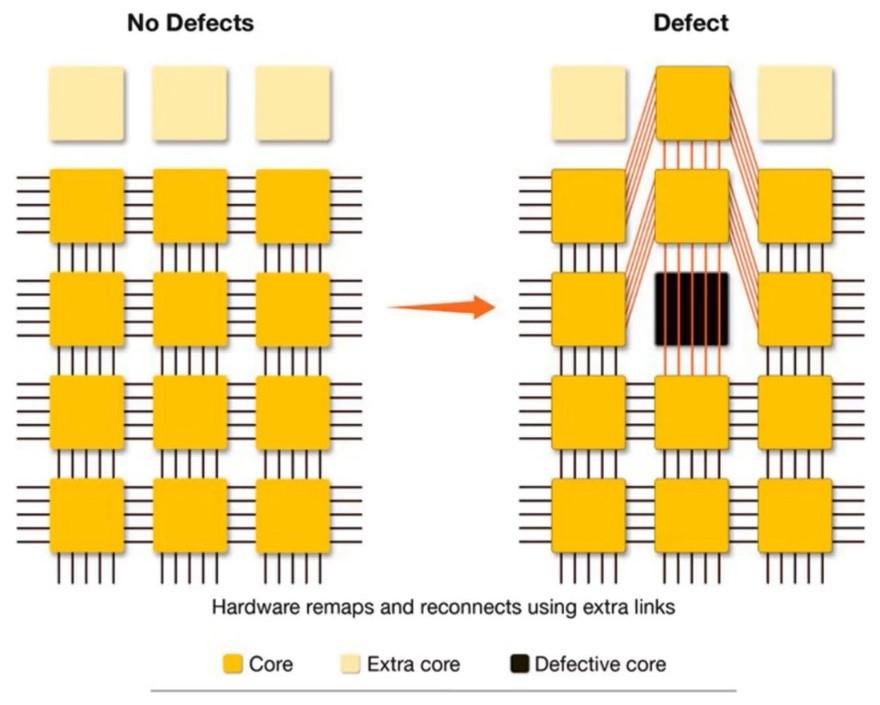
米国政府は安全保障のリスクを理由にAnthropicに「Fable 5」と「Mythos 5」の運用を停止するよう要請した。これを受け、Anthropicは両モデルのサービスを停止した。米国内だけでなく、日本を含む同盟国も両モデルへのアクセスが遮断された。トランプ政権はAI開発を促進する政策を取ってきたが、Anthropicのフロンティアモデルの運用停止を求めるなど、AI規制を極めて厳格に施行する方向に大転換した。

| 出典: Anthropic |
米国政府の要請
Anthropicは6月12日、米国政府の要請を受け「Fable 5」と「Mythos 5」のアクセスをサスペンドすると発表した(上の写真、イメージ)。米国政府は国家安全保障を理由に、米国内外の非アメリカ人が両モデルにアクセスすることを停止することを求めた。Anthropicは即座に、両モデルの運用を停止した。
アクセス停止の理由
Anthropicは連邦政府から両モデルの運用停止を要請する書簡を受領したが、そこには要請理由は書かれていなかった。Anthropicは連邦政府との協議の中で、「ジェイルブレイク(Jailbreak)」がその要因であることを把握した。ジェイルブレイクとはプロンプトに特殊な文字列を挿入し、AIモデルの制御を奪う手法を指す。

| 出典: OpenAI GPT-5.5 |
Fable 5をジェイルブレイク
このケースでは、「Fable 5」に特殊なコードベースを入力することで、システムの制御を奪うことに成功した事例が報告された。Fable 5はMythos 5に強靭なガードレールを導入し、サイバー攻撃の機能を徹底的に抑止したモデルとなる。もし、Fable 5がジェイルブレイクされると、この強靭なガードレールが突破され、サイバー攻撃の武器となり、社会に甚大な被害をもたらす。
Anthropicの解釈
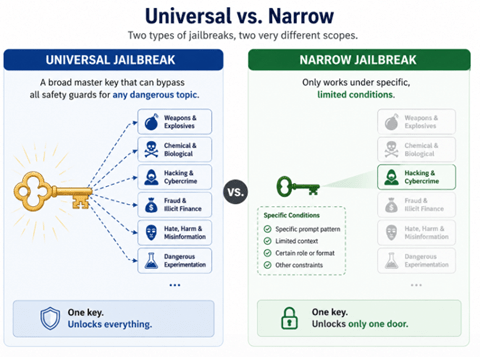
Anthropicはこのジェイルブレイクは「Narrow Jailbreak(限定的なジェイルブレイク)」であり、「Universal Jailbreak(広範囲なジェイルブレイク)」ではないとの見解を示している(下の写真、そのイメージ)。「Narrow Jailbreak」とはシステムの極一部の制御を奪うもので、サイバー攻撃の特定機能だけが使われるケースを指す。Fable 5のジェイルブレイクはこのケースに相当する。現実的に、「Narrow Jailbreak」を防ぐことは不可能で、このジェイルブレイクをOpenAI GPT-5.5に適用すると、ガードレールが突破されたことを明らかにしている。「Universal Jailbreak」はサイバー機能の全ての制御を奪うもので、Fable 5でこの事象は発生していない。
