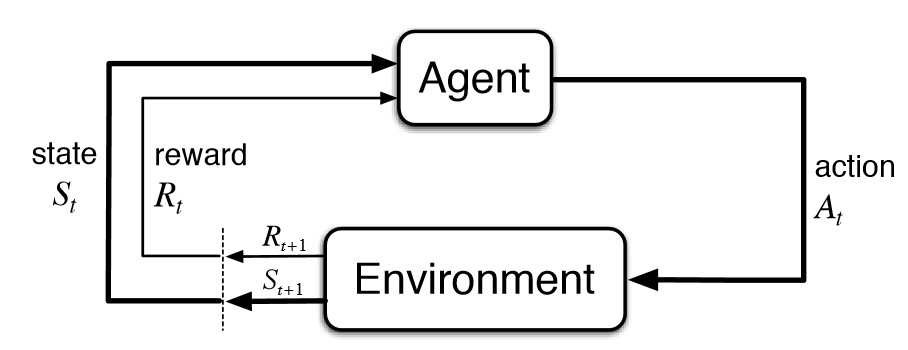
Nvidiaの研究チームはニューラルネットワークがセレブ画像を生成する技術を公開した。画像は実在の人物ではなくAIがセレブというコンセプトを理解して想像で描いたもの。セレブの他に、寝室、鉢植、馬、ソファー、バスなどのオブジェクトを現実そっくりに描くことができる。この技術はGenerative Adversarial Network (GAN)と呼ばれいま一番注目を集めている研究テーマだ。

| 出典: Karras et al. (2017) |
鮮明な偽物を生成する技術
この研究は論文「Progressive Growing of GANs for Improved Quality, Stability, and Variation」として公開された。この技法はGenerative Adversarial Network (GAN)と呼ばれ、写真撮影したように架空のセレブ (上の写真) やオブジェクトを描き出す。どこかで見かけた顔のように思えるがこれらは実在の人物ではない。GANが想像で描いたものでこれらのイメージをGoogleで検索しても該当する人物は見当たらない。このようにGANは写真撮影したように鮮明な偽物を生成する技術である。
GANはIan Goodfellowが論文「Generative Adversarial Nets」で発表し研究者の間で注目を集めた。GoodfellowはOpenAI (AI研究非営利団体、Elon Muskなどが設立) でこれを発表し、その後Googleに移籍し研究を続けている。
GANのネットワーク構造
GANはDeep Neural Networkの技法で二つの対峙するネットワークがコンテンツ (イメージや音声など) を生成する。GANは「Generator Network」と「Discriminator Network」から構成される (下の写真)。Generatorとは制作者を意味し、本物そっくりの偽のイメージを生成する (下の写真、上段)。Generatorにはノイズ (ランダムなシグナル) が入力され、ここから偽のイメージを生成する。Discriminatorとは判定者を意味し、入力されたデータが本物か偽物かを判定する (下の写真、右端)。DiscriminatorにはGeneratorが生成した偽のイメージ (Fake)、またはデータセットからの本物のイメージ (Real) が入力される。Discriminatorは入力データがFakeかRealかを判定する。

