合成生物学の国際会議「SynBioBeta」が開催され、最新の研究成果が発表された。合成生物学とは生物学と情報工学が融合した分野の研究で、遺伝子解析とAIが結び付きブレークスルーが生まれている。その一つがアンチエイジングの研究で、老化を抑止する医療品や製品が生まれている。

| 出典: One Skin |
One Skinという新興企業
SynBioBetaでOne Skin創業者のCarolina Reis Oliveiraがアンチエイジング研究の成果を説明した。One Skinとはサンフランシスコに拠点を置く新興企業で、合成生物学の手法でアンチエイジングの研究を進めている。最初の成果がスキンケアサプリメント「OS-01」(上の写真)で、今日から販売が開始された。これを顔や手の肌につけると、皮膚の寿命(Skinspan)を延ばすことができる。多くのアンチエイジング製品が販売されているが、One Skinは老化した細胞を取り除くことで皮膚を若返らせるアプローチを取る。
老化とは
人は年を取ると、肌にしわができ、関節が痛み、白髪が増える。老化することは自然の摂理で、避けることはできないと考えられてきた。しかし、老化の研究が進み、そのメカニズムが分かり始め、今では老化は病気であると認識されている。このため、シリコンバレーを中心に、老化という病気を治療する研究が進んでいる。
老化のメカニズム
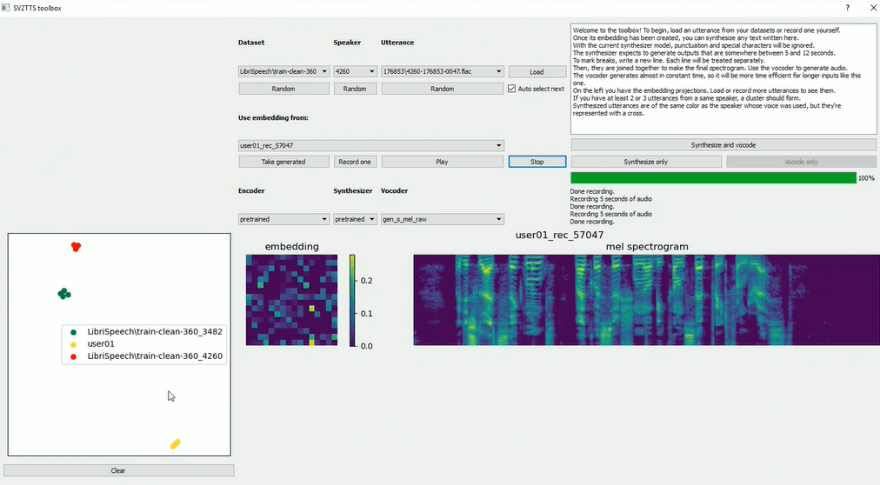
しかし、老化は極めて複雑な生理現象で、その詳細は分かっていない。アメリカ国立衛生研究所によると、老化の原因は九つあり、その一つが「Cellular Senescence」と呼ばれる現象である。これは「細胞の老化」という意味で、細胞が老化し、活性化が止まった状態を指す。この状態の細胞は老化細胞「Senescent Cells」と呼ばれる。人間の細胞は、生まれてから分裂を繰り返し成長するが、年を取るとこの細胞分裂が停止し、これ以上細胞分裂が起こらない状態となる。(下の写真、皮膚の細胞を示したもので、透明な部分が正常な細胞で、青色の部分が老化細胞)。
| 出典: One Skin |
老化の役割
細胞の老化は体を守るための現象で、老化細胞や傷ついた細胞は、免疫系(Immune System)により取り除かれる。免疫系は体内の病原体や遺物を殺滅するほかに、老化細胞を取り除く役割を担っている。老化は古くなった細胞の分裂を停止させる機能で、これらが取り除かれ新たな細胞が生まれ、組織が若返る。
老化が問題となるのは
しかし、老化が問題となるのは、老化細胞が取り除かれないまま体内に蓄積されるためである。加齢とともに免疫系の機能が低下し(Immunosenescent)、老化した細胞が取り除かれないまま体内に蓄積される。古い細胞が増えることで新たな細胞が生まれないだけでなく、周囲の正常な細胞にダメージを与え、これらを老化細胞に変えていく。これにより、ガンや心臓疾患や認知症などを発症する。また、関節炎や骨粗しょう症の原因となる。これが老化の問題点で、老化細胞が取り除かれないまま蓄積することで起こる。
One Skinの手法
One Skinはこの老化細胞を取り除く技術を開発している。肌のアンチエイジングに焦点を当て、肌に蓄積する老化細胞を取り除くことで、皮膚を若返らせる技術を開発した。膨大な数のペプチド(Peptide、アミノ酸で構成された短い分子)を調べ、OS-01というペプチドが老化細胞を取り除く効果があることを発見。研究室での実験でOS-01は皮膚の老化細胞を25%から50%取り除くことができその効果を実証した。また、人体に適用しその効果を確認した。(下の写真、老化した肌(左側)にOS-01を12週間適用すると張りのある肌(右側)となった。)

