Anthropicは中国企業からAIモデルの知識を盗み出す攻撃を受けたことを明らかにした。DeepSeekなど中国企業は「知識蒸留(Knowledge Distillation)」という手法で、Anthropicの先進モデル「Claude」から推論機能などを抽出した。米国政府はGPUプロセッサを中国に輸出することを制限しているが、中国企業はClaudeの知識を抽出することでこの規制を迂回した。攻撃手法は巧妙で、中国企業は巨大ネットワークを構築し、多数のアカウントから発信元情報(IPアドレス)を偽り、Anthropicのサーバにアクセスした。DeepSeekが短期間で高機能なAIモデルを開発し米国市場に衝撃を与えたが、Anthropic Claudeのスキルを盗用することでこれを達成したことが判明した。

| 出典: Anthropic |
攻撃の概要
Anthropicは2月23日、中国企業DeepSeek、 Moonshot、MiniMaxから「知識蒸留(Knowledge Distillation)」という手法で大規模な攻撃を受けたことを発表した。これら企業は、Anthropic Claudeから不正な手法で知識を蒸留(Illicit Distillation)し、AIモデルの開発で利用した。知識蒸留はAI開発で一般的に使われる技法であるが、他社の技術を抽出することは違法行為となる。
知識蒸留とは
知識蒸留は大規模モデルのスキルを抽出し、それを小規模モデルに転移し、短時間・低コストでAIモデルを開発する手法となる(下の写真)。AI開発で幅広く使われており、Anthropicのケースでは、ハイエンドモデル「Opus」の知識を知識蒸留の手法でローエンドモデル「Haiku」に転移した。HaikuはOpusの多くのスキルを修得し、モデルの開発を短時間・低コストで達成した。
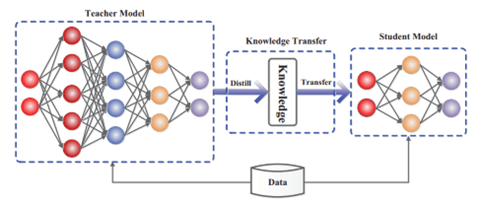
| 出典: Jianping Gou et al. |
不正な知識蒸留
これに対し中国企業三社は、知識蒸留の手法を、先進技術を盗むために悪用した。中国企業が標的とした先進技術はClaudeのAIエージェントに関連するもので、推論機能、コーディング機能、ツールを使う機能などが抽出された。攻撃の規模は巨大で、24,000の不正アカウントから1600万回のアクセスを受けた。不正な知識蒸留はAnthropicの使用契約に違反するだけでなく、米国の輸出規制にも抵触する。
中国への輸出規制
米国政府はNvidia GPU最新モデルなどAIプロセッサを中国に輸出することを規制している。中国企業がGPU最新モデルで高度なAIを開発することを制限することを目的とする。同時に、米国政府は中国から米国のAIモデルにアクセスすることを禁止している。プロセッサだけでなくソフトウェアに関しても、中国企業が使うことを禁じている。中国企業はGPU最新モデルが使えない環境で、Anthropic Claudeの知識を盗用することで、短期間で高度なモデルを生成した。
中国企業三社の攻撃手法
中国企業からの攻撃は大規模で、巧妙なネットワークを構築することで、Anthropicの防衛網を突破した。また、中国企業三社の攻撃対象技術は異なり、開発している製品に必須な技術を抽出したことが分かる。企業ごとの攻撃の手法は:
- DeepSeek:15万回のアクセスで推論機能を抽出 [高度な推論機能を持つ「DeepSeek-R1」をリリースしAI市場に衝撃をもたらした](下の写真)
- Moonshot AI:340万回のアクセスでエージェント機能とコーディング機能を抽出 [大容量メモリ(コンテキストウィンドウ)を搭載するモデル「Kimi」を開発]
- MiniMax:1300万回のアクセスでコーディング機能とツールを使う機能を抽出 [パーソナリティやマルチモダル機能に特徴がある個人向けのAIモデル「Talkie」を開発]
| 出典: DeepSeek |
DeepSeekのケースを検証すると
DeepSeekの攻撃手法を検証すると中国企業のAI開発戦略の特殊性が浮かび上がる。DeepSeekの攻撃は三つの要素から構成され、短期間で高度な推論モデルを開発できた理由が分かる。
