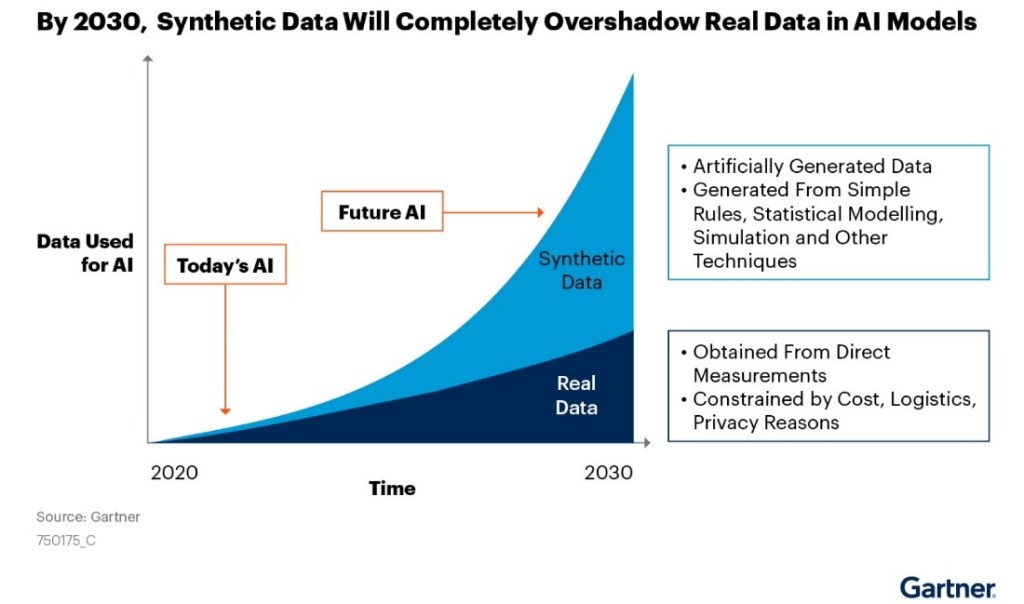
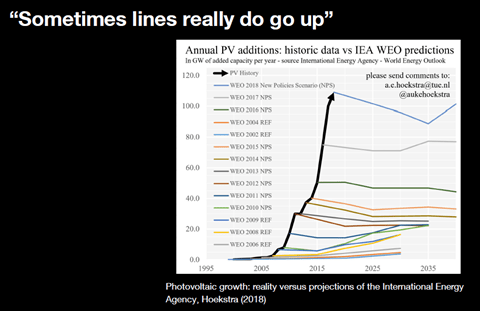
OpenAIは推論モデル「o1」をリリースし新たな市場を切り開いている。推論モデルとは人間のように論理的な思考ができるAIで、与えられたテーマを分類整理して、筋道を立てて結論を導く機能を持つ。科学や数学やコーディングで高度な機能を発揮するが、政治や経済など社会生活に関連する分野でも論理的な議論を展開する。GPT-4oなどGPTシリーズは汎用的な機能を提供するが、o1は複雑なタスクを実行でき科学技術分野に強みを発揮する専用モデルとなる。実際に使ってみると両者の違いが際立ち、o1はインテリジェンスが強化されていることを実感する。

| 出典: OpenAI |
製品概要
OpenAIは推論モデル「o1-preview」とその小型版「o1-mini」をリリースした。これらは製品化前のプレビュー版で、未完成のモデルであるが推論機能を体験することができる。「o1」はGPTシリーズとは異なる新たな製品ラインを形成する。o1はインファレンスのプロセスを強化したモデルで、問われたことを即座に回答するのではなく、熟慮して最適な解を生成する。o1は複雑な問題を解決することに強みを発揮し、科学、数学、コーディングで高度な機能を示す。
推論機能を理解する
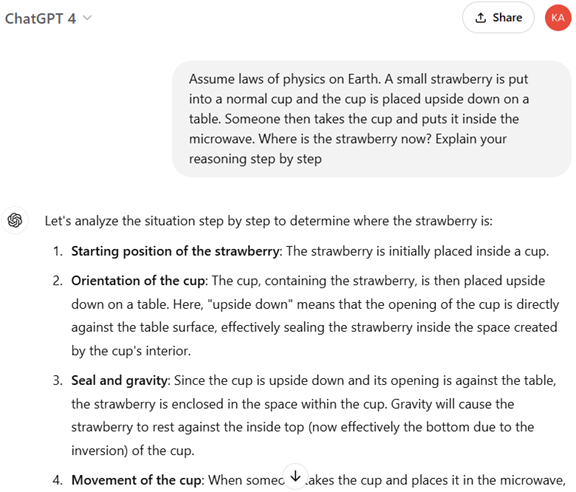
o1の基本機能は推論(Reasoning)で、問われたことを整理して、筋道を立てて解釈を進め、結論を引き出す。実際に、物理に関する問題を問うと、o1はこれを順序立てて考え解を導き出した(下の写真)。「カップにイチゴを入れて、これをひっくり返し、カップを電子レンジに入れると、イチゴはどこにあるか」との質問に、o1はこの質問をステップごとに解析し、回答にたどり着いた:
ステップ1:初期状態、カップにイチゴを入れる
ステップ2:カップをひっくり返す、イチゴはテーブルと接触
ステップ3:カップを取り上げる、イチゴはテーブルに留まる
結論:イチゴはテーブルの上にあり、電子レンジには入らなかった
o1はプロセスを順序立てて考察することで解を引き出すことができた。

