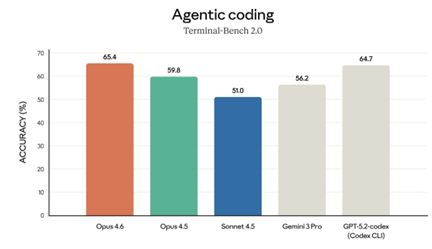
Anthropicはソフトウェアのセキュリティを強化する機能「Claude Code Security」をリリースした。これは、コーディング・エージェント「Claude Code」に搭載された機能で、コードベースをスキャンしてセキュリティの脆弱性を洗い出す。また、Claude Code Securityは、セキュリティホールを改修するためのコードを生成する。既に、AnthropicはClaude 4.6でオープンソースをスキャンして、500件のセキュリティホールを検知している。Claude Code Securityによりセキュリティ製品が不要になり、主要セキュリティ企業の株価が一様に下落した。

| 出典: Anthropic |
Claude Code Securityとは
「Claude Code Security」はコーディング・エージェント「Claude Code」に実装されている。Claude Codeの初期画面で「Scan Code」のボタンをクリックして起動させる(下の写真)。Claude Code Securityはコードベースをスキャンしてセキュリティの欠陥や弱点(脆弱性)を検知して、これを修正するための修正コード(パッチ)を生成する。エンジニアがこれを検証してソフトウェアに適用するプロセスとなる。Claude Code Securityはベータ版として一部の研究者向けに公開され評価作業を進めている。
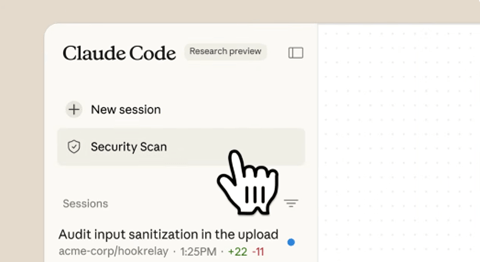
| 出典: Anthropic |
従来のセキュリティ手法
コードベースをスキャンしてセキュリティの脆弱性を検知するツールは幅広く使われている。「SonarQube」や「Checkmarx」などがその代表で、コードベースをスキャンして安全性に関する問題点を見つけ出す(下の写真)。これらは開発中のコードベースを検証し、セキュリティに関する問題点を洗い出すために使われる。その手法は「Static Application Security Testing」と呼ばれ、事前に設定したルールに準拠してセキュリティホールを検知する仕組みとなる。
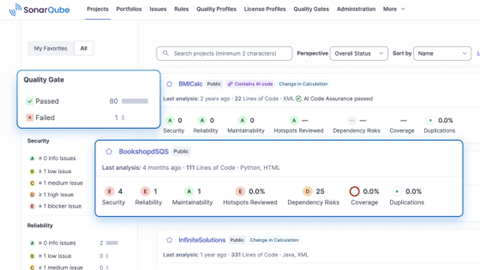
| 出典: SonarQube |
Claude Code Securityの手法
これに対し、Claude Code SecurityはAIモデルをベースとし、インテリジェントな手法でセキュリティの脆弱性を検知する。Claude Code Securityは人間のようにコードを読み、その構造や意味を理解する。これにより、コンテクストの視点から問題点やエラーを見つけ出す。シンタックスにエラーがなく、正常にコンパイルでき、スペック通り機能するコードでも、コードのロジックを検知し問題点を見つけ出す。
Claude Code Securityが脆弱性を検知した事例
EコマースサイトでClaude Code Securityがセキュリティホールを検知した事例(下の写真)。このサイトはハッカーがデータに攻撃命令「Command Injection」を挿入しシステムの制御を奪う脆弱性がある。コードが外部ウェブサイトのデータを読み込む構造となっており、ハッカーはデータにShell Command(基本ソフトを操作する命令)を挿入すると、このコマンドが実行されEコマースサイトの制御を奪われる。

