シリコンバレーのスタートアップ企業1Xはヒューマノイド・ロボット「NEO」の販売を開始した。NEOは家庭向けのロボットでお手伝いさんとして掃除や洗濯などの家事を実行する(下の写真)。NEOの価格は2万ドルで来年から出荷が始まる。NEOは大規模AIモデルを搭載し、汎用的にタスクを実行するスキルを獲得した。AIの進化でロボティックスが急進し、ヒューマノイド・ロボットが生活の一部となる。一方、難しいタスクは人間がテレオペレーションで実行する仕組みで、全自動で家事をこなすまでには時間を要す。

| 出典: 1X |
NEOの主要機能
NEOは人間の形状を模したヒューマノイド・ロボットで、二足で歩行し、二本の腕と五本の指を持つ手から構成される。NEOはセーターを着装し温かみを演出する。NEOは言葉を理解し、口頭での指示に従ってタスクを実行する(下の写真)。ドアの開閉、電灯の消灯、部屋の片づけ、植物への水やりなどをこなす。一方、洗濯、食器洗い、ペットへの餌やりなど複雑なタスクは、自動で実行することができず、人間のエキスパートがこれを支援する。これはテレオペレーション(Tele-Operation)と呼ばれ、専門スタッフがVRヘッドセットを着装し、NEOを遠隔で操作する。

| 出典: 1X |
ハードウェアの構造
安全を最優先とするコンセプトで、NEOの表面は3Dラティスのポリマーで覆われている。また、NEOはセーターを着装し、これらがクッションの役割を果たし、接触した際の衝撃を吸収する。NEOの駆動系はハーネスが使われ、モーターの動力をワイヤを介して手足を動かす(下の写真)。これにより、低消費電力で静かな動きを実現する。

| 出典: 1X |
ブレイン:VLAモデル
NEOの最大の特徴は高度なAIモデルをロボットのブレインとして搭載していることにある。このAIモデルは「Redwood AI」と呼ばれ、フロンティアモデルのコア技術であるトランスフォーマを利用している(下の写真、プロセッサ)。AIはセンサーからの視覚情報と人間の言葉を理解し、これをAIモデルで処理し、ロボットのハードウェアを制御する命令(アクション)を生成する。このタイプのAIモデルは「VLA (Vision-Language-Action)」モデルと呼ばれ、これが汎用的なスキルを修得するコア技術となる。

| 出典: 1X |
米国で販売を開始
1Xは今週から米国においてNEOの販売を開始した(下の写真)。価格は2万ドルで2026年から初期アクセス顧客向けに出荷される。また、サブスクリプション方式では月額499ドルでNEOをレンタルできる。ロボットの身長は5’6”(168センチ)で重量は66ポンド(30キロ)と、大人の形状であるが軽量なモデルとなる。NEOは家庭において人間とインタラクションすることを前提にデザインされている。
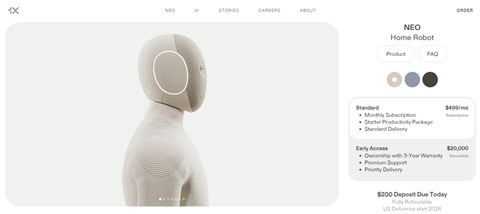
| 出典: 1X |
テレオペレーションとプライバシー保護
NEOは5Gネットワークや家庭のWi-Fiを通して1Xの監視センタとリンクする。オペレータがNEOの稼働状態をモニターし、複雑なタスクを実行するためのテレオペレーションを実行する。オペレータが屋内の映像を見ることになり、プライバシー保護が重要な要件となる。NEOは目の部分にカメラを搭載し、その画像がセンタに送信されるが、人間の顔の部分はマスクされ、プライバシーを保護する。また、利用者は立ち入り禁止区域「Geo-Fencing」を設定でき、プライバシーを確保する。NEOが収集したデータは、利用者の許諾のもと1Xに送信され、これがロボットの教育データとなる。1Xは初期ユーザと共同でアルゴリズムを開発する戦略を取る。
高齢化社会とヒューマノイド・ロボット
NEOは人間に代わり家事を代行するロボットとして開発されているが、高齢化に向かう米国でシニアの介護を重要な応用分野と位置付ける(下の写真)。多くの高齢者は介護施設に入居する代わりに、自宅で独立した生活を送ることを望んでいる。NEOはこれら高齢者の日常生活を支援することを大きな目的に技術開発を進めている。高齢化が進む日本においても、NEOのシニア介護のソリューションは重要な役割を果たすと考えられる。

| 出典: 1X |
家庭環境が最後の難関
ヒューマノイド・ロボットは企業の製造施設に導入されトライアルが進んでいる。BMWはクルマの製造ラインにヒューマノイド・ロボットを投入しその性能を評価している。これに対し、家庭向けのヒューマノイド・ロボットはNEOが最初のケースとなる。家庭環境で稼働するロボットは遥かに高度なスキルが求められる。製造施設はタスクが綿密に定義されクリーンな環境であるが、家庭においては床に様々なオブジェクトが置かれ、子供やペットなどが動き回り、掃除や炊事や洗濯など、広範なスキルが求められる(下の写真)。ヒューマノイド・ロボットにとって最難関の環境で、ロボットのブレインであるフィジカルAIの能力が試される。

| 出典: 1X |