| 出典: Amazon |
なぜリアルなイメージを生成できるのか
GoodfellowはGANを偽札づくりに例えて説明している。Generatorは犯罪者で巧妙な偽札を作る。一方、Discriminatorは警察官で紙幣を鑑定する。犯罪者は偽札を作るが警察官はそれを見破る。犯罪者はこれを教訓に次回はもっと巧妙な偽札を作る。警察官も同時に目利き技術を向上させこれを見破る。回を重ねるごとに偽札が巧妙になり、ついに警察官に見破られない精巧な偽札を作れるようになる。冒頭の写真のセレブ画像がこの偽札に相当する。GANはGeneratorとDiscriminatorが対峙して (Adversarial) 極めて巧妙な偽物を生成する技法と言える。
Nvidiaの研究成果
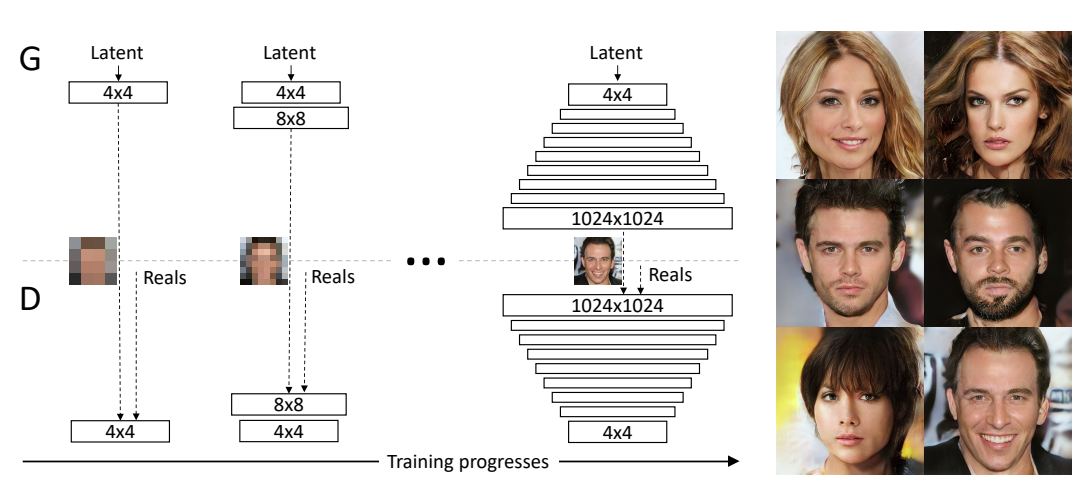
この分野で研究が進みGANは既に極めて巧妙な偽物を生成することができる。しかしGANの課題はアルゴリズムの教育で長時間の演算が必要になる。更に、アルゴリズムの挙動が安定しない点も課題となっている。このためNvidiaの研究チームは特殊なアーキテクチャ (下の写真) を開発しこの問題を解決した。
| 出典: Karras et al. (2017) |
Nvidiaが開発したネットワーク
上のダイアグラムでGと記載されている部分 (上段) がGeneratorを示し、Dと記載されている部分(下段)がDiscriminatorを示す。Discriminatorには本物のセレブ写真(Reals) とGeneratorが生成した偽のイメージ (Fake) が入力され、本物か偽物かを判定する。このGANの特徴は教育初期段階では低解像度 (4×4) のネットワーク (左端) を使い、教育が進むにつれて徐々に解像度を上げる。最終的には高解像度 (1024×1024) のネットワーク (右端) を使い鮮明なイメージ (右端の写真) を生成する。NvidiaのGANは出来栄えを検証しながら徐々に解像度を上げる構造となっている。
生成するイメージの進化
下の写真はGANが生成したイメージを示している。GANの教育を始め4時間33分経過した時点では低解像度 (16×16) のイメージが生成され人物らしき形が現れた (上段)。1日と6時間経過した時点では中解像度 (64×64) のイメージで顔がはっきりした (中段)。5日と12時間経過した時点では高解像度 (256×256) で人物が滑らかに描かれているが細部はゆがんでいる (下段)。19日と4時間経過した時点で高解像度 (1024×1024) のリアルな人物イメージが完成した (冒頭の写真)。

| 出典: Karras et al. (2017) |
教育のためのデータ
GANの教育にはセレブ写真のデータベース「Large-scale CelebFaces Attributes (CelebA) Dataset」が使われた。ここに登録されている3万枚のセレブ写真 (解像度は1024×1024) を使ってGANを教育した。GANは人の顔とは何かを学んだだけでなく、目や口や髭やアクセサリーなども学び、本物そっくりの架空のセレブを生成する。この技法の意義は写真と見分けがつかない高解像度のイメージを生成できる道筋を示したことにある。
イメージ生成にはコストがかかる
GANで鮮明なイメージを生成するためには大規模な計算リソースを必要とする。この研究ではNVIDIA Tesla P100 GPU (4.7 Tlops) が使われた。前述の通りGANの教育には20日程度を要した。GANのネットワークが改良されたものの、高解像度のイメージを生成するには大量の処理時間が必要となる。更に、描き出す対象はセレブなどに限定され、GANは教育された分野しか描けない。GANの教育時間を如何に短縮するか、また、幅広い分野をカバーするには更なる研究が必要となる。
フェイクニュース
GANが描き出したイメージは写真撮影したセレブと言われても疑う余地はない。リアルそっくりのフェイクで本物かどうかの判定は人間にはできない。GANが架空の世界を想像でリアルに描き出したことに不気味さを感じる。ソーシャルメディアでフェイクニュースが問題となっているがGANの登場でフェイク写真が事態を複雑にする。インスタ映えする写真はGANで創るという時代はすぐそこまで来ている。
GANを研究する目的
GANは諸刃の剣で危険性があるものの、その技法に大きな期待が寄せられている。GANは現行のDeep Learningが抱えている問題の多くを解決する切り札になる可能性がある。現行アルゴリズムを教育するためには大量のタグ付きデータが必要で、これがAI開発の最大のネックとなっている。GANに注目が集まっている理由はUnsupervised Learning (教師無し学習) とUnlabeled Data (タグ無し教育データ) の分野での研究が大きく進む手掛かりになると見られているからである。今後この分野で大きなブレークスルーが起こるかもしれない、そんな予感がする研究テーマである。