- 推論スキルの抽出:攻撃の目的は知識蒸留でClaudeに15万回アクセスしてスキルを盗み出した。DeepSeekのターゲットは推論機能で、Claudeに特殊なプロンプトを入力し、Claudeが思考する過程「Chain of Thoughts」を入手した。このChain of ThoughtsをDeepSeek R1に入力することで推論機能をコピーした。
- 同期型トラフィック:DeepSeekは巧妙な手法でAnthropicの防御システムを掻い潜った。単一のアカウントから大量のプロンプトを発信すると、攻撃のシグナルと判定され、Anthropicはトラフィックを遮断する。このため、多数のアカウントから構成されるネットワーク「Hydra Network」を構築し、アカウント間でClaudeへのアクセス時間を調整し、ロードバランシングによる攻撃を実行した。単一のアカウントからのアクセス時間を短くし、作業を持ち回りで実行した。
- 中国政府の検閲:中国政府はAIモデルが中国共産党の思想に準拠することを求める。DeepSeekは天安門事件など不都合な情報を出力することは禁止されている。しかし、出力を抑制すると利用者から知識が不十分と批判される。そのため、DeepSeekはClaudeに最適な解答モデルを生成することを求め、この回答をベースにDeepSeekを教育した。
知識蒸留の危険性
Anthropicは、中国企業がClaudeの知識をコピーすることで、基礎研究のフェイズをスキップして、短期間に米国モデルに追い付くことができる、と警鐘を鳴らした。更に、Claudeのスキルが抜き取られると、中国のAIモデルが高度なインテリジェンスを持ち、それが悪用されると重大なリスクが発生する。AnthropicはClaudeが悪用されてCBRN(Chemical, biological, radiological, nuclear)兵器を開発することを抑制するため、ガードレールを設け兵器開発に関する回答をブロックしている。しかし、中国企業がガードレールを設けないでそのまま使うと、CNRN兵器の開発に繋がり、世界の安全保障が脅かされる。
OpenAIの議会報告書
OpenAIはこれに先立ち、米国連邦議会下院の委員会に、中国企業による知識蒸留に関する報告書を提出した。OpenAIは、DeepSeekが知識蒸留の手法でOpenAI GPT-4やo1からスキルをコピーしたと述べ、中国企業は短期間で度高度な推論モデルを生み出したと結論付けた。また、DeepSeekは第三者のプロキシサービス(「Obfuscated Proxy」、デバイスが米国内にあるよう装う手法)を使ってOpenAIの制限を掻い潜った。OpenAIは中国からのアクセスを禁止しするためジオブロッキングを導入しているが、Obfuscated Proxyを使うことでこれを突破した。
| 出典: Google Gemini Pro Image |
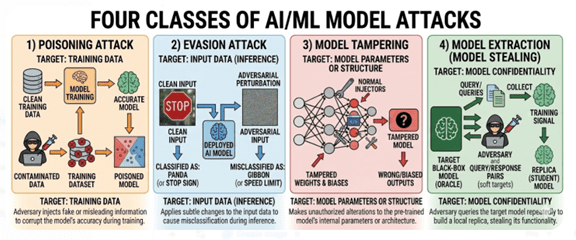
AIモデルへのサイバー攻撃は多彩
AIモデルはサイバー攻撃への耐性が低くセキュリティ強化が課題となってきた。AIモデルへのサイバー攻撃は四種類に区分され(上の写真)、知識蒸留は「Model Extraction」という攻撃手法となる。AIモデルに特殊なプロンプトを入力し、アルゴリズムの中身を盗み出す攻撃となる。この他に、AIモデルは教育と実行の過程でサイバー攻撃を受ける。前者は教育データを汚染する手法で、「Poisoning Attacks」と呼ばれ、開発されたモデルは正常に稼働しない。後者は実行時に、AIモデルに悪意あるデータを入力するもので「Evasion Attacks」と呼ばれ、システムを誤作動させる。この他に、AIモデルのバイアスや重みを改ざんし、システムを誤作動させる「Model Tempering」という攻撃がある。AnthropicとOpenAIだけでなく、高度なAIモデルを運用している企業はサイバー攻撃を受ける可能性が高く、セキュリティを強化することが喫緊の課題となる。