| 出典: OpenAI |
他のモデルはこの問題を解けない
この問題は人間にとっては常識であるが、大規模言語モデルはこれを解くことができない。OpenAIを含む主要企業のハイエンドモデルにこの問題を質問したが、どのモデルも正解を導くことができなかった。モデルの回答を纏めると:
- OpenAI GPT-4:イチゴはひっくり返したカップの中にある (下の写真)
- Google Gemini 1.5 Pro:カップをひっくり返すとイチゴはカップ内に留まる
- Anthropic Claude 3 Opus:イチゴは重力で下に落ちるが、カップをひっくり返すとイチゴはカップ内に留まる
これらのモデルの推論の過程を検証すると、どのモデルも物理法則を理解しているが、これを実際のモデルに適用することができない。論旨は事実ではなくハルシネーションで、大規模言語モデルの限界を示している。
| 出典: OpenAI |
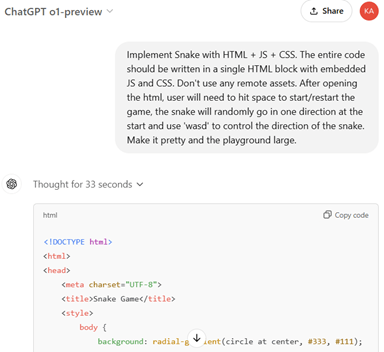
言葉でコーディング
o1はコーディング機能が大きく進化し、言葉だけでプログラムを生成することができる。o1にビデオゲーム「Snake Game(ヘビゲーム)」をコーディングするよう命令すると、これに従ってプログラムを生成する。その際に、プログラム言語やゲームの仕様を指示すると、これらを正確に反映する。「Snake GameをHTMLをベースにJSとCSSでコーディングし、カーソルの操作をWASDキーで行う」と指示すると、ブラウザーで稼働するHTMLベースのゲームを生成した(下の写真上段)。これを実際にブラウザーで稼働させるとSnake Gameが起動した(下段)。

| 出典: OpenAI |
トランプ政権の関税政策についてアドバイスを求めると
o1は政治経済に関する政策を論理的に解析する機能があり、経済政策を評価するツールとして使うことができる。トランプ次期大統領は中国からの輸入品に40%の関税を上乗せするとしており、この政策についてo1に意見を求めた(下の写真)。o1は関税の仕組みを説明し、この政策のメリットとデメリットについて評価し、結論を導き出した。米国が関税を中国との交渉の手段として使うことで、有利な条件を引き出せるが、国内で輸入品の価格が上がり、また、報復関税などデメリットが大きいと解析。o1は、関税を上乗せすることは実質的にマイナス面が大きいとして、この政策を見直すよう提言している。
| 出典: OpenAI |
トランプ政権の関税政策に日本はどう備える
トランプ次期大統領は同盟国からの輸入品に10%から20%の関税を上乗せするとしており、o1に日本が取るべき対策について尋ねた(下の写真)。o1はアメリカの関税引き上げに対する日本が取るべき政策を10項目示し、これらのオプションを検討し多角的なアプローチが必要であると提言した。特に、外交による交渉を進めながら、他国と連携して世界貿易機関(WTO)に提訴する準備を推奨。また、(トランプ政権により日米関係は抜本的に変わるので)、新しい市場の開拓や貿易相手国を模索することも必要と助言した。

| 出典: OpenAI |
o1の使い方
o1を使ってみると今までの大規模言語モデルとは特性が大きく異なる。従来モデルであるGPT-4oは、テキストやイメージやオーディオを生成するマルチモダルで、汎用的なプロセッサとなる。これに対し、o1は極めて高度な専門性を持ち、量子力学、遺伝子工学、ヘルスケア、経済学などの分野で複雑なタスクを実行できる。人間に例えると、GPT-4oは大学生のレベルで、o1は大学教授に匹敵し、専門分野の共同研究者として使うことができる。
推論機能を強化する手法
o1はGPT-4oなど他の言語モデルと同様にプレ教育されたモデルであるが、実行時に計算資源がアサインされ、インファレンスのプロセスを強化したモデルとなる。インファレンスの処理で即座に回答を生成するのではなく、与えられたタスクを解決するために熟慮するプロセスが追加された。具体的には、複数の解を生成し、これを検証して最適な解を選ぶ方式となる。実際に、「Snake Game」のコーディングでは、インファレンスに33秒の時間が費やされた。この方式は「Test Time Compute」と呼ばれ、実行時のプロセスが強化され、これにより高度な推論機能を得た。