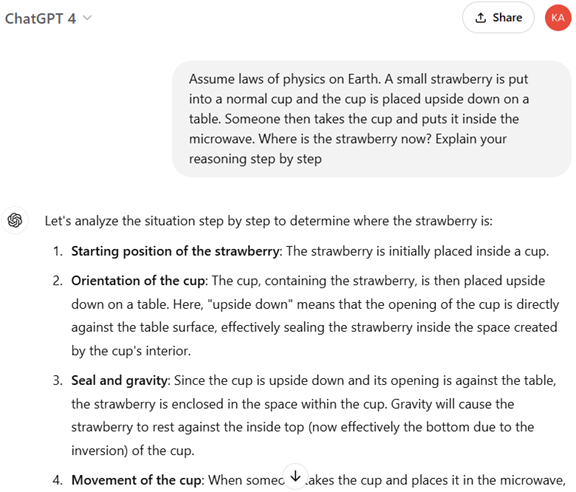
Googleは生成AIモデルの最新版「Gemini 2.0」をリリースした。Gemini 2.0は高性能なモデルであることに加え、AIエージェントを構成するための基礎技術となる。AIエージェントとは知的なAIモデルで、複雑なタスクを自律的に実行し、人間の作業を代行する存在となる。Googleは人間のように自立的に行動するAIエージェントの研究開発を重点的に進めており、この技術を人間レベルのインテリジェンスを持つAGI(Artificial General Intelligence)に拡張するとのビジョンを示した。

| 出典: Google |
Gemini 2.0の概要
Gemini 2.0はシリーズの最新モデルで、性能が向上したことに加え、マルチモダル機能が強化された。オーディオやイメージやビデオを読み込むことができるだけでなく、これらを生成する機能が付加された。また、Gemini 2.0は検索エンジン(Google Search)やマップ(Google Maps)を操作することができ、人間のようにツールを使う機能が実装された。
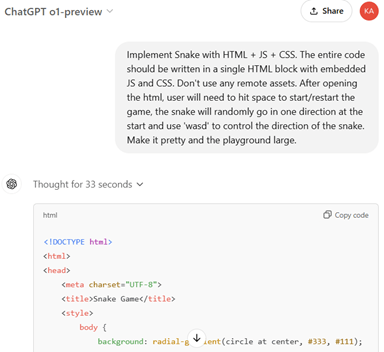
Gemini 2.0 Flashを投入
今回の発表では「Gemini 2.0 Flash」が公開され、一般に利用することができるようになった。開発者はクラウド「Google Vertex AI」からAPI経由でこれを利用する。また、ブラウザーからは「2.0 Flush Experimental」として対話形式で利用できる(下の写真)。これは正式版の前のプレビュー版であるが最新機能を体験できる。

| 出典: Google |
Gemini 2.0 Flashの特性
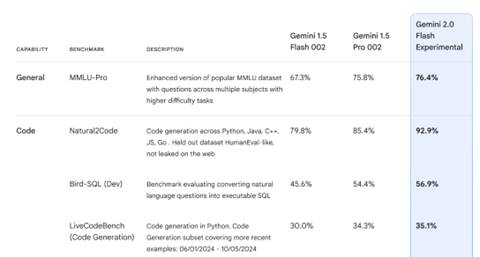
Gemini 2.0 Flashは軽量モデルで、高速で稼働することに加え、マルチモダル機能が強化された。Flashは処理速度が速く、リアルタイムでの反応が要求されるアプリケーションで利用される。その代表がAIエージェントで、Flashはマルチモダルを読み込み、これを高速で処理することで、リアルタイムでの会話が可能となった。また、基本性能が大きく向上し、ハイエンドモデルである「Gemini 1.5 Pro」を上回り、Geminiシリーズの最高速モデルとなった(下の写真)。
| 出典: Google |
AIエージェント汎用モデル:Project Astra
GoogleはAIエージェントの汎用モデル「Project Astra」の最新版を公開した。Project Astraはスマートフォンに搭載されるAIエージェントで、カメラが撮影するビデオを入力とし、質問に会話形式で回答する。屋内や屋外で、スマホのカメラで撮影した映像についての質問にリアルタイムで回答する。公園に設置されている建造物について、「これは何か」と問いかけると、AIエージェントは「Eve Rothchildが制作した「My World and Your World」という作品である」と回答する(下の写真)。AIエージェントは入力されたビデオを瞬時に解析し、自然な対話で回答する。