| 出典: One Skin |
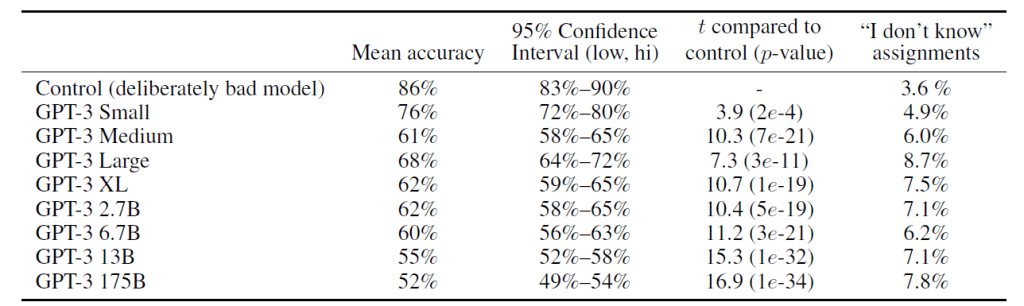
人の老化を止める薬
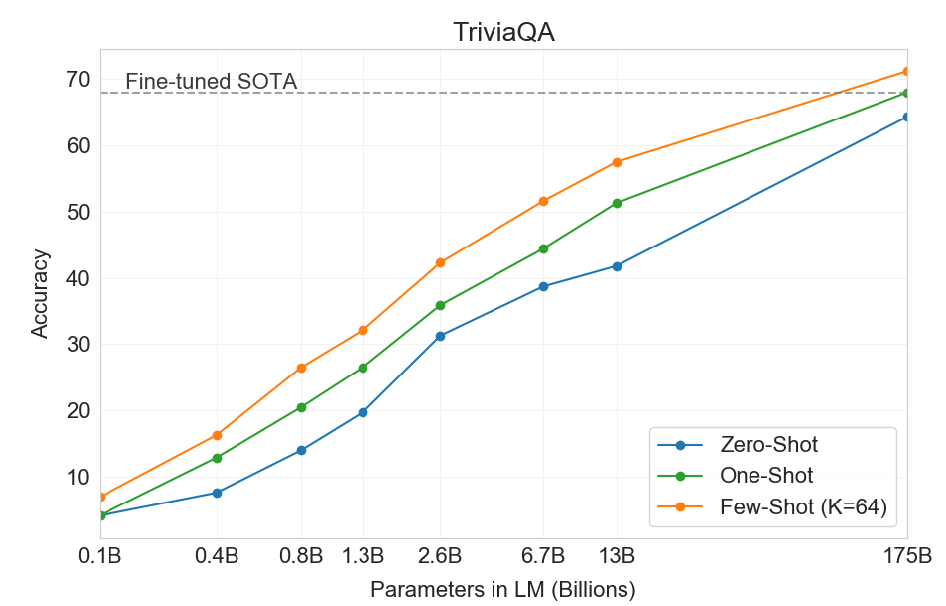
SynBioBetaでOliveiraは、この研究の最終ゴールは人の老化を抑止する医薬品を開発することであると述べ、そのロードマップを説明した。研究は進行中で、アンチエイジングに効果のあるペプチドOS-01を線虫の一種であるC elegansに適用すると寿命が12%伸びたと、その成果を説明した。次のステップはこれを人間に適用し、老化に起因する病気の治療を目指す。具体的には、皮膚角化疾患(psoriasis)や関節リウマチ(rheumatoid arthritis)の治療薬を開発する計画である。
100歳まで健康に暮らす
シリコンバレーの識者の間で健康寿命の捉え方が変わりつつある。老化の研究が急速に進化しており、100歳まで健康で活躍できると考える人が増えてきた。革新的なアンチエイジング医療の研究が盛んで、健康管理を怠らなければ、我々は新技術の波に乗り、余命が大きく伸びそうだ。「100 is the new 60」という言葉をよく耳にする。これは、これからの100歳は従来の60歳という意味で、100歳まで元気に働ける時代は目の前に迫っている。
[OS-01の開発手法]
遺伝子と細胞年齢
One Skinは生物学と機械学習を駆使しOS-01の開発に成功した。One Skinは、研究室でヒトの肌を培養し、このプラットフォームの上でアンチエイジングの研究を展開。また、機械学習の手法で細胞の年齢を推定するアルゴリズムを開発。遺伝子のマーカーを細胞年齢の指標として使った。このアルゴリズムを使い、開発したペプチドで細胞がどれだけ若返ったかを推定した。(下の写真、アルゴリズムの結果を示し、縦軸が細胞の年齢で横軸がその推定年齢。)

| 出典: One Skin |
ペプチドの生成
ペプチドのライブラリーから微生物を殺す機能を持つペプチドを検索。そこから、有望なペプチドを絞り込み、それを参照して、老化細胞を殺滅する機能を持つペプチドを人工的に生成した。生成したペプチドは、通常の細胞には影響はなく、老化細胞だけを殺滅する機能を持つ。このペプチドが「OS-01」で、アンチエイジングに効果があることを実験室で(In Vitro)確認した。更に、実際に人体に適用して(In Vivo)、その効果を確認した。(下の写真、左側が老化した皮膚で、右側はOS-01を適用して若返った皮膚、細胞が密になりカラム状の構造を取る)
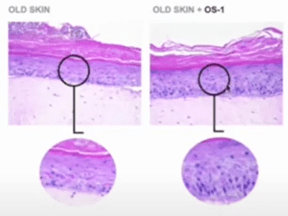
| 出典: One Skin |