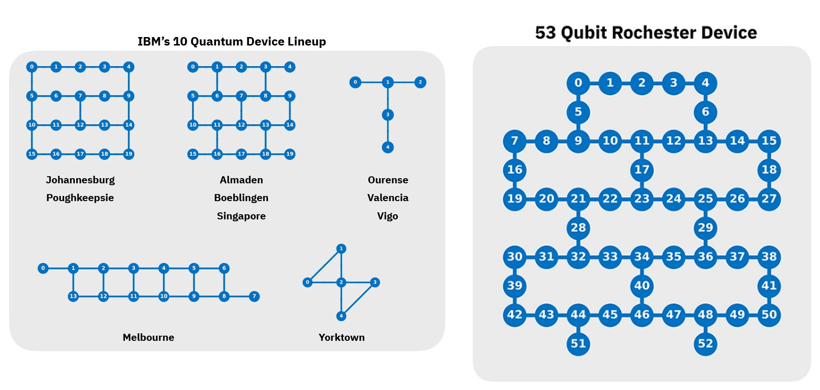
| 出典: IBM Research |
(上の写真は量子コンピュータセンターで稼働している量子プロセッサのモデル。左側は現行モデルで、右側は最新モデル「Rochester」。ダイアグラムは量子プロセッサにおけるQubitの配置とQubit間の連結(Connectivity)を示す。青丸がQubitで実線は連結を示す。Qubitの数が同じでも連結パターンが異なると特性が変わる。)
量子プロセッサの信頼性向上
量子プロセッサは改良が繰り返され信頼性が向上している。下のグラフはゲート演算を実行した時のエラー率を示したもの。具体的にはControlled NOT(CNOT)というゲート演算(二つのQubit間での論理演算)を実行したときのエラー率(右に行くほど高い)を示している。最上段は「Tenerife」(5 Qubit構成)で、最下段は「Boeblingen」(20 Qubit構成)を示し、エラー率が大きく低下しているのが分かる。これはQubitの物理特性を改善したことに加え、Qubitを繋ぐパターンが大きく影響している。
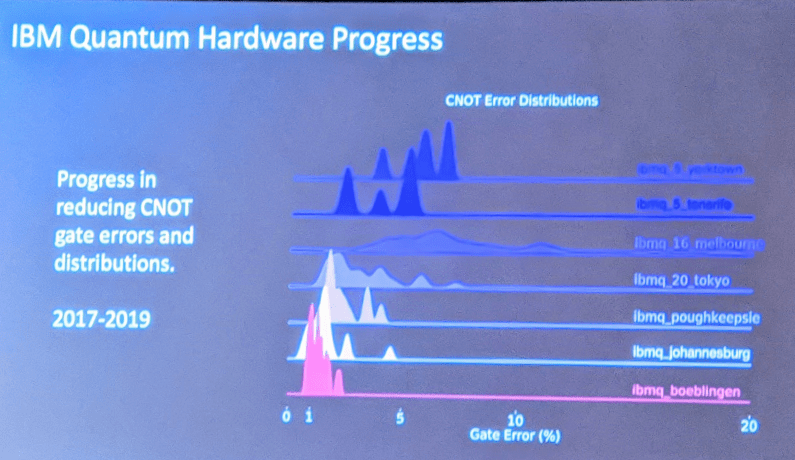
| 出典: VentureClef |
Quantum Volume
IBMは量子プロセッサの性能を評価する指標として「Quantum Volume」という概念を発表している。量子コンピュータの性能はQubitの数で決まるのではなく、プロセッサのアーキテクチャなどが影響する。このため、Quantum Volumeは、Qubitの数に加え、Qubit間の通信、ゲートの数(Qubitの連結数)、Qubitのエラー率などを総合的に加味して算出される。
Quantum Advantage
実際に量子プロセッサのQuantum Volumeが計測され公開されている(下のグラフ)。縦軸がQuantum Volumeで横軸は時間を示し、毎年、性能が向上していることが分かる。「Tenerife」(5 Qubit構成)のQuantum Volumeは4で、「Tokyo」(20 Qubit構成)は8で、Q System One (20 Qubit構成)は16となる。このペースで量子プロセッサの性能が向上すると、2020年代には「Quantum Advantage」に到達するとしている。Quantum Advantageとは量子アプリケーションがスパコンの性能をはるかに凌駕するポイントで、真の量子コンピュータの登場を意味する。
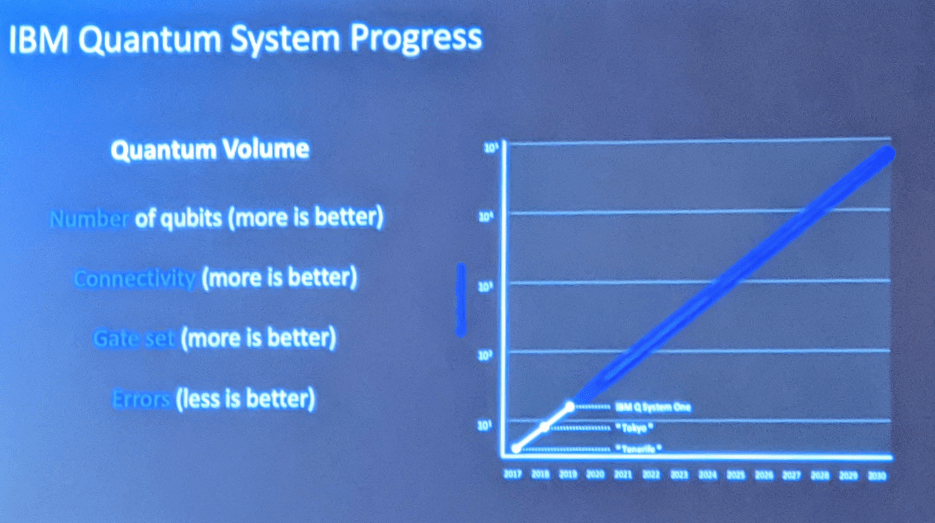
| 出典: VentureClef |