| 出典: Google |
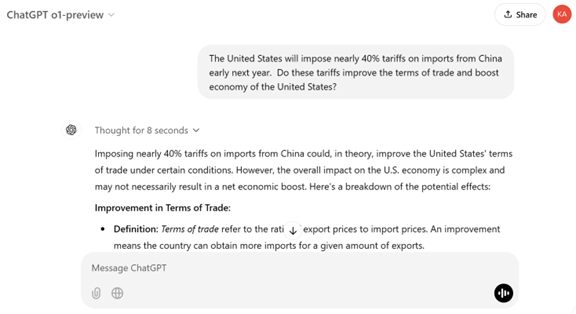
AIエージェント専用モデル:Project Mariner
Googleは特定のタスクに特化した機能を持つAIエージェント「Project Mariner」を公開した。Project MarinerはChromeブラウザーの拡張機能(Extension)として実装され、ウェブサイトで指示されたタスクを実行する。例えば、「Google Arts and Culture」のサイトでカラフルな絵を見つけるよう指示すると、AIエージェントはこのサイトにアクセスし、タスクを実行する。更に、Eコマースサイト「Etsy」でカラフルな絵の具を購買するように指示すると、それを実行し、商品を購入バスケットに入れる(下の写真)。但し、支払い処理のプロセスでは、人間の判断を仰ぎ、利用者が最終判断を下す。

| 出典: Google |
ウェアラブル向け基本ソフト:Android XR
Googleはウェアラブル向けの基本ソフト「Android XR」を発表した。これはヘッドセットやスマートグラス向けの基本ソフトで、ARやVRを融合したXR(Extended Reality)のプラットフォームとなる。Android XRにGemini 2.0が組み込まれ、これをXRグラスに搭載することで、ウェアラブルでAIエージェントを利用できる構造となる。GoogleはQualcomm及びSamsungと共同で開発し、Android XRはパートナー企業が開発するXRグラスに搭載される。また、Googleも独自のXRグラスを開発しており、AIエージェントが日常生活における秘書の役割を担う。市街地でレストランの場所を尋ねると、AIエージェントがXRグラスに道順やレストランの情報を表示し、目的地までナビゲーションする(下の写真)。

| 出典: Google |
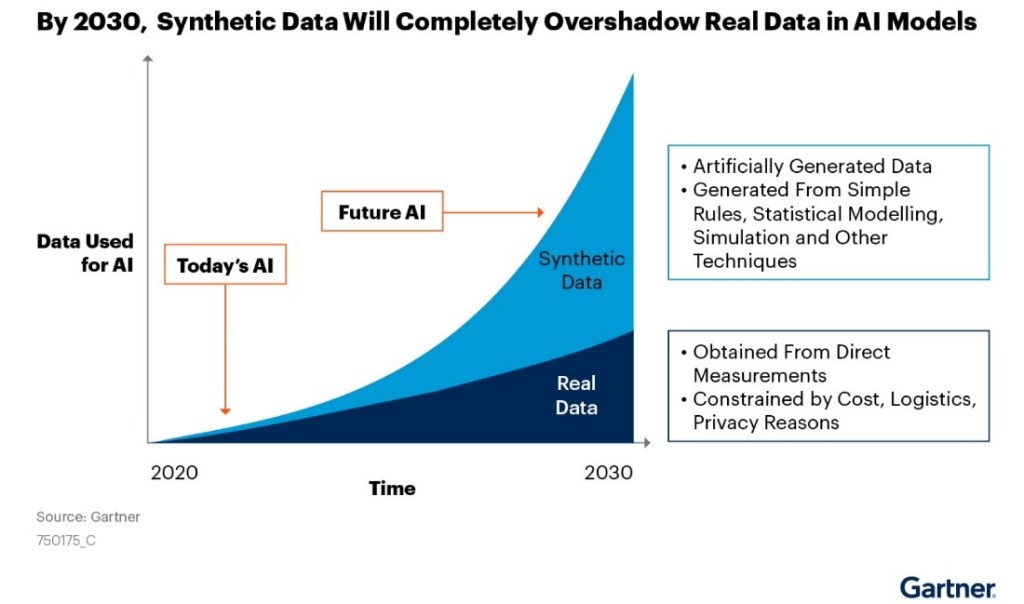
AIエージェントの時代に
生成AIはインテリジェンスを提供するプラットフォームで、この基盤で様々なアプリケーションが開発されている。その中で、人間に代わり作業を代行するAIエージェントに注目が集まっている。AIエージェントは従来のソフトウェアと異なり、人間が介在することなく自律的に業務を実行し、企業のビジネスプロセスを高度に自動化すると期待されている。Googleの他に、OpenAIやMetaがAIエージェントの開発を重点的に進めており、2025年は多彩なモデルが投入されることになる。