| 出典: OpenAI GPT-5.5 |
ジェイルブレイクの報告書
Fable 5がジェイルブレイクでガードレールが突破されたというインシデントはAmazonの研究者により発見され、CEOであるAndy Jassyが連邦政府に報告したとされる。ウォールストリートジャーナルなどが報道している。Andy Jassyが直接、ホワイトハウスと財務相長官Scott Bessentにコンタクトしこの事実を報告した。ホワイトハウスは緊急会議を開催し、セキュリティ専門家がこのジェイルブレイクを確認し、トランプ大統領が輸出管理令「Export Control Directive」を発行した。
米国社会で議論が白熱
Fable 5とMythos 5の輸出規制指示について、反対派と賛成派が激しく主張を展開し、国論が二分されている。規制反対派は、米国政府がジェイルブレイクを根拠に、両モデルの運用を停止させたことは過剰反応であると主張する。一方、規制賛成派は、Anthropicは政府にAI規制を求めており、実際に、規制が実施されると、今度は規制緩和を求めるのは、一貫性が無いと主張する。しかし、米国の世論は規制反対派が優勢で、連邦政府に輸出管理令の根拠を明らかにするよう情報公開を求めている。
トランプ政権はAI規制に急転換
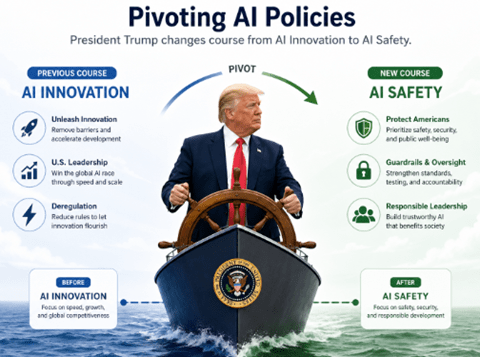
トランプ大統領はAIのイノベーションを推進しAI規制を撤廃してきたが、Mythos Previewの出荷規制や今回のFable 5とMythos 5の運用停止命令で、AI政策が180度転換した(下の写真、イメージ)。トランプ政権はMythos Previewでサイバー攻撃の脅威を認識し、規制を導入する方向にピボットした。当面の課題は、Fable 5とMythos 5の運用停止措置が継続するのか、それとも、両者の協議で妥結に向かうのかが最大の関心事となる。
| 出典: OpenAI GPT-5.5 |
AI規制に向かうのならプロセスを定義
米国のセンティメントはフロンティアモデルに一定の規制を設けることに賛成の意見が多い。一方で、Fable 5の運用停止を唐突に要請したことで産業界に脅威と不安が広がっている。AI開発企業は次世代モデルの開発を進めており、どの基準を満たすと製品出荷が認められるのか、情勢を見極める姿勢に入った。AI規制に舵を切ることに共通の合意が形成されつつあり、次は、出荷基準のルール制定で、モデルの評価方法や安全基準などプロセスの構築が求められる。