IBM Q Network
IBMは独自で量子プロセッサの開発を進めるが、量子アプリケーションについてはコミュニティ「IBM Q Network」を通じて開発する戦略を取っている。コミュニティは企業、大学、スタートアップから構成され、IBM Qを使って量子アプリケーションが開発されている。IBMは、製品が完成してから出荷するのではなく、開発中の量子コンピュータやシミュレータをコミュニティに公開し、量子アプリケーション開発を進める。(下の写真、IBMのブースでIBM Qについての説明が行われた。)

| 出典: VentureClef |
JPMorgan Chaseの事例
IBMはIBM Q Networkで大手企業と共同研究を進めているが、金融と化学の分野で大きな成果があったことを明らかにした。前者に関して、JPMorgan ChaseはIBM Qを使って金融アルゴリズムの研究を進めている。IBM QはNISQタイプの量子コンピュータで大規模なゲート演算はできないため、小規模なアルゴリズムの開発が中心となる。JPMorganが着目しているのはオプション価格の計算(option-pricing calculations)とポートフォリオのリスク査定(risk assessments)で、これらを量子コンピュータで実行し高速化を目指している。
量子アルゴリズム開発
実際に、リスク解析「Quantum Risk Analysis」の量子アルゴリズムを開発し、それをIBM Qで実行し、現行システムを上回ったことが報告された。現在、リスク解析ではMonte Carlo Simulationが使われるが、量子アルゴリズムはこの性能を上回った。(下のグラフ、演算結果のエラー率を示したもので、量子アルゴリズム(水色の線)はMonte Carlo Simulation(青色の線)に比べ速く収束することを示している。これは国債を保有するときのリスクを計算したもので、量子アルゴリズムは少ないデータで結果を出せることを意味する。)

| 出典: VentureClef |
日本における量子技術開発のハブ
この他に、三菱ケミカルとの共同研究で、リチウムイオン電池の分子構造を量子コンピュータで解析し、その成果が報告された。IBM Q Networkの主要メンバーが慶応大学で、ここに量子プロセッサが設置されており(上述の「Tokyo」プロセッサ)、三菱ケミカルの研究はこのマシンで実施された。更に、IBMはカンファレンスの直後、東京大学にIBM Q System Oneを設置することを発表した。IBMは日本の技術力に着目しており、このシステムで大学や企業と共同研究を進める。IBMはこのシステムが日本の量子技術研究のハブになると述べている。