| 出典: Anthropic |
プルリクエストとマージ
Claude Code Securityはセキュリティの脆弱性を埋めるためにパッチを生成する。このパッチをそのままソフトウェアに適用するのではなく、人間がこれを検証して、正しいことを確認して実施するプロセスとなる。ソフトウェア開発の観点からは、Claude Code Securityが修正コードを生成して、チームメイト(人間)にこの検証を依頼する。これは「プルリクエスト(Pull Request)」と呼ばれ、この過程をClaude Code Securityが担う。人間がリクエストされたコードを検証し、正しいことを確認して、メインのコードに「マージ(Merge)」するプロセスとなる。最終判断はあくまで人間で、修正コードの責任は人間が担う。(下の写真、Claude Code Securityが生成したパッチ。上述の「Shell Command」を実行する命令が消去され、ハッカーは悪意あるコマンドをインジェクトしても、それはテキストとして処理され実行されない。)
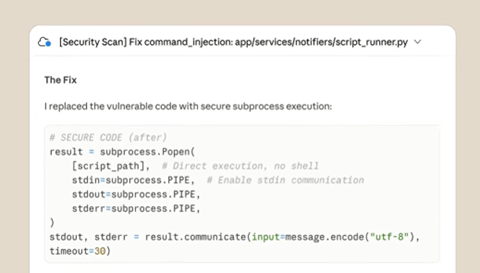
| 出典: Anthropic |
セキュリティ企業の株価下落
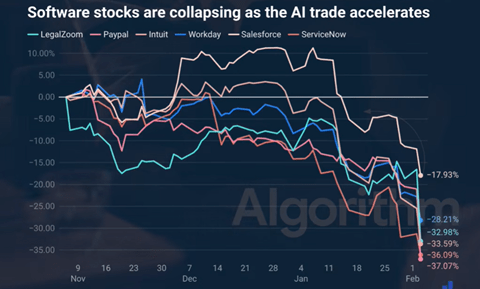
AnthropicがClaude Code Securityをリリースした直後に、米国の主要セキュリティ企業の株価が下落した(下のグラフ)。セキュリティ大手のCrowdStrikeは8%、Zscalerは11%、下落した。現行のセキュリティ製品はルールベースで脆弱性を検知するが、Claude Code Securityは人間のようにコンテンツを理解してセキュリティホールを埋める。投資家の間で現行モデルがClaude Code Securityに置き換えられるとの懸念が広がっている。
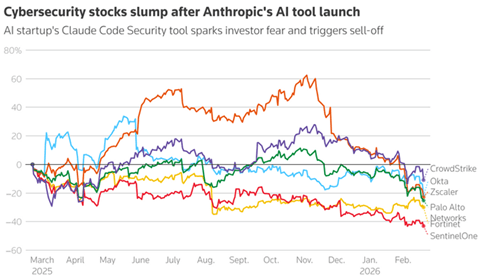
| 出典: SeekingAlpha |
セキュリティ企業の反論
これに対し、セキュリティ企業はClaude Code Securityは市場の一部をカバーするだけで、その影響は限定的であると反論している。セキュリティの対象分野は広く、Claude Code Securityは「Application Security」に区分される。これは、ソフトウェアなどアプリケーションのセキュリティを対象とする。この他に、サイバー攻撃をリアルタイムで検知する「Endpoint Security」、ファイアーウォールなど「Network Security」、認証管理など「Identity Management」など幅広い分野でセキュリティ製品が活躍している。Claude Code Securityは製品ポートフォリオのごく一部で、影響の範囲は限られると主張する。
シンメトリックな脅威
サイバー攻撃とその防御は「シンメトリックな脅威(Symmetric Threats)」と呼ばれる。サイバー攻撃ではAIを悪用し、システムの脆弱性を見つけ出し、そこから侵入してシステムの制御を奪う。これに対し、防御側はAIを活用し、システムをスキャンして脆弱性を洗い出し、問題個所を修正する。また、AIでサイバー攻撃のシグナルを検知し、侵入を食い止める。攻撃側と防御側で技術競争が進む中、防御側は攻撃者より一歩先行することで攻撃を食い止める。このため、高度なAIセキュリティを開発することが国家安全保障にとって至